深く解析するIPFS:次世代インターネットの基盤プロトコル

 IPFSは、世界のどこにでもあるノードを介してコンテンツにアクセスできるピアツーピア(P2P)ストレージネットワークであり、これらのノードは情報を伝達したり、情報を保存したり、またはその両方を行うことができます。
IPFSは、世界のどこにでもあるノードを介してコンテンツにアクセスできるピアツーピア(P2P)ストレージネットワークであり、これらのノードは情報を伝達したり、情報を保存したり、またはその両方を行うことができます。著者:Xiang,W3.Hitchhiker
IPFSとは何か
分散型インターネット(web3.0)に力を与える。
ネットワークをスケーラブルで弾力的かつよりオープンな方法で人類の知識を保存し、発展させるためのピアツーピアのハイパーメディアプロトコル。
IPFSは、ファイル、ウェブサイト、アプリケーション、データを保存しアクセスするための分散システムです。
HTTP
「IPFS」は「HTTP」と呼ばれるものに対応しており、これはあなたが比較的よく知っているかもしれません。インターネットで百度の検索ページを開くとき、それは見たままのものです。
ウェブのアプリケーション層プロトコルはハイパーテキスト転送プロトコル(HTTP)であり、これは従来のウェブの中心です。HTTPは2つのプログラムによって実現されます:クライアントプログラムとサーバープログラム。クライアントプログラムとサーバープログラムは異なるエンドシステムで実行され、HTTPを介してセッションを交換します。HTTPはこれらのデータの構造とクライアントとサーバーが相互作用する方法を定義します。
ウェブページはオブジェクトで構成されており、オブジェクトは単なるファイル、例えばHTMLファイル、JPEG画像、または短いビデオクリップのようなファイルであり、これらはURLアドレスでアドレス指定できます。ほとんどのウェブページには基本的なHTMLファイルといくつかの参照オブジェクトが含まれています。
HTTPはウェブクライアントがウェブサーバーにウェブページをリクエストする方法と、サーバーがクライアントにウェブページを送信する方法を定義します。
ブラウザの仕事は、HTTPプロトコルとフロントエンドコードを実行および解析し、コンテンツを表示することです。クエリを送信する際には、通常、ウェブ側がデータベースをクエリし、結果をリクエスト元、つまりブラウザに返し、ブラウザがそれを表示します。
HTTPプロトコルの欠点
現在、私たちが使用しているインターネットはすべてHTTPまたはHTTPSプロトコルの下で動作しています。HTTPプロトコルはハイパーテキスト転送プロトコルであり、ワールドワイドウェブサーバーからローカルブラウザにハイパーテキストを転送するためのプロトコルです。1990年に提案されて以来、32年が経過し、現在のインターネットの爆発的な成長に大きく貢献し、インターネットの繁栄を実現しました。
しかし、HTTPプロトコルはC/Sアーキテクチャに基づくインターネット通信プロトコルであり、バックボーンネットワークの中央集権的な運用メカニズムに基づいているため、多くの欠点があります。
- インターネット上のデータは、ファイルが削除されたりサーバーが閉鎖されたりすることによって、しばしば永久に消去されます。ある統計によると、現在のインターネット上のウェブページの平均保存寿命は約100日であり、「404エラー」が表示されるサイトをよく見かけます。
- バックボーンネットワークの運用効率が低く、コストが高いです。HTTPプロトコルを使用する場合、毎回中央集権的なサーバーから完全なファイルをダウンロードする必要があり、速度が遅く効率が悪いです。
- バックボーンネットワークの同時接続メカニズムがインターネットのアクセス速度を制約します。このような中央集権的なバックボーンネットワークのモデルは、高い同時接続がある場合にネットワークアクセスの混雑を引き起こします。
- 現在のHTTPプロトコルの下では、すべてのデータがこれらの中央集権的なサーバーに保存されており、インターネットの巨人たちは私たちのデータに対して絶対的な管理権と解釈権を持っています。さまざまな規制、ブロック、監視は、ある程度、革新と発展を大きく制限しています。
- コストが高く、攻撃を受けやすいです。HTTPプロトコルを支えるために、大量のトラフィックを持つ企業(例えば百度、テンセント、アリババなど)は、サーバーとセキュリティリスクを維持するために多くのリソースを投入し、DDoS攻撃などを防ぐ必要があります。バックボーンネットワークは、戦争、自然災害、中央サーバーのダウンなどの要因によって、インターネット全体のサービスが中断される可能性があります。
IPFSの解決策
- IPFSはファイルの履歴バージョンの遡及機能を提供し、ファイルの履歴バージョンを簡単に確認でき、データは削除できず、永久に保存されます。
- IPFSはコンテンツアドレッシングに基づくストレージモデルであり、同じファイルは重複して保存されず、余分なリソースを圧縮し、ストレージスペースを解放し、データストレージコストを削減します。P2P方式でダウンロードする場合、帯域幅の使用コストを約60%節約できます。
- IPFSはP2Pネットワークに基づいており、データを保存する複数のソースがあり、複数のノードからデータを同時にダウンロードできます。
- 中央集権的な管理や制限が難しい分散型ネットワーク上に構築されたIPFSは、インターネットをよりオープンにします。
- IPFSの分散ストレージは、中央のバックボーンネットワークへの依存を大幅に減少させます。
簡潔に言えば:
HTTPは中央集権的なサーバーに依存し、攻撃を受けやすく、アクセス量が急増するとサーバーがダウンしやすく、ダウンロード速度が遅く、ストレージコストが高いです。
一方、IPFSは分散ノードであり、より安全でDDoS攻撃を受けにくく、バックボーンネットワークに依存せず、ストレージコストを削減し、ストレージスペースが大きく、ダウンロード速度が速く、ファイルの履歴バージョンを確認でき、理論的には永久に保存できます。
新しい技術が古い技術に取って代わる理由は、主に2つです:
第一に、システムの効率を向上させること;
第二に、システムのコストを削減すること。
IPFSはこの2つを実現しました。


IPFSのチームは開発時に高度にモジュール化された統合方式を採用し、積み木のようにプロジェクト全体を開発しました。プロトコルラボチームは2015年に設立され、2017年までの間にIPLD、LibP2P、Multiformatsの3つのモジュールの開発に取り組みました。これらはIPFSの基盤にサービスを提供します。
Mutiformatsは、ハッシュ暗号アルゴリズムと自己記述方式(値から生成方法がわかる)の集合であり、SHA1、SHA256、SHA512、Blake3Bなど6つの主流の暗号方式を持ち、nodeIDやフィンガープリンターのデータ生成を暗号化し記述します。
LibP2PはIPFSの核心の中の核心であり、さまざまな伝送層プロトコルや複雑なネットワークデバイスに直面し、開発者が迅速に利用可能なP2Pネットワーク層を構築するのを助け、迅速かつコストを節約します。これがIPFS技術が多くのブロックチェーンプロジェクトに好まれる理由です。
IPLDは実際には変換ミドルウェアであり、既存の異種データ構造を統一された形式に変換し、異なるシステム間でのデータ交換と相互運用を容易にします。現在、IPLDがサポートするデータ構造には、ビットコインやイーサリアムのブロックデータが含まれ、IPFSやIPLDもサポートしています。これがIPFSがブロックチェーンシステムに人気の理由の一つであり、そのIPLDミドルウェアは異なるブロック構造を標準化して伝達し、開発者に高い成功率の基準を提供し、パフォーマンス、安定性、バグを心配する必要がありません。
IPFSの利点
- Kademlia、BitTorrent、Gitなどの理念を融合させたハイパーメディア配信プロトコル
- 中央ノードの失効を回避し、検閲や管理のない完全な分散型のピアツーピア伝送ネットワーク
- インターネットの明日へ進む ------ 新しいブラウザはすでにIPFSプロトコルをデフォルトでサポートしています(Brave、Opera)。従来のブラウザは、
https://ipfs.ioなどの公共IPFSゲートウェイにアクセスするか、IPFSコンパニオン拡張機能をインストールして、IPFSネットワークに保存されたファイルにアクセスできます。 - 次世代コンテンツ配信ネットワークCDN ------ ローカルノードにファイルを追加するだけで、世界中の人々がキャッシュフレンドリーなコンテンツハッシュアドレスとBitTorrentネットワークの帯域幅配信を通じてファイルを取得できます。
- 強力なオープンソースコミュニティをバックボーンに持ち、完全な分散アプリケーションとサービスを構築するための開発者ツールセット
IPFSは、システム内でファイルがどのように保存、インデックス付け、転送されるかを定義し、アップロードされたファイルを特定のデータ形式に変換して保存します。同時に、IPFSは同じファイルにハッシュ計算を行い、そのユニークなアドレスを決定します。したがって、どのデバイスでも、どこにいても、同じファイルは同じアドレスを指します(URLとは異なり、このアドレスはネイティブであり、暗号アルゴリズムによって保証されており、変更することも変更する必要もありません)。その後、ファイルシステムを介してネットワーク内のすべてのデバイスを接続し、IPFSシステムに保存されたファイルを世界中のどこでも迅速に取得でき、ファイアウォールの影響を受けません(ネットワークプロキシは不要です)。したがって、根本的に言えば、IPFSはWEBコンテンツの配信メカニズムを変更し、去中心化を実現します。
IPFSの動作原理
IPFSはピアツーピア(p2p)ストレージネットワークです。世界のどこにでもあるノードを介してコンテンツにアクセスでき、これらのノードは情報を伝達したり、情報を保存したり、またはその両方を行うことがあります。IPFSは、位置ではなくコンテンツアドレスを使用して要求されたコンテンツを見つける方法を知っています。
IPFSの3つの基本原則を理解する:
- コンテンツアドレッシングによるユニークな識別
- 有向非巡回グラフ(DAG)によるコンテンツリンク
- 分散ハッシュテーブル(DHT)によるコンテンツ発見
これらの3つの原則は相互に依存しており、IPFSエコシステムを構築しています。コンテンツアドレッシングとコンテンツのユニークな識別から始めましょう。
コンテンツアドレッシングとコンテンツのユニークな識別
IPFSはコンテンツアドレッシングを使用して、位置ではなくコンテンツに基づいてコンテンツを識別します。コンテンツに基づいてアイテムを検索することは、誰もが常に行っていることです。
例えば、図書館で本を探すとき、通常は書名で探します。それはコンテンツアドレッシングです。なぜなら、あなたはそれが何であるかを尋ねているからです。
もし位置アドレッシングを使用してその本を探すと、あなたはその位置を使って探すことになります:「私は2階の本が欲しい、3番目の本棚、4段目、左から数えて4冊目の本。」
もし誰かがその本を移動させたら、あなたは不運です!
インターネットやあなたのコンピュータにもこの問題があります!現在、コンテンツは位置で検索されています。例えば:
https://en.wikipedia.org/wiki/Aardvark/Users/Alice/Documents/term_paper.docC:\Users\Joe\My Documents\project_sprint_presentation.ppt
対照的に、IPFSプロトコルを使用する各コンテンツにはコンテンツ識別子、すなわちCIDがあります。ハッシュはそのコンテンツに対してユニークであり、元のコンテンツと比較して短く見えるかもしれません。
多くの分散システムはハッシュを使用してコンテンツアドレッシングを行い、コンテンツを識別するだけでなく、リンクすることもできます。コードのコミットをサポートするものから、暗号通貨を運営するブロックチェーンまで、すべてがこの戦略を利用しています。しかし、これらのシステムの基盤となるデータ構造は、必ずしも相互運用可能ではありません。
CID(コンテンツ識別子)
CID仕様はIPFSに由来し、現在は多くのフォーマットで存在し、IPFS、IPLD、libp2p、Filecoinを含む広範なプロジェクトをサポートしています。私たちはこのコース全体でいくつかのIPFSの例を共有しますが、このチュートリアルはCID自体の分析に関するものであり、すべての分散情報システムがコンテンツを参照するためのコア識別子として使用します。
コンテンツ識別子またはCIDは、自己記述的なコンテンツアドレッシング識別子です。これはコンテンツがどこに保存されているかを示すのではなく、コンテンツ自体に基づいてアドレスを形成します。CID内の文字数は、基礎となるコンテンツの暗号ハッシュに依存し、コンテンツ自体のサイズには依存しません。IPFS内のほとんどのコンテンツはハッシュsha2-256を使用しているため、あなたが遭遇するほとんどのCIDは同じサイズ(256ビット、32バイト相当)になります。これにより、特に複数のコンテンツを扱う際に管理が容易になります。
例えば、IPFSネットワークに土豚の画像を保存した場合、そのCIDは次のようになります: QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
以前に示したuniswapのIPFSリンク:

CIDを作成する最初のステップは、入力データを変換し、暗号アルゴリズムを使用して任意のサイズの入力(データまたはファイル)を固定サイズの出力にマッピングすることです。この変換はハッシュデジタルフィンガープリンターまたは単にハッシュ(デフォルトでsha2-256を使用)と呼ばれます。
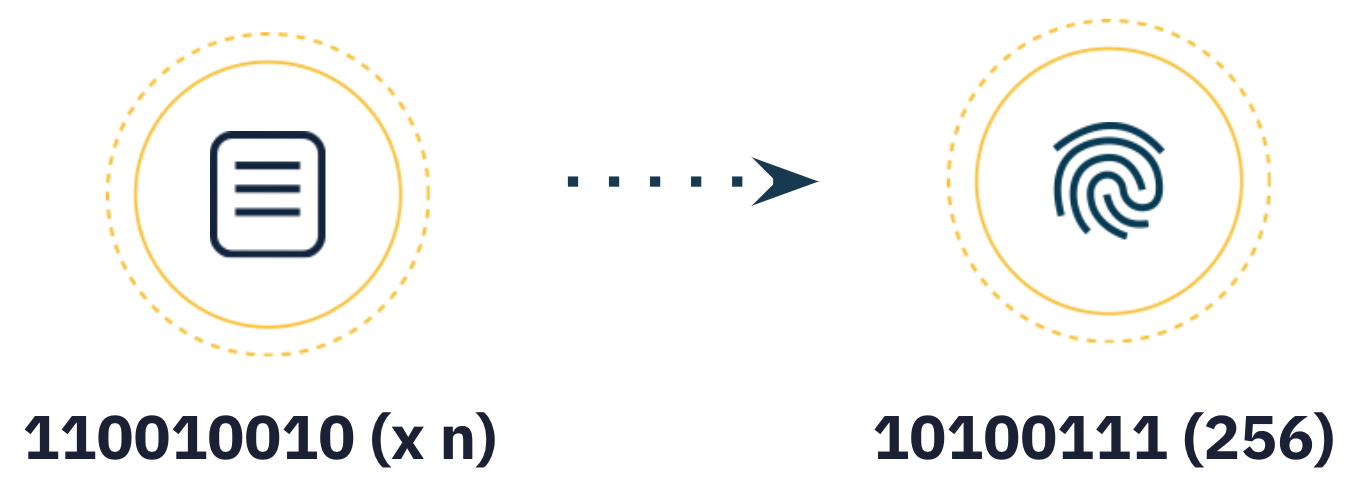
使用する暗号アルゴリズムは、次の特性を持つハッシュ値を生成する必要があります:
- 決定性:同じ入力は常に同じハッシュを生成する必要があります。
- 無関係性:入力データの小さな変化は、完全に異なるハッシュを生成する必要があります。
- 単方向性:ハッシュ値から入力データを逆推測することは不可能です。
- ユニーク性:特定のハッシュを生成できるファイルは1つだけです。
土豚の画像の単一のピクセルを変更すると、暗号アルゴリズムは画像に対して完全に異なるハッシュを生成します。
コンテンツアドレスを使用してデータを取得する際、私たちはそのデータの期待されるバージョンを見ることができることを保証します。これは従来のウェブの位置アドレッシングとは完全に異なり、従来のウェブでは、特定のアドレス(URL)上のコンテンツは時間とともに変化します。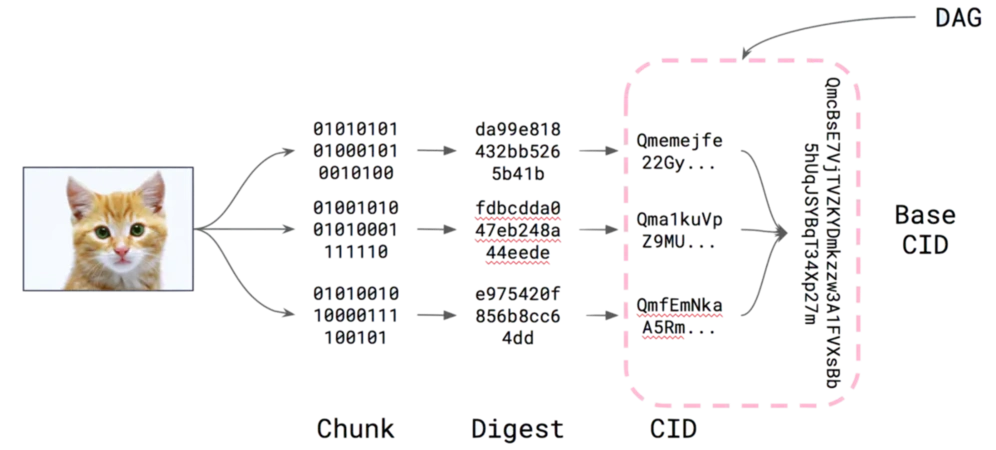

CIDの構造
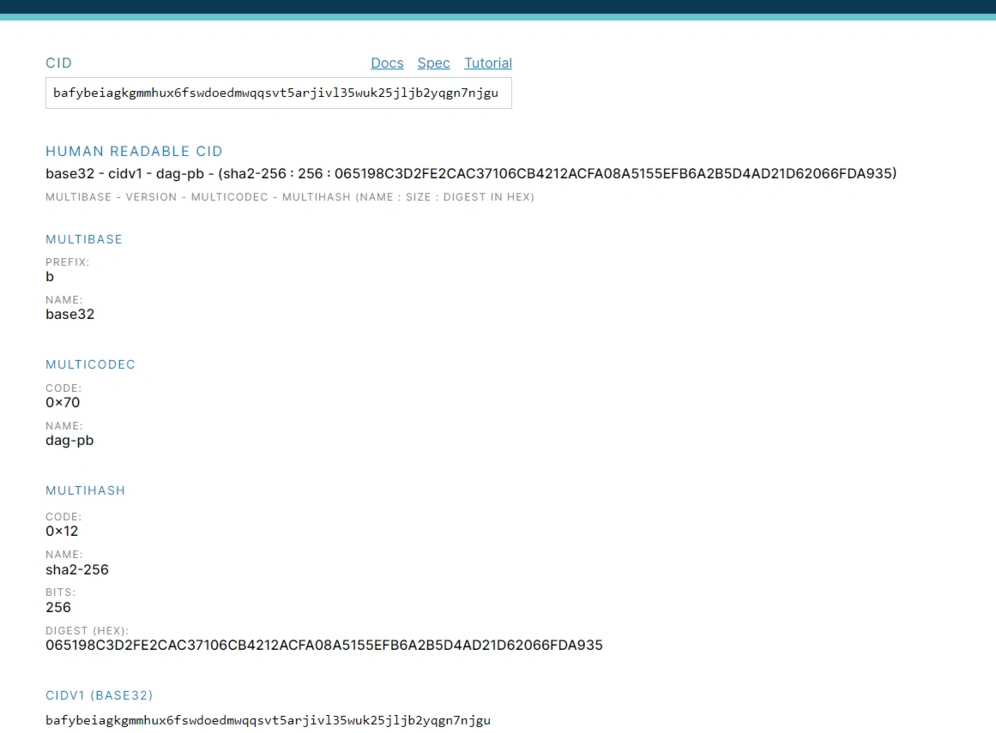

Multiformats
MultiformatsはIPFSエコシステム内で主にアイデンティティの暗号化とデータの自己記述を担当しています。
Multiformatsは未来の安全システムのプロトコルの集合であり、自己記述フォーマットはシステムが相互に協力し、アップグレードできることを可能にします。
Multiformatsプロトコルには次のプロトコルが含まれています:
multihash - 自己記述ハッシュ
multiaddr - 自己記述ネットワークアドレス
multibase - 自己記述基エンコーディング
multicodec - 自己記述シリアル化
multistream - 自己記述ストリームネットワークプロトコル
multigram (WIP) - 自己記述グループネットワークプロトコル
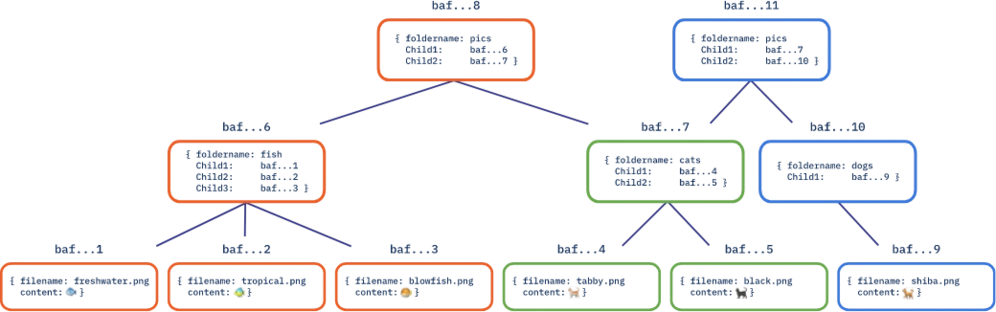
コンテンツリンク 有向非巡回グラフ(DAG)
Merkle DAGはCIDの可分配性を継承しています。DAGにコンテンツアドレッシングを使用すると、それらの配信にいくつかの興味深い影響を与えます。まず、もちろん、DAGを持つ人は誰でもそのDAGの提供者として機能できます。第二に、DAGとしてエンコードされたデータを取得する際、例えばファイルディレクトリの場合、私たちはこの事実を利用してノードのすべての子ノードを並行して取得でき、これらは多くの異なる提供者から来る可能性があります!
三つ目は、ファイルサーバーは集中型データセンターに限定されず、私たちのデータのカバレッジを広げます。最後に、DAGの各ノードには独自のCIDがあるため、それが表すDAGは、それ自体が埋め込まれているDAGとは独立して共有および取得できます。
検証可能性
ファイルをバックアップした後、数ヶ月後にその2つのファイルまたはディレクトリを見つけて、それらの内容が同じかどうかを知りたいと思ったことはありませんか?あなたは各バックアップのためにMerkle DAGを計算することができ、ファイルを比較する手間を省くことができます:ルートディレクトリのCIDが一致すれば、どれを安全に削除できるかがわかり、ハードドライブのスペースを解放できます!
可分配性
例えば、大規模なデータの配信。従来のウェブネットワークでは:
- 共有ファイルの開発者はサーバーとその関連費用を維持する責任があります。
- 同じサーバーが世界中のリクエストに応答する可能性が高いです。
- データ自体は単一のファイルとしてアーカイブされ、単一の方法で配布されます。
- 同じデータの代替供給者を見つけるのが難しいです。
- データは大きな塊であり、単一の供給者から直列にダウンロードする必要があります。
- 他の人がデータを共有するのが難しいです。
Merkle DAGはこれらすべての問題を軽減するのに役立ちます。データをコンテンツアドレッシングのDAGに変換することによって:
- 望む人は誰でもファイルの送受信を手伝うことができます。
- 世界中のノードがデータサービスに参加できます。
- DAGの各部分には独自のCIDがあり、独立して配布できます。
- 同じデータの代替供給者を見つけるのが簡単です。
- DAGを構成するノードは小さく、多くの異なる供給者から並行してダウンロードできます。
これらすべてが重要なデータのスケーラビリティに寄与します。
重複データ削除
例えば、ウェブページを閲覧する場合!誰かがブラウザを使用してウェブページにアクセスすると、ブラウザはまずそのページに関連するリソース(画像、テキスト、スタイルなど)をダウンロードする必要があります。実際、多くのウェブページは非常に似ているように見え、同じテーマを使用しているだけで、他はわずかに異なります。ここで多くの冗長性が生じます。

ブラウザが十分に最適化されている場合、同じコンポーネントを何度もダウンロードするのを避けることができます。ユーザーが新しいウェブサイトにアクセスするたびに、ブラウザはそのDAG内で異なる部分に対応するノードをダウンロードするだけで、以前にダウンロードした他の部分を再度ダウンロードする必要はありません!(WordPressテーマ、Bootstrap CSSライブラリ、または一般的なJavaScriptライブラリを考えてみてください)
分散ハッシュテーブル(DHT)
分散ハッシュテーブル(DHT)は、キーを値にマッピングするための分散システムです。IPFSでは、DHTはコンテンツルーティングシステムの基本コンポーネントとして使用され、ディレクトリとナビゲーションシステムの交差点として機能します。これは、ユーザーが探しているコンテンツを、マッチするコンテンツを保存しているピアノードにマッピングします。これは、誰がどのデータを持っているかを保存する巨大な表として考えることができます。
Libp2p
libp2pはモジュール化されたネットワークスタックであり、 IPFSから独立したプロジェクトに進化しました。ポルカも使用しており、eth2.0も部分的に使用しています。
libp2pが分散型ネットワークの重要な部分である理由を説明するために、私たちは一歩引いてその起源を理解する必要があります。libp2pの初期実装は、ピアツーピアファイル共有システムであるIPFSに始まりました。まず、IPFSが解決しようとしているネットワークの問題を探ってみましょう。
ネットワーク
ネットワークは非常に複雑なシステムであり、自身のルールと制限を持っているため、これらのシステムを設計する際には多くの状況やユースケースを考慮する必要があります:
- ファイアウォール:あなたのノートパソコンには、特定の接続をブロックまたは制限するファイアウォールがインストールされているかもしれません。
- NAT:あなたの家庭のWiFiルーターにはNAT(ネットワークアドレス変換)があり、ノートパソコンのローカルIPアドレスを外部ネットワークが接続できる単一のIPアドレスに変換します。
- 高遅延ネットワーク:これらのネットワークは接続速度が非常に遅く、ユーザーがコンテンツを見るまでに長い時間待たされます。
- 信頼性:世界中に多くのネットワークが分散しており、多くのユーザーがしばしば遅いネットワークに遭遇し、ユーザーに良好な接続を提供するための強力なシステムがありません。接続が頻繁に切断され、ユーザーのネットワークシステムの質が悪く、ユーザーに必要なサービスを提供できません。
- ローミング:モバイルアドレッシングは別のケースであり、ユーザーのデバイスが世界中の異なるネットワークをナビゲートする際に一意に発見可能であることを保証する必要があります。現在、これらは大量の調整ポイントと接続を必要とする分散システムで機能していますが、最良の解決策は去中心化です。
- 検閲:現在のネットワーク状態では、政府機関である場合、特定のウェブサイトドメインでウェブサイトをブロックするのは比較的簡単です。これは違法活動を阻止するのに役立ちますが、独裁政権がその人口のリソースへのアクセスを剥奪したいときには問題になります。
- 異なる属性を持つランタイム:周囲には多くのタイプのランタイムがあり、IoTデバイス(Raspberry Pi、Arduinoなど)が大量に採用されています。これらは限られたリソースで構築されているため、これらのランタイムは通常、異なるプロトコルを使用しており、これらのランタイムに多くの仮定をしています。
- 革新が非常に遅い:大量のリソースを持つ最も成功した企業でさえ、新しいプロトコルを開発し展開するのに数十年かかることがあります。
- データプライバシー:消費者は最近、ユーザーのプライバシーを尊重しない企業に対してますます懸念を抱いています。
P2Pプロトコルの現在の問題
ピアツーピア(P2P)ネットワークは、インターネットの概念から考案され、重大な自然災害や人為的災害によってピアノードがネットワークから切断されても正常に機能する弾力性のあるネットワークを作成する方法として考えられています。これにより、人々は通信を続けることができます。
P2Pネットワークは、ビデオ通話(例えばSkype)からファイル共有(例えばIPFS、Gnutella、KaZaA、eMule、BitTorrent)まで、さまざまなユースケースに使用できます。
基本概念
ピア - 去中心化ネットワークの参加者。ピアノードはアプリケーション内で同等の権限と能力を持つ参加者です。IPFSでは、ノートパソコンでIPFSデスクトップアプリケーションをロードすると、あなたのデバイスは去中心化ネットワークIPFS内のピアノードになります。
ピアツーピア(P2P) - 分散ネットワークで、ワークロードがピアノード間で共有されます。したがって、IPFSでは、各ピアノードが他のピアノードと共有するためのファイルの全部または一部をホストする可能性があります。ノードがファイルをリクエストすると、そのファイルのブロックを持つノードは、リクエストされたファイルを送信することに参加できます。その後、データをリクエストするノードは、他のノードとデータを共有できます。
IPFSは、現在および過去のネットワークアプリケーションや研究からインスピレーションを得て、P2Pシステムを改善しようとしています。学術界には、これらの問題のいくつかを解決する方法を提供する多くの科学論文がありますが、研究は初期の結果を生み出しましたが、使用および調整可能なコード実装が不足しています。
既存のP2Pシステムのコード実装は本当に見つけるのが難しく、実際に存在する場合でも、次の理由から再利用または再調整が難しいことがよくあります:
- ファイルが不十分または存在しない
- 制限的なライセンスまたはライセンスが見つからない
- 10年以上前に最後に更新された非常に古いコード
- 連絡先がない(連絡できるメンテナンス担当者がいない)
- クローズドソース(プライベート)コード
- 廃止された製品
- 仕様が提供されていない
- 使いやすいAPIが公開されていない
- 実装が特定のユースケースに過度に結合されている
- 将来のプロトコルのアップグレードに使用できない
より良い方法が必要です。主要な問題が相互運用性であることを考えると、IPFSチームはすべての現在の解決策を統合し、革新を促進するプラットフォームを提供するためのより良い方法を考案しました。新しいモジュール化システムは、将来の解決策をネットワークスタックにシームレスに統合できるようにします。
libp2pはIPFSのネットワークスタックですが、IPFSから抽出され、独立した一流のプロジェクトおよびIPFSの依存プロジェクトとなりました。
このようにして、libp2pはIPFSに依存せずにさらに発展し、独自のエコシステムとコミュニティを獲得できます。IPFSはlibp2pの多くのユーザーの1つに過ぎません。
これにより、各プロジェクトは自分の目標にのみ集中できます:
IPFSはコンテンツアドレッシング、つまりネットワーク内の任意のコンテンツを見つけ、取得し、検証することにより重点を置いています。
libp2pはプロセスアドレッシング、つまりネットワーク内の任意のデータ転送プロセスを見つけ、接続し、検証することに重点を置いています。では、libp2pはどのようにそれを実現しているのでしょうか?
答えは:モジュール化です。


libp2pは、ネットワークスタックを構成できる特定の部分を特定しました:


多言語実装で、7つの開発言語をサポートし、libp2pのJavaScript実装はブラウザやモバイルブラウザでも使用できます!これは非常に重要で、アプリケーションがデスクトップやモバイルデバイスでlibp2pを実行できるようにします。


アプリケーション
 リスク警告
リスク警告 リスク警告
リスク警告