

















Detailed Explanation of Celestia Architecture and the Future of the Modular World

 Celestia is becoming one of the most important components of modular blockchains.
Celestia is becoming one of the most important components of modular blockchains.Original Author: RainandCoffee
Original Title: 《The Modular World》
Translation: Eva, Hu Tao, Chain Catcher
Preface
Back in 2019, when we (Maven11) invested in LazyLedger (now known as Celestia), the term "modular" had not yet become popular in blockchain design. Over the past year, modularity has been promoted by polynya, a multitude of L2 teams and individuals, and of course, the Celestia Labs team, which coined the term in its first LazyLedger blog post, relating to the decoupling of consensus and execution.
For this reason, we are pleased to present the latest overview of our investment in Celestia. This allows us to delve into the envisioned modular world, the various layers and protocols within such an ecosystem, and why we are so excited about the potential functionalities it offers.
Architecture
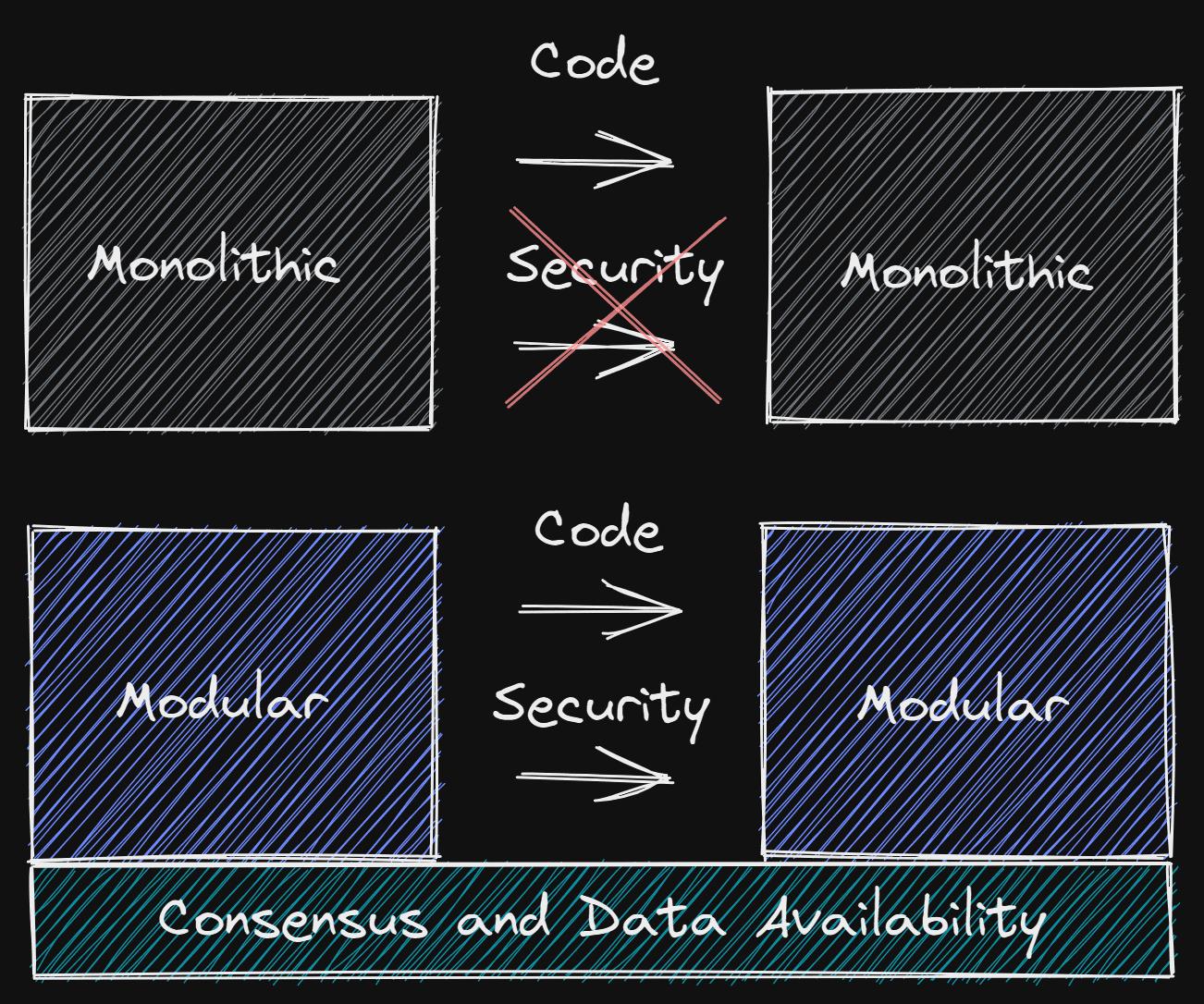
Currently, most operational public chains are monolithic entities. A monolithic chain refers to a single chain that independently handles data availability, settlement, and execution. At present, there are some variants of monolithic chains, particularly regarding Rollups on Ethereum and subnets on Avalanche, which have modular components. However, these are not truly modular blockchains in the strict sense.
Let’s define what we mean by "modular" to avoid misunderstandings. When we say modular, we refer to layers that are typically combined but are decoupled in fact. What does this mean? It means that one of the three components of the chain is decoupled, whether it be execution, consensus, or data availability. This means you can apply the term modular to rollups, as they only handle execution, while Ethereum manages everything else as a single entity.
In the case of Celestia, we can apply the term modular to it because it only handles data availability and consensus. Although it delegates settlement and execution to other layers, these layers are also modular as they only handle parts of the components themselves. This means that in terms of execution, we cannot call Ethereum a modular blockchain because the outsourcing of components only occurs with its current rollups. Nevertheless, Ethereum is still capable of handling execution on its own while allowing rollups to batch transactions off-chain. This means that in its current implementation, Ethereum remains a monolithic chain. However, Ethereum is still the ideal settlement layer and the most decentralized and secure smart contract chain.
Now, you might ask, what about Polkadot or Avalanche? In the case of Avalanche, it is not modular; it merely splits the network capable of handling all components of the blockchain. This means they are not modular scaling but are scaling by horizontally utilizing other monolithic chains. Polkadot's parachains handle execution, similar to rollups, while sending blocks to the relay chain for consensus and data availability. However, the relay chain still ensures the validity of transactions.
Over time, as monolithic chains grow, they lead to significant congestion and inefficiency. If we want to bring more people on board, it is fundamentally unfeasible to achieve all purposes using a single chain. This is because it imposes extremely high costs and delays on end users. This is precisely why we see more and more industry chains deciding to move towards splitting industry chains. We have all heard of the legendary Merge, which will transition Ethereum to a Proof-of-Stake chain. However, they also plan to eventually move towards sharding. Sharding is the horizontal splitting of a blockchain into multiple parts. These shards will purely handle data availability.
This, along with rollups, is how the Ethereum community plans to address its scalability issues. Now, are there other methods? Of course, we also see Avalanche moving towards a micro-modular future through Subnets, but as mentioned earlier, we wouldn’t classify it as fully modular.
To better understand the functionalities of various "modular" architectures, let’s try to visualize them to better grasp the differences.
Architecture Comparison
First, let’s look at the largest existing smart contract blockchain, Ethereum. Let’s see what their current architecture looks like and how the architecture will look with sharding enabled in the future.
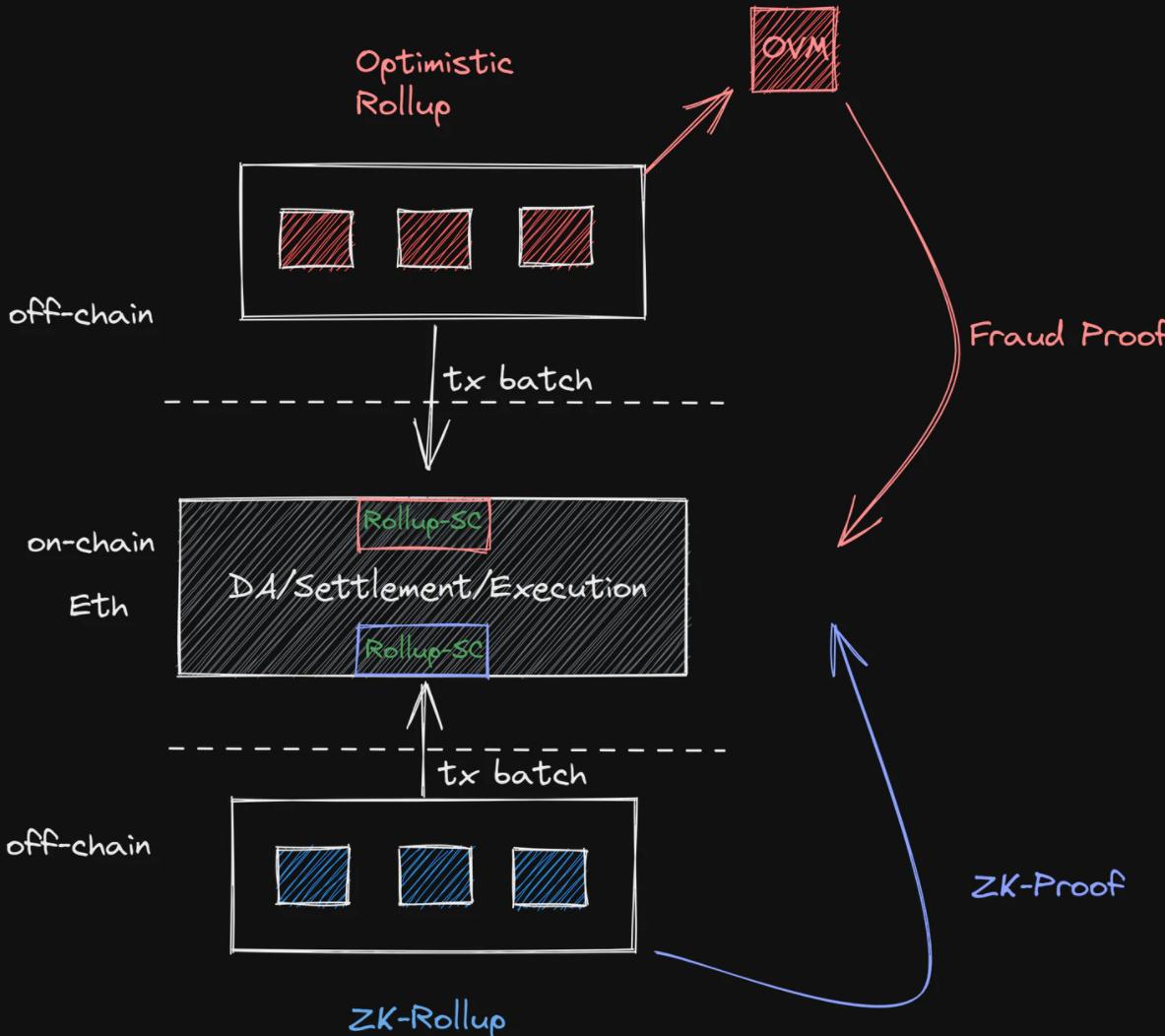
Current Ethereum Architecture (rollups)
Currently, Ethereum is capable of handling all components of the blockchain. However, it also offsets some execution to L2 rollups and then settles batched transactions on Ethereum. In the future, with sharding, the architecture will look like this:
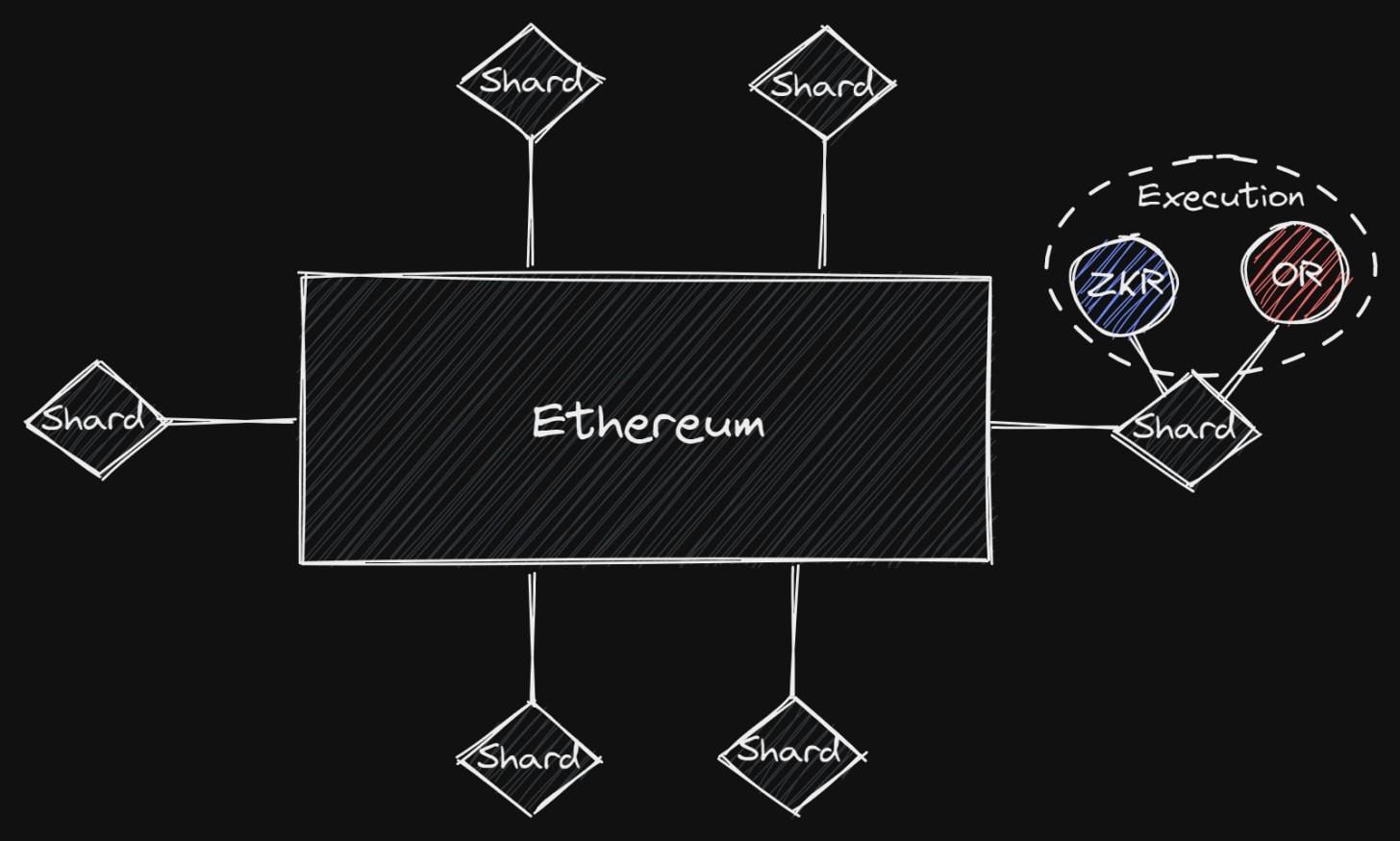
Ethereum after Sharding
This will turn Ethereum into a unified settlement layer, while the shards will handle data availability. This means that the shards will merely serve as the DA environment for rollups to submit data. On the shards, validators only need to store data for the shard they are validating, rather than the entire network. Sharding will ultimately allow you to run Ethereum on light nodes, similar to Celestia.
For Avalanche, their main scaling proposition is through single blockchains that can be easily created— their subnets. The Avalanche architecture looks something like this:
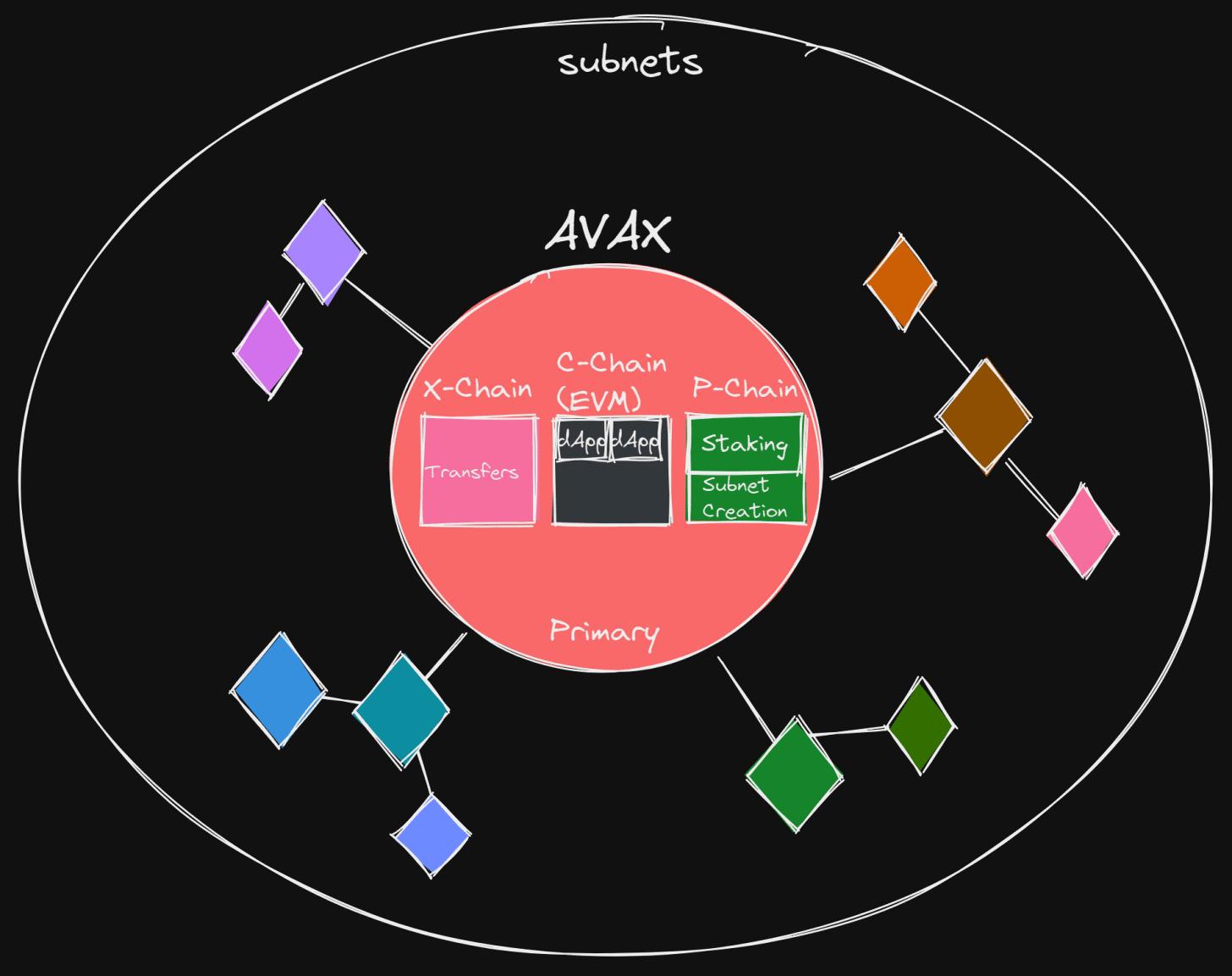
Avalanche with Subnets
Subnets are new validators that validate a group of blockchains. Each blockchain is validated by a subnet. All Avalanche subnets handle consensus, data availability, and execution independently. Each subnet will also have its own gas token, designated by the validators. An example of a currently running subnet is the DefiKingdoms subnet, which uses JEWEL as its gas token.
Before we continue to look at Celestia's architecture, let’s first take a look at Cosmos. Celestia largely draws from Cosmos and will interact with it extensively through IBC, as it is also built using the Cosmos SDK and Tendermint - Optimint version. The Cosmos architecture is quite different from other current architectures because it makes dApps applications of the blockchain itself rather than providing a virtual machine. This means a sovereign Cosmos SDK chain only needs to define the transaction types and state transitions it requires while relying on Tendermint as its consensus engine. The Cosmos chain splits the application part of the blockchain and connects it to the network (p2p) and consensus using ABCI. ABCI is the interface that connects the application part of the blockchain to the Tendermint state replication engine that provides consensus and networking mechanisms. Its architecture is generally propagated like this:
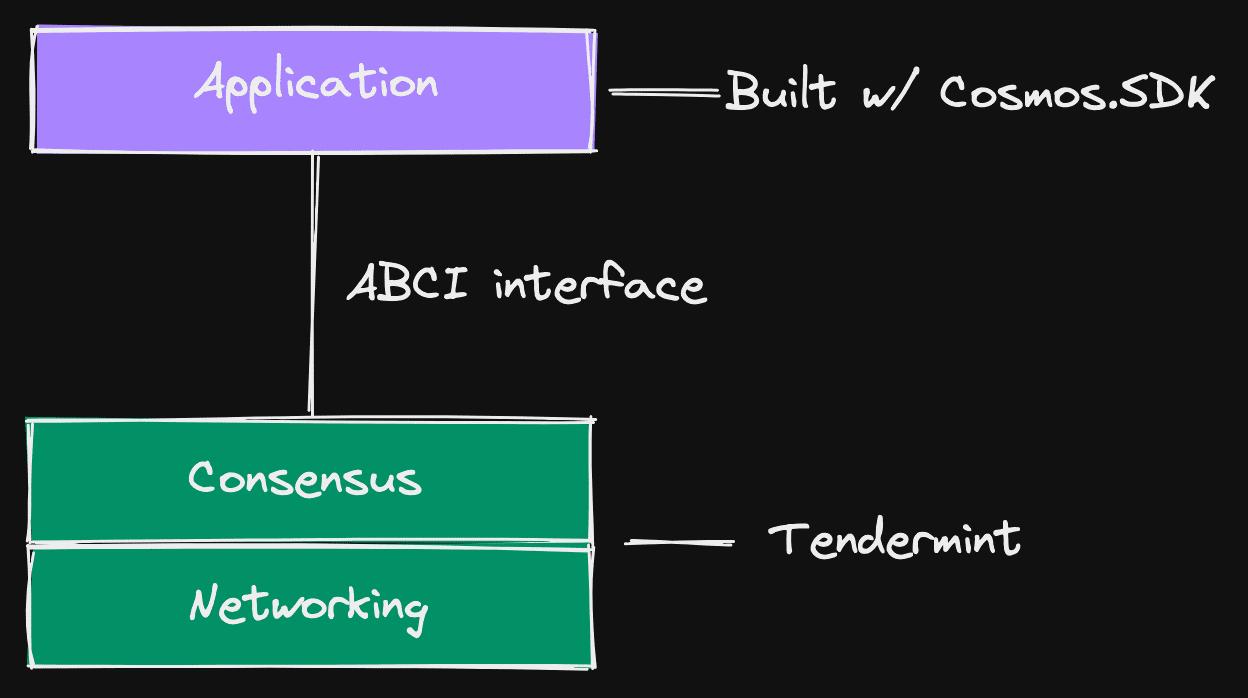
Cosmos Architecture
Now let’s see what Celestia's architecture will look like once the ecosystem begins to build.
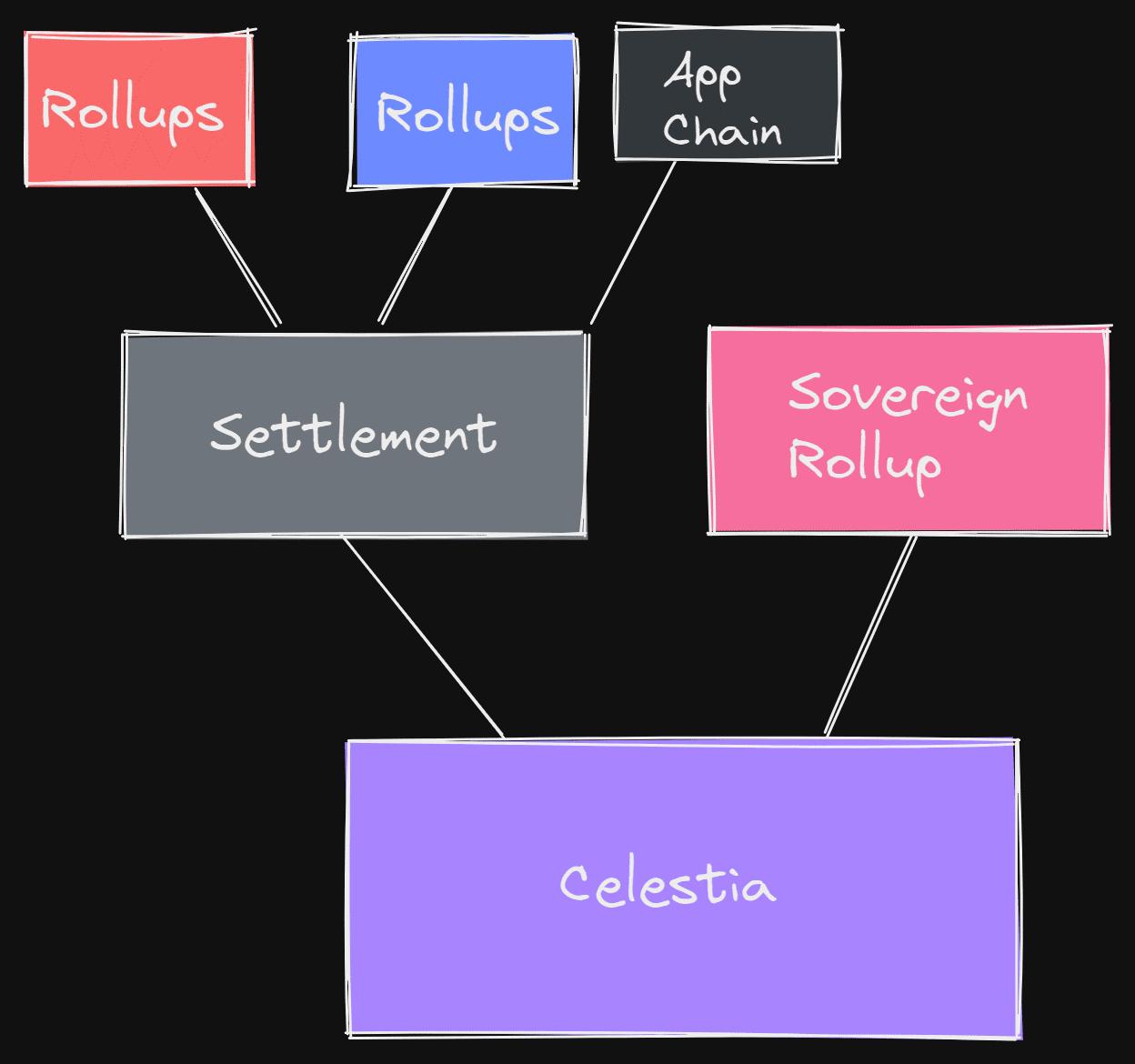
Early Celestia Ecosystem
This is the early ecosystem of Celestia. Celestia will serve as a shared consensus and data availability layer among all the various types of rollups operating within the modular stack. The existence of a settlement layer is to facilitate bridging and liquidity among the various rollups on top of it. While you will likely still see sovereign rollups operating independently without a settlement layer.
Now that we have established the different degrees of modularity, how they operate, and how they manifest visually, let’s look at some unique capabilities and functionalities that a purely modular blockchain (like Celestia) can achieve.
Shared Security
One major advantage of monolithic blockchains is that all users, applications, and rollups utilizing it benefit from the underlying security. So how does this work in a modular stack setup?
It’s actually quite simple; Celestia provides the fundamental functionality required to establish shared security on-chain, namely data availability. This is because every layer using Celestia must dump all its transaction data into the data availability layer to prove that the data is indeed available. This means chains can effortlessly connect, monitor, and interoperate with each other. By always having the security of an underlying DA layer, hard forks and soft forks become very easy, which we will discuss later.
Similarly, Celestia allows various types of experimental execution layers to run simultaneously, even without relying on a settlement layer, while still having the advantage of a shared data availability layer. This means the iteration speed will become faster as it can scale linearly with the increase in user numbers. Therefore, our argument is that over time, this will lead to compounded improvements in execution layers, as we are not constrained by a single entity with a centralized execution layer, since execution and data availability are decoupled. The permissionless nature of modularity allows for experimentation and provides developers with flexible options.
Data Availability Sampling and Block Validation
The block validation process in Celestia is quite different from other current blockchains because blocks can be validated in sub-linear time. This means that throughput increases with sub-linear growth in cost compared to linear growth in cost. So how does this look on paper? Let’s take a look.
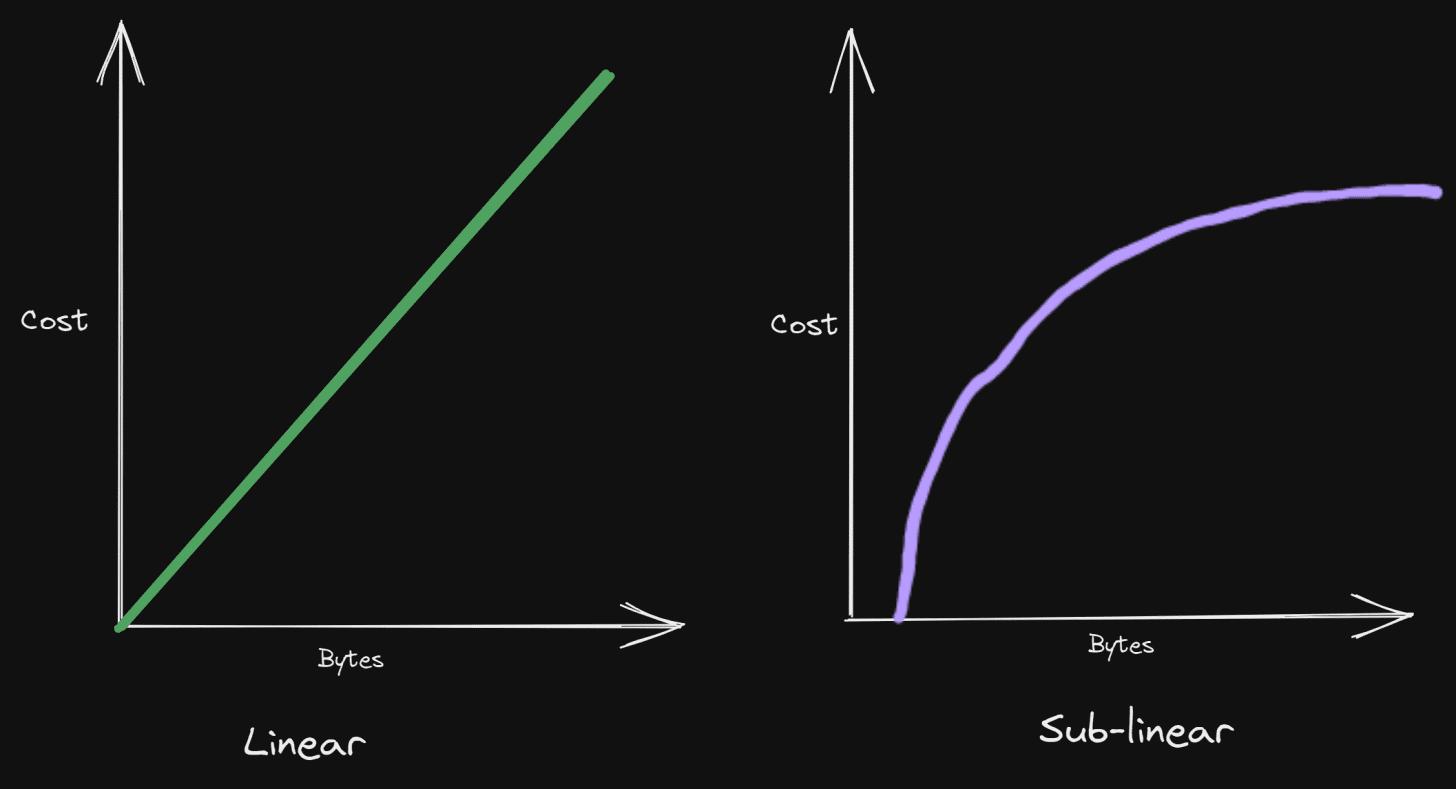
Linear vs. Sub-linear
This is possible because Celestia's light clients do not validate transactions; they only check whether each block has achieved consensus and whether the block data is available to the network.
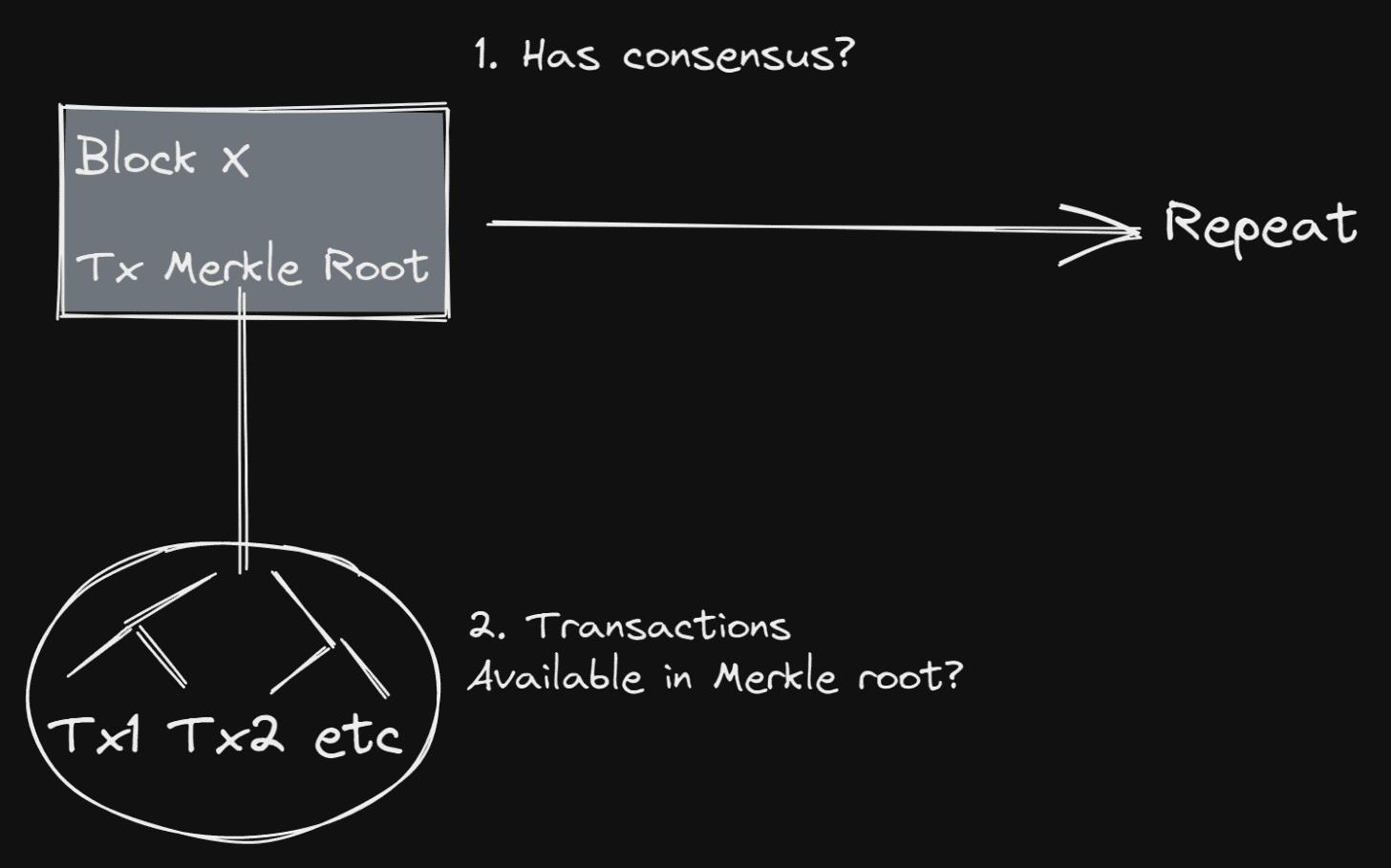
Block Validation on Celestia
Celestia does not need to check transaction validity because it only checks whether the block has consensus and data availability, as shown above.
Celestia light nodes do not need to download the entire block but instead randomly download small data samples from the block. If all samples are available, this can prove that the entire block is available. Essentially, by sampling random data from a block, you can probabilistically verify that the block is indeed complete.
This means that Celestia simplifies the problem of block validation to data availability verification, and we know how to effectively accomplish this verification using data availability sampling at sub-linear costs.
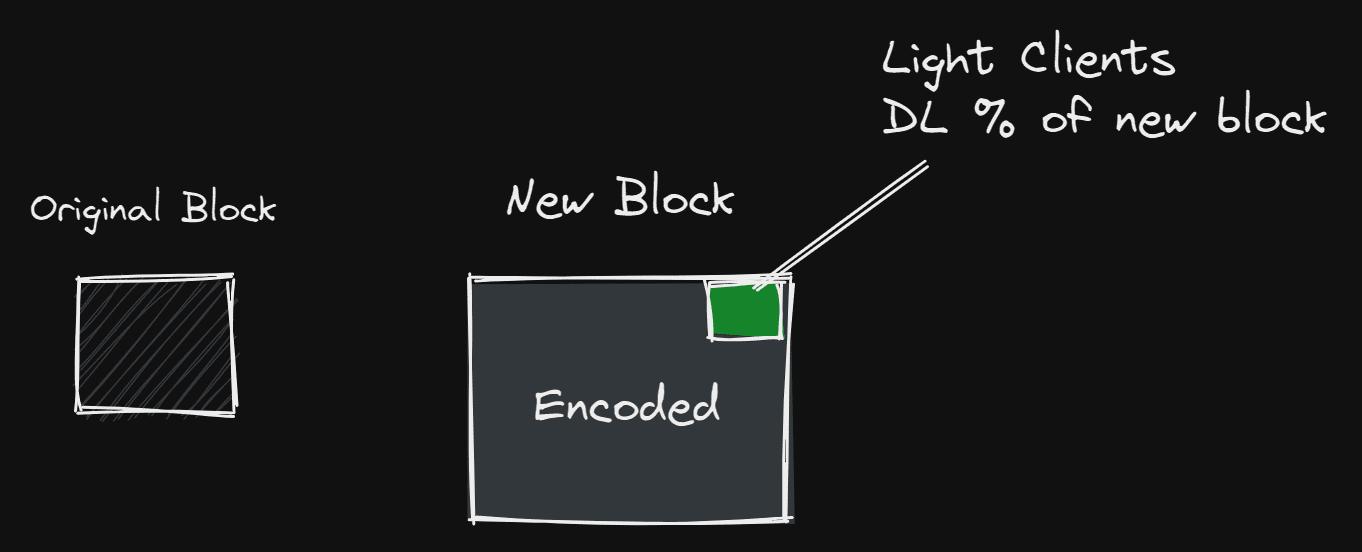
Data Availability Proof
Data availability proof refers to when you request that the block being sent is erasure encoded. This means the size of the original block data is now doubled, and then the new data is encoded into redundant data. Celestia's erasure encoding expands the block size by 4 times, where 25% of the block is original data and 75% is replicated data. Therefore, if it wants to commit fraud, a malicious sequencer or similar program would need to withhold more than 75% of the block data.
Thus, it allows light clients to check with very high probability whether all data of a block has been published, simply by downloading a very small block (DA sampling). Each round of sampling reduces the likelihood of data unavailability until it is confirmed that all data is available. This is very efficient because not every single node downloads every block; instead, many light nodes download a small part of each block, but the security guarantees remain the same as before. This means that as long as there are enough nodes sampling for data availability, throughput can increase with the number of sampling nodes. By using protocols like BitTorrent, you can become familiar with this type of network (DA proof) in your daily life, even without having used a blockchain.
Scalability
When we talk about scalability, most people typically think of transactions per second. However, this should not be the actual discussion surrounding scalability. When discussing scalability in a dedicated DA layer, it should be measured in mb/s rather than transactions per second, which should be the primary barrier to overcome. Mb/s becomes an objective metric for measuring a chain's capability rather than tp, as transaction sizes vary. Celestia performs very well in this regard because it removes the DA layer and leverages data availability sampling to increase the number of mb/s the system can handle.
What we mean is that the real limitation on how many transactions a blockchain can handle is based on inputs and outputs. Therefore, by decoupling data availability from the input and output processes handled by rollups, Celestia will be able to produce a higher byte count per second than monolithic entities.
All of this stems from the data availability problem. That is, the amount of data that can be verified by the sequencer or similar in a proposed block, while being limited by the throughput of the underlying DA layer. Now, for monolithic blockchains utilizing full nodes, the normal step to solve this problem is to increase the hardware requirements for full nodes. However, if you do this, the number of full nodes will decrease, and the decentralization of the network will be undermined.
Therefore, by leveraging the techniques we mentioned earlier in the block validation section, we can increase scalability by making full nodes equivalent to light nodes through the use of DA sampling without increasing node requirements. This, in turn, will lead to more throughput as the growth of nodes leads to more throughput because DA sampling results in sub-linear growth as it scales with the number of added light nodes. In monolithic designs, increasing block size similarly increases the cost of validating the network, but this is not the case in Celestia.
While Ethereum is also seeking to address some scalability issues with its EIP-4844, which will enable a new transaction type—blob transactions. These will contain a large amount of data that cannot be accessed by the EVM but can still be accessed by Ethereum. This is being done because currently, rollups on Ethereum rely on a very small amount of available call data to execute their transactions. Sharding will also help, but it is still far off, and at launch, it should allocate about 16MB of data space for rollups per block. However, how fierce the competition for blob transaction space will become remains to be seen. While once you solve one scalability puzzle, another may emerge. Therefore, by evolving towards a modular layer, we can allow various parts of the stack to specialize in the specific resources they use the most.
Forking
In most cases, when a hard fork occurs on a monolithic chain, you lose the underlying security because the execution environments do not share the same security. This means that hard forks are generally unfeasible or undesirable because it means the new fork will not have the security of the data availability and consensus layers. When we say you can submit changes to the blockchain code, the same idea applies, but you must convince everyone to agree to your changes. Take Bitcoin as an example. The code of Bitcoin is easy to change, but getting everyone to agree to the change is the difficult part. If you want to hard fork an entire blockchain, you also need to fork the consensus layer, which means you lose the security of the original chain. The loss of security depends on the number of miners or validators who do not validate the new specification chain. However, if all validators upgrade to the same fork, no security is lost.
On a modular blockchain, this is not the case because if you want to fork a settlement or execution layer, you still have the security of the underlying consensus layer. In this case, forking is feasible because the execution environments share the same security. However, this is not possible for rollups on the settlement layer because the settlement layer acts as a trust source for adding blocks. Because if you want to fork a settlement or execution layer, you still have the security of the underlying consensus layer. In this case, forking is feasible because the execution environments share the same security. However, this is not possible for rollups on the settlement layer because the settlement layer acts as a trust source for adding blocks.
Hard Fork Using Celestia as DA/Consensus Layer
The situation where hard forks are unrestricted and easy to accomplish in execution environments allows for testing and trying out crazy ideas. It also makes it feasible to work on top of others' work without losing the security of the foundational layer. If you consider the idea of a free market (some may disagree with this), it often creates competition that can yield better results.
Modular Stack
The modular stack is a unique concept to Celestia. It refers to decoupling all the different layers of a typical blockchain into independent layers. Therefore, when we talk about the stack, we refer to all the layers working together.
So what layers exist? Undoubtedly, there is the consensus and data availability layer of Celestia, but there are also other layers. Here we refer to the settlement layer, which is a chain that has a trust-minimized bridge for rollups and is used for unifying liquidity and bridging between various rollups. This settlement layer can take many forms. For example, there can be restricted settlement layers that only allow simple bridging and resolving contracts for the execution rollups above it; there can also be settlement layers that have their own applications and rollups. Of course, there are also rollups that do not rely on a settlement layer but solely depend on Celestia's own functionalities—these are called sovereign rollups, which we will discuss in the next chapter.
Now, it is also possible to have a stack where the execution layer does not directly publish block data to the settlement layer but instead publishes directly to Celestia. In this case, the execution layer merely publishes their block headers to the settlement layer, and then the settlement layer checks whether all the data of a certain block is included in the DA layer. This is done through a contract on the settlement layer that receives the Merkle tree of transaction data from Celestia. This is what we refer to as data proof.
 Modular Stack
Modular Stack
Another huge advantage of the modular stack is its sovereignty. In a modular stack, governance can be divided among specific applications and layers without overlapping with other applications. If there is an issue, governors can fix it without interfering with other applications in the cluster.
Sovereign Rollup
A sovereign rollup is a rollup that is independent of any settlement layer. This means it does not rely on a settlement layer with smart contract capabilities (where it would provide state updates and proofs) but operates purely through namespaces on Celestia. Typically, rollups operate within an ecosystem, such as Ethereum, which has rollup smart contracts (resolution contracts). The smart contracts of this rollup also provide trust-minimized bridging between the settlement layer and the rollup. However, on Ethereum, all rollups compete for precious call data. This is why EIP-4844 is being researched, as it will provide a new transaction type—blob transactions—and increase block size. However, even with blob transactions, it is likely that there will still be fierce competition for settlement.
Most monolithic blockchains have the capability to handle smart contracts. Taking Ethereum as an example, there is an on-chain smart contract that handles the state root, which is the Merkle root of the current state of the rollup. This contract continuously checks whether the previous state root matches the current root of its rollup batch. If so, a new state root is created. However, this is not possible on Celestia because Celestia does not handle smart contracts.
Instead, on Celestia, sovereign rollups publish their data directly to Celestia. The data here is not computed or settled but merely stored in the block header. The block header is what identifies a specific block on the blockchain, and each block is unique. Within this block header, there exists a Merkle root composed of all the hashed transactions.
So how does it work? Rollups have their own p2p network, from which both full nodes and light nodes download blocks. However, they also verify that all rollup block data is sent and scheduled on Celestia through Merkle trees (hence referred to as data availability)—we have seen such examples earlier. Therefore, the standard history of the chain is set by local nodes that validate that the rollup's transactions are correct. The implication here is that sovereign rollups need to publish every transaction on the data availability layer so that any node can track the correct state. Thus, full nodes observing the rollup namespace (considering the namespace as the smart contract of the rollup) can also provide security for light nodes. This is because, on Celestia, light nodes are almost equivalent to full nodes.
Let’s elaborate on namespaces: on Celestia, Merkle trees are sorted by namespaces, allowing any rollup on Celestia to only download data relevant to their chain while ignoring data from other rollups. Namespace Merkle Trees (NMTs) enable rollup nodes to retrieve all rollup data they query without parsing the entire Celestia or rollup chain. Additionally, they allow validator nodes to prove that all data has been correctly included in Celestia.
So why do sovereign rollups have unique prospects? Because previous rollup implementations, such as those on Ethereum, are limited because Ethereum nodes, being monolithic, need to store execution-related states. However, in a modular design, we can have dedicated nodes for various purposes, which will significantly reduce the operational costs of the network. Therefore, the cost of running the network will be proportional to the cost of light nodes rather than full nodes, as we explained earlier—light nodes = full nodes.
Let’s look at how some rollup implementations can function as sovereign rollups. First, it is necessary to clarify how various rollup proof systems operate on Celestia.
Optimistic Rollups rely on fraud proofs. Fraud proofs will be verified between full nodes and light nodes of the rollup in a peer-to-peer manner among clients. We will further explore the implementation of this. Sovereign rollups change the distribution of fraud proofs. They are now verified not on the settlement layer contract but distributed within the rollups' peer-to-peer network and verified by local nodes. Through sovereign Optimistic Rollups on Celestia, we may also minimize the challenge period, which means we have addressed one of the main obstacles of current ORs, as their dispute window on Ethereum is very conservative. This is possible because currently, all fraud interactions occur in Ethereum's highly competitive block space, leading to prolonged finality. However, on sovereign rollups, any light node connected to an honest full node has the security of a full node, so fraud interactions should be faster.
ZK Rollups rely on validity proofs (e.g., zk-SNARKs). The functionality of ZK rollups as sovereign rollups is quite similar to current implementations. However, it does not send ZK proofs to smart contracts but distributes them on the rollup's peer-to-peer network for nodes to verify. Sovereign ZK rollups, like ZK rollups on a unified settlement layer, allow various execution runtimes to operate as sovereign chains on top of each other, as their transactions do not need to be processed by Celestia. Runtimes running on top of ZK rollups can operate in various ways. There can be privacy-preserving runtimes, application-specific runtimes, and many more. This is what Fractal Scaling is about.
Now that we have established the concept of sovereign rollups and have a notion of their implementation on Celestia, here are the architectures of two different rollups.
 Sovereign Rollups on Celestia
Sovereign Rollups on Celestia
So why do they need Celestia? Optimistic rollups need DA to discover fraud proofs, and ZK rollups need DA to know the state of the rollup chain.
When you look at something, it is always important to maintain a reverse mindset. Because if you don’t, you often get blinded by your own beliefs. In this section, I will attempt to explain some negative aspects of sovereign rollups.
Sovereign rollups will largely depend on the new ecosystem built on top of them, similar to the often-boasted L1 plays. This means dApps, etc. However, if a rollup has a virtual machine implementation with a lot of development activity already, and the dApps are open source, it will become easier to achieve this. Nevertheless, liquidity remains a major issue to overcome. Liquidity often gets fragmented across sovereign rollups and their runtimes. Therefore, rollups will largely rely on secure, trust-minimized bridges with other layers, such as other sovereign rollups or settlement layers. We will discuss some possible implementations later. Additionally, the implementation of sovereign rollups largely depends on the construction of infrastructure that can support their various functionalities.
Optimistic Rollup Implementation
In this section, we will attempt to explain how a possible sovereign Optimistic Rollup implementation operates. This part heavily draws from the research paper Light Clients for Lazy Blockchains written by Ertem Nusret Tas, Dionysis Zindros, Lei Yang, and Davis Tse.
One unique way to construct fraud proofs for OR is to have full nodes and light nodes play a partition game on the rollup. The partition game is conducted between two nodes, one being the challenger and the other the responder. The challenger sends a query to the responder through a third node acting as a validator. The responder's reply to the query will be sent back through the same channel. Upon receiving the challenge, the validator will forward the query to the responder, who will then produce a response and send it back to the validator and challenger. The validator will continuously check to ensure there are no mismatches or malicious behavior between the two. The role of the validator is to ensure that the responder has not sent an incorrect Merkle tree, while the role of the challenger is to ensure that the responder follows the correct root. If the responder can defend themselves, the game continues as usual. The outcome of this partition game is that honest challengers and responders will always win.
 Partition Game on Optimistic Rollups
Partition Game on Optimistic Rollups
DA on Celestia, Settlement on X
Celestia can bridge without using a purely Celestia-connected settlement layer, nor does it have to act as a sovereign rollup. Because Celestia merely provides an underlying DA layer with shared security, as long as Celestia can send the Merkle root of available transaction data to the settlement layer contract, any settlement layer can be used. This means that any settlement layer can be used for rollups if they wish. So why would they want to do this? Many existing settlement layers, such as Ethereum, already have a thriving ecosystem in place. Therefore, liquidity is already available, and users can take advantage of it. This is particularly beneficial for rollups that do not want to build an entire ecosystem from scratch. Now, this is not purely limited to Ethereum as a settlement layer. For example, you could also leverage Mina as a ZK rollup. That is, you could send your transaction data to Celestia while sending state updates and zk proofs to Mina. Thus, you already have a default validity-proof settlement layer.
If you are a rollup operator and want to leverage liquidity and users from other blockchains, then this type of solution is very attractive to you. Additionally, to some extent, it is also possible to become a plug-and-play rollup operator. You can allow different sequencers to plug into different settlement layers. For example, a ZK rollup sequencer can connect to Mina and provide state updates and validity proofs. While another sequencer on a different ZK rollup can connect to Ethereum, settling through quantum bridges (the legendary Celestiums). What they have in common is that they will send all transaction data to Celestia, and then Celestia will run a smart contract or something similar on the settlement layer, sending a Merkle tree of available data (proof).
Let’s take ZK rollups as an example and see how this would look architecturally:
 DA on Celestia, Settlement on X
DA on Celestia, Settlement on X
Value Accumulation
The revenue source for Celestia itself will come from transaction fees for transaction batches submitted by various rollups. Celestia's transaction fees will operate similarly to Ethereum's current EIP-1559, so it will have a burn mechanism. This means there will be a dynamic base fee that gets burned, along with a "tip" for validators to expedite a transaction, and these validators will also gain value from token issuance after new blocks. However, this is from the perspective of Celestia's validators, so what would it look like from the user's perspective? Let’s first determine what various fees would look like based on the layers you use, and then derive the specific user experience.
The fee structure for executing rollups will primarily be operational costs + DA publishing costs. Of course, there may also be a management fee to allow the rollup to make a profit. This means that for users, you might pay fees that include these three aspects + a congestion fee—this fee could be much lower due to reduced congestion.
The revenue source for the settlement layer comes from the settlement contract fees paid by rollups to enable settlement on it. Additionally, there will be trust-minimized bridging between rollups through the settlement layer, so the settlement layer will also be able to charge bridging fees.
So what about sovereign rollups operating without a settlement layer? On sovereign rollups, users will have to pay a gas fee to access computation on the rollup. The rollup will set a fee, likely determined by the management, and there may also be a congestion fee that must be paid. These fees from the rollup will cover the costs of publishing data to Celestia and a small overhead for rollup validators. You will forgo settlement fees because the costs incurred for end users may be quite low.
So, in the end, we can create a fee structure that illustrates how various fees appear to the end user. The end user of the modular stack may face 3 fixed fees, including DA publishing fees, settlement contract fees, and rollup execution fees. Of course, there could also be 4 fees, including congestion fees during overload periods. Users only need to pay a single fee at the execution layer, which will encompass the fees of all layers in the modular stack. Therefore, let’s see what the fee structure would look like from the user's perspective:
 Fee Structure
Fee Structure
So what does this mean for the future?
If Celestia proves to be a cheaper and faster data availability layer while still providing decentralization and shared security, then you can expect to see more and more rollups using it for data. If we consider the fees that rollups currently pay for the security of using Ethereum, fees on Celestia will be significantly lower. However, some improvements are on the horizon to address congestion issues on Ethereum, primarily blob transactions, staking, and sharding.
What about MEV? Currently, rollups utilize sequencers to collect and order users' transactions in the mempool before executing and publishing them to the DA layer. This raises a question about MEV because, in the current implementation, sequencers are primarily centralized, thus lacking censorship resistance. The current solution to this problem is to decentralize sequencers, and many current rollup plans are doing just that, although this brings its own set of issues. Another way to address this issue in some form is to separate the ordering of transactions from validators (if you are interested, you can check out Vitalik's paper).
In summary, the various layers of the modular stack earn revenue through transaction value. Users gain value by transacting on one layer, thus becoming familiar with paying fees. Therefore, value refers to the value users gain when their transactions are included on a layer.
Bridging
As we discussed earlier, if a rollup has a settlement layer, it will have a trust-minimized bridge with other rollups through the settlement layer. But what happens if it is a sovereign rollup, or if it wants to establish a bridge with another cluster? Let’s take a look at cross-rollup communication.
In the case where two sovereign rollups want to communicate, they can actually utilize light client technology, similar to the functionality of IBC. Light clients will receive block headers from both rollups and the proofs used by the rollups through a P2P network. This can work either through locking and minting mechanisms, like IBC, or through validators of relayers. Chains built using the Cosmos SDK and those utilizing Tendermint or Optimint bridging can become more seamless because you can fully leverage ICS's IBC. However, this requires both chains to include each other's state machines and allow the validators of the bridging chain to validate transactions. Other bridging methods can also exist.
For example, we can envision a third chain that functions as a kind of light client. On this chain, the two chains wishing to bridge can circulate their block headers and then operate as the settlement layer for both chains. Alternatively, you could rely on a Cosmos chain to act as a "cross-cluster rollup hub," where validators on the chain can operate the bridge by following the conditions of the rollup. Additionally, there are various bridging-as-a-service chains, such as Axelar and many others.
However, thus far, the simplest way to facilitate bridging is to have executing rollups use the same settlement layer, as they will have trust-minimized bridging contracts on it.
The importance of bridging between layers lies in the fact that it can achieve unified liquidity. Secondly, by allowing protocols and layers to combine through shared state, we can unlock new levels of interoperability. State sharing refers to the ability of one chain to call another chain. A particularly notable point is the capability of ICS-27 interchain accounts.
Thus, we can conclude that light clients are crucial in interoperability standards like IBC. The result of Celestia's light clients will make interoperability between various cluster chains more secure. Regarding the connection between Celestia and IBC, they are planning to use governance to whitelist certain chains for connection to Celestia to limit state bloat.
End User Verification
While various monolithic and modular design approaches over the past few years have been innovative, and the talent behind building these approaches is impressive, a fundamental question has existed for quite some time amidst various trade-offs. We believe its core lies in the need for end user verification.
You can argue endlessly about the various trade-offs of different designs, and CT will do so. But ultimately, this may boil down to one question—Is the possibility of end user verification important? Many design trade-offs (such as block size) revolve around the convenience of running a full node, while DAS makes light clients "first-class citizens" that can rival full nodes.
The basic assumption of thinking this way is that users will care about being first-class citizens. Users can easily verify the chain by running light clients/full nodes, but that does not mean they will do so, or that they will value the ability to do so.
The argument supporting this practice is quite straightforward. If users do not care about verification, you might as well run a centralized database. It will always be more efficient because decentralization often comes at the cost of efficiency. The reason we build cryptographic protocols is that end users can verify the computation.
The counterargument is that as long as the network is sufficiently decentralized, end user verification itself does not matter. As long as the user experience is good, users will not care about it. How important end user verification is remains an open question. However, we believe that enabling end users to verify the chain is a goal worth pursuing and is one of the reasons many are building in this space.
The Future of the Modular Stack
This section will envision what a modular stack built on Celestia might look like in the future. We will explore how we view the architectural overview of the modular stack and what layers we might see.
Below is an illustration of many possible layers that could play a role in the modular stack. They all share one commonality: they use Celestia to provide data. We may see various sovereign rollups, including Optimistic and ZK rollups, operating without a settlement layer. We may also see rollups leveraging Cevmos as a settlement layer, along with various application chains. Additionally, there is a possibility that we may see other types of settlement layers. These settlement layers may be restricted, meaning they either have pre-set contracts solely for cross-chain bridging and rollups or rely on governance to implement whitelisted contracts.
 The Future of the Modular Stack
The Future of the Modular Stack
On the right side of the diagram are other non-native settlement chains, which may also have rollups to leverage them for liquidity and settlement while relying on Celestia to provide transaction data proofs to the settlement layer.
All these clusters will be interconnected through various cross-chain bridging services, including new and old bridges.
Additionally, what you do not see is that in the future, all the infrastructure will be built to facilitate access to the various functionalities of Celestia, such as RPC endpoints, APIs, and more.
In Conclusion
If you want to build on top of Celestia, whether regarding rollups or other types of infrastructure, please reach out to us. We would be happy to talk with you.
 Risk warning
Risk warning Risk warning
Risk warning




Popular articles








