

















Cipholio Deep Analysis: A Discussion on ZKVM Solutions and Future

 This article will focus on analyzing ZK technology and its application scenarios from the perspective of ecological development, describing the current competitive landscape related to ZK, and envisioning some directions for future development.
This article will focus on analyzing ZK technology and its application scenarios from the perspective of ecological development, describing the current competitive landscape related to ZK, and envisioning some directions for future development.Author: Yolo, Cipholio Ventures
TL; DR
ZK technology has two main use cases: privacy and scalability. When we discuss privacy, we use ZK technology to protect off-chain data from being accessed; when we discuss scalability, we use ZK to save on-chain computation space. For example, if I want to confirm that a certain account has 100 units of currency, the traditional blockchain method requires every node to verify it, while now I only need one node to find the most recent proof of a net inflow of 100 units, thus proving the account has 100 units. The difference is that the former requires extensive computation and proof, while the latter only requires off-chain proof.
The core trade-off in the development of ZKVM is whether to leverage the potential of ZK or to utilize the current developer resources. Focusing on leveraging ZK potential means hardware acceleration of CPU registers, reorganization of IR languages and assembly languages; while focusing on utilizing developer resources means addressing the issue of how to perform ZK proofs on the opcodes mapped from the bytecode after converting Solidity.
According to the modular blockchain perspective, L1 solves the consensus problem, L2 addresses computation and execution issues, and the DA layer resolves data availability and integrity issues. Due to ZK-type L2, its proof.
Designing specialized ZK apps using assembly language independently will face significant obstacles in future development due to low composability and decoupling capabilities. These solutions are incompatible with other ZK solutions' VMs, languages, and proofs, leading to considerable invocation difficulties.
Dependency on time-series transaction logs, data security, and proof integrity determines the reliability of execution. With most ZK solutions currently being closed-source, there is significant potential for development in ZK security auditing.
Since ZKP relies on off-chain data, handing it over to the DA chain would compromise data privacy. To balance data privacy and ensure ZK proof nodes do not act maliciously, new solutions are needed. We are optimistic about future secure computing solutions like MPC/FHE.
As different circuits continue to mature, ZK proofs may also see efficiency improvements and specialization, and hardware acceleration solutions for ZK proofs, as well as specialized ZK miners, may emerge.
Limitations of ZKP experience. Typical issues include: the constraint system cannot effectively constrain data, facing inadequacy when proving complex intersecting propositions; private data leaks, treating private data as public; attacks on off-chain data, "metadata-attack" at the contract layer; malicious behavior of ZK proof nodes, etc.
In the short term, the security of ZK solutions is limited; currently, much consensus is still based on the self-discipline of off-chain nodes, lacking a series of necessary tools (testing, proof, etc.) to ensure the security of the off-chain environment.
Overview
ZK technology has always been difficult to discuss fully due to its complex terminology. This article will focus on analyzing ZK technology and its application scenarios from the perspective of ecological development, describing the current competitive landscape related to ZK, and envisioning future development directions. This article focuses on:
- What are we discussing when we talk about ZK technology? (Knowledge foundation; institutional investors can start reading from the second part.)
- How to view the development patterns and structure of gzkvm (generalized zk vm) from a technological development perspective?
- A comparison of the main ZKVM technology solutions currently available?
- Analysis and outlook
1. Virtual Machine ABC - Starting from Everyday Computers
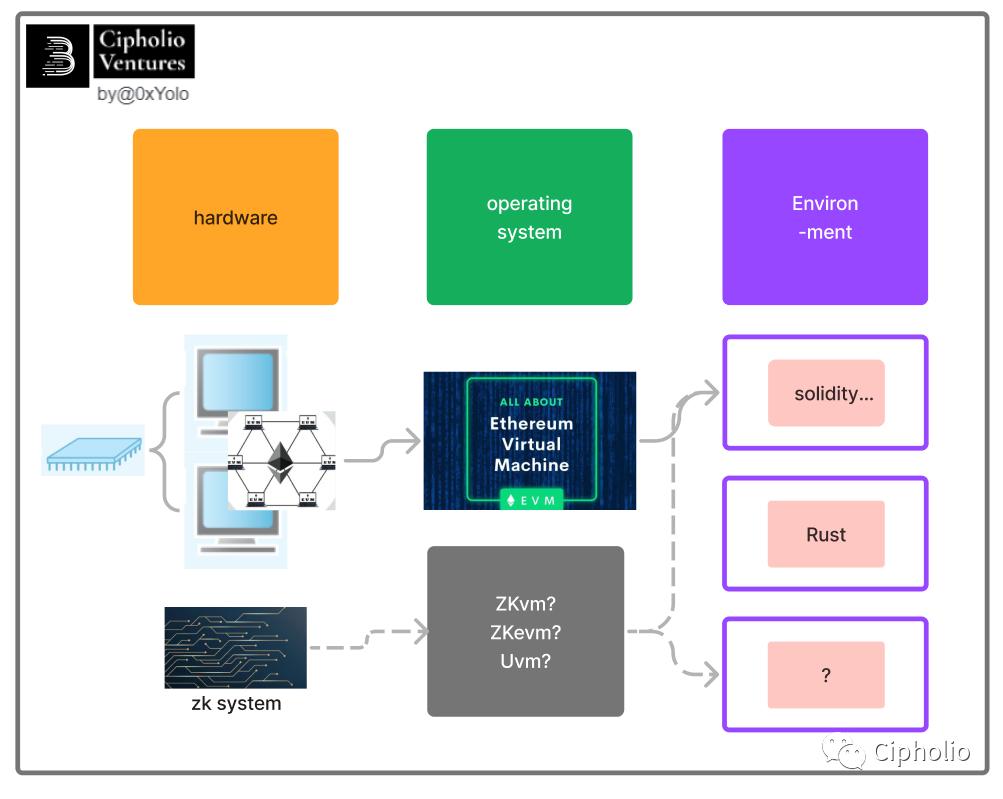
Before introducing knowledge related to ZKEVM, I would like to start with the structure of our everyday computers. We all know that computers consist of software and hardware. To ensure that software runs smoothly on hardware, we need to match the software with an appropriate operating environment. From a structural perspective, the operating environment consists of [hardware + operating system].
The yellow part represents hardware, and the green part represents the operating system. Some may wonder: why is the operating environment not equivalent to the operating system? This is mainly because operating systems cannot be compatible with all hardware; only the matching of the operating system and hardware can provide services for the software. We will mention this issue again in the later development path of ZKVM.
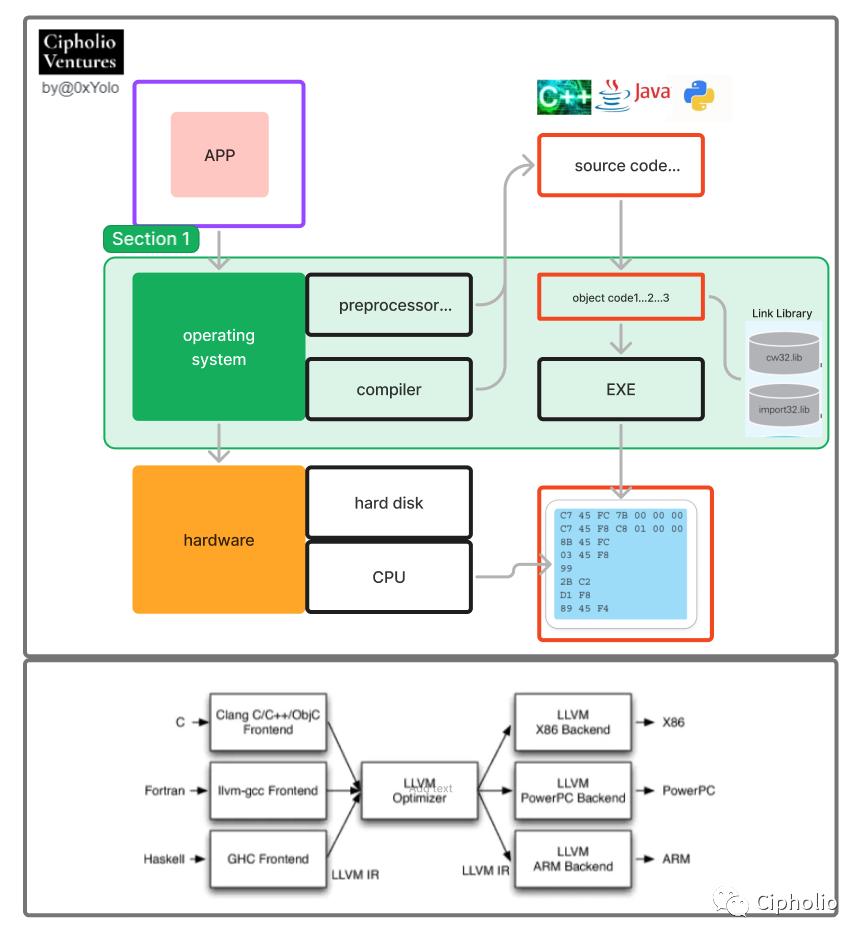
With an operating environment, we also need specific software (program/app) to meet specific needs. So how does a program run?
From the diagram, we can see the entire process where software is computed by the hardware layer through the operating system. During this process, the programming language undergoes three stages of transformation: high-level languages are used to write programs to fulfill actual needs, assembly language is used to communicate with the computer, and the low-level native code (hexadecimal numbers) is executed by the computer. Specifically, after the programmer completes the app's code, it is translated into obj (object language) by a translator. These discrete object languages are linked through the Linker in the operating system, and the output executable exe file is stored on the hard drive.
When running, the exe file will place data into memory, and the CPU will convert the obj into native code (bytecode) for computation, achieving app I/O. There are many choices in this process: diverse languages, various operating systems, and different hardware, leading to numerous trade-offs from a business perspective, and these choices ultimately reflect in the improvements of the compiler kernel LLVM (low-level virtual machine).
In the diagram below, we can see various corresponding relationships and constraints between hardware (yellow) and the operating system:
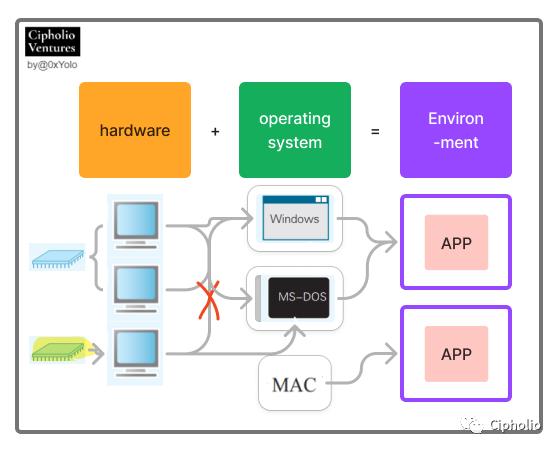
The same type of hardware can install multiple operating systems, and different hardware requires matching different types of operating systems. For example, the same AT-compatible machine A can install both Windows and LinuxB operating systems. Similarly, hardware with X86 chips requires an x86 version of Windows for compatibility. This is mainly because the assembly language at the operating system's core needs to match the chip.
The successful operation of an app requires compatibility with both the CPU and the operating system. For example: 1. To ensure the normal operation of Office 2017, an x86C CPU is required; 2. Some apps can only run on Windows XP and not on 2000.
The CPU can only interpret its inherent machine language. Different CPUs can interpret different types of machine languages. In other words, apps written in different high-level languages cannot be executed by the CPU if they cannot be compiled into a language that the CPU can compute through the [operating system].
2. What is Zk VM?
When we discuss ZK, we typically do so in three contexts:
- Using ZK as a scaling solution RollupL2.
- Using ZKP for proof applications, such as dydx, Zklink, etc.
- ZK proof as a cryptographic algorithm.
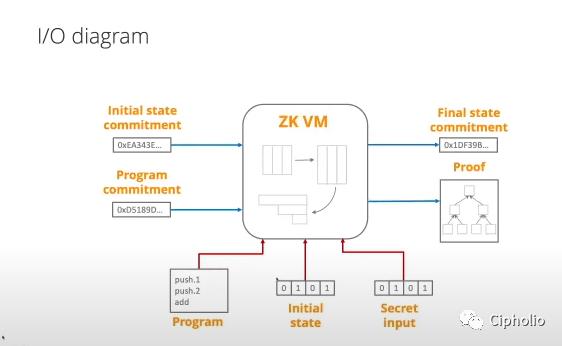
What language, in what environment, and on what hardware is executed? This is the problem that the generalized VM aims to solve.
Having just introduced traditional operating systems (which are also a type of VM), we can see that ZKVM performs similar functions, facilitating communication between the hardware layer (native chain + ZK proof system) and high-level languages (Solidity or native ZK languages). Its core is data proof and state updates. When the system receives two types of input, raw data (state and instructions) and proof (related proof for state and instructions), it compares and computes, then outputs instructions (updates state) and ZKP (proof), submitting them to L1 for consensus broadcasting.

Specifically, ZK proof goes through several parts (by JP Aumasson, Taurus):
Local computation;
Definition of circuits. For example, confirming whether your wallet has money, whether the information is complete, and whether the signature is correct;
Arithmetic proof: using mathematical methods to prove that the computation is executable.
Comparing the arithmetic proof results with the actual results.
Submitting the results on-chain.
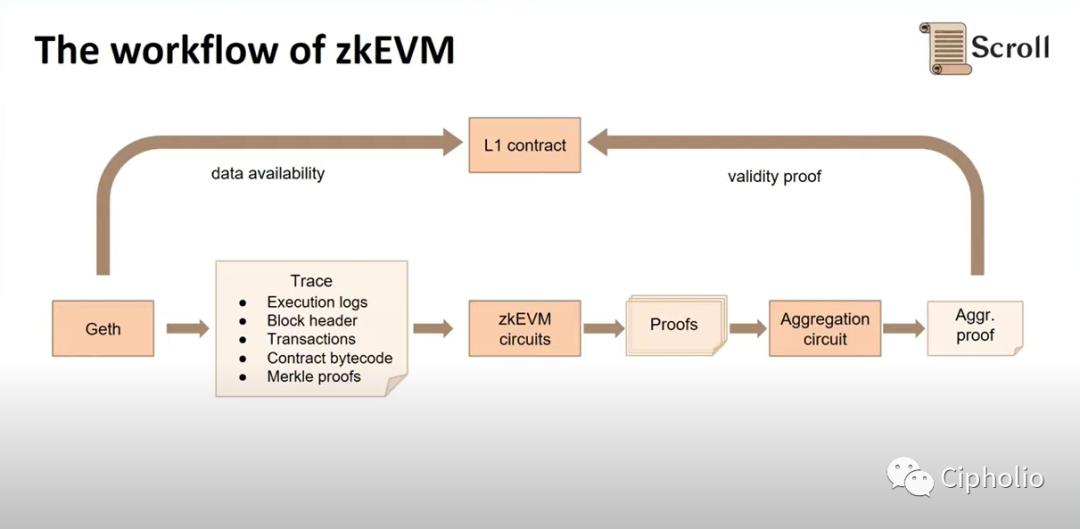
Taking Scroll's solution as an example, we see that starting from Geth, the system completes local computation, decomposes the transaction trace (transaction history log) into circuit operators, and then uses arithmetic methods (such as polynomial decomposition, cryptography) to derive ZK proof. It then compares the data and proof, and if correct, broadcasts it on-chain. This involves many key technologies, such as how to set circuits, what types of circuits exist, and how to decompose circuits. The entire confirmation method can be imagined as a massive table, where each variable has its parameters, seeking the necessity of specific results against the backdrop of known historical data.
For example, if I want to confirm that a certain account has 100 units of currency, the traditional blockchain method requires every node to verify it, while now I only need one node to ensure data integrity, plus the recent proof of a net inflow of 100 units, and then confirm it (the situation in the example is relatively simple and can be seen at a glance; in actual situations, mathematical operations are required). Once completed, it can prove that the account has 100 units. The difference is that the former requires computation from every node, while the latter only requires computation from a single node and zk proof. In this example, what is confirmed is "how to prove off-chain that the account has sufficient balance," and the constraints needed for proof are "when the net inflow of the account in the recent historical timeline exceeds 100 (essentially based on the proof of Merkle Root), then compare the node's computation results with ZKP to determine whether the state is correct."
Common Ground of ZK Languages

According to the summary of MidenVM, the main tools used by current ZK apps in the market are primarily assembly languages based on WASM and RISC V. Some toolkits allow applications to quickly adopt the concept or label of "ZK." However, upon slightly dissecting the structure, we find that traditional smart contracts are secured by L1, and the security of consensus formed by broadcasting across the network has been historically validated, while using off-chain ZKP proof raises the issue of whether ZKP proof nodes act maliciously.
Setting aside whether developers can reasonably establish constraints (Constraint), how to prevent the malicious intent of ZKP proof nodes is undoubtedly more important.
For instance, some ZK DEXs seem to be seeking a balance between CEX and DEX; compared to CEX, users can keep funds in their own L1 accounts; relative to DEX, they can achieve better efficiency. However, in practice, many projects face security risks with off-chain proofs. Additionally, since the APP layer to the IR layer is independently developed by zkAPP teams, each team has its own programming habits and libraries, making it difficult for teams to achieve composability and hindering the acceleration of market division and hardware device acceleration.
Therefore, the market is looking for a common ground between cryptography and high-level languages to provide a universal framework for various applications, and ZK-VM is a crucial part that adapts the entire system, bridging the gap.
In terms of execution mode, EVM and JVM are very similar. Both are stack machines that execute bytecode. EVM adds a storage concept, and its bytecode instructions are more suitable for contract development.
In the diagram, we take ETH as an example. Traditional ETH consists of three parts: the ETH network (nodes + consensus mechanism), EVM, and the Dapp development ecosystem. Here we can clearly feel the bridging role of ZK:
- From the perspective of ZK circuit hardware:
EVM may not be fully compatible. Some variable-length instructions in EVM, such as CALL, DATACOPY, EXP, CREATE, etc., are not friendly to ZK circuits.
- From the developer's perspective:
Is it possible to retain EVM's API characteristics without needing to learn a new language (Solidity remains compatible)? In this case, the entire ecosystem may lose support for some ZK algorithms.
In addition, ZKVM also needs to consider many technical compatibilities, such as:
Compatibility of registers. Machine Type. Traditional EVM is a stack-based state machine, so a lot of computations are sequential and cannot be parallelized, ensuring the atomicity of the entire computer. This architecture is very unfavorable for ZK; to leverage the full efficiency of ZK algorithms, a register-based design is needed, focusing on CPU registers as the core architecture for the VM.
Language compatibility. Function Calls. The VM system encapsulates underlying features into APIs; how to allow APIs to support dynamic calls and support high-level languages like Python.
Compatibility at the computer's core. Native Field. Different CPUs have different bit sizes, performing differently on various algorithms. Planning is needed for ZK-specific computing machines.
Compatibility with traditional public chain structures: Sequencer/Roller/Miner.
3. ZKVM Architecture
Mainstream technical solutions
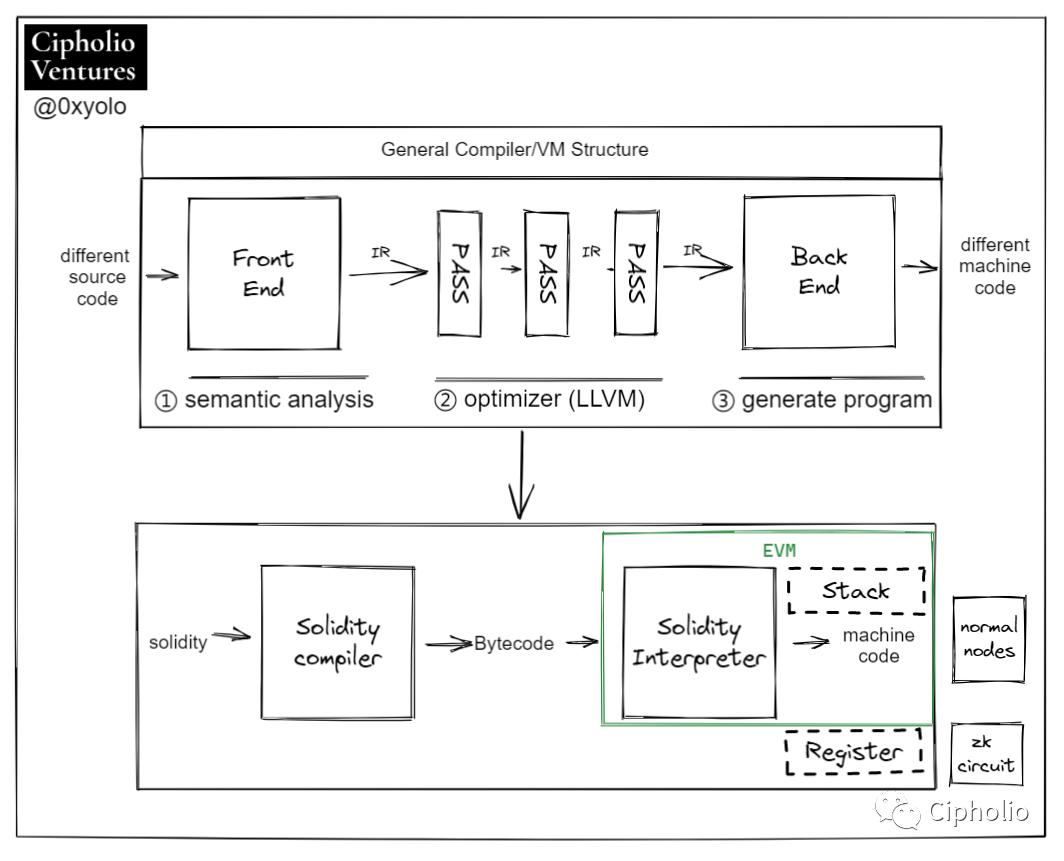
What language, in what environment, and on what hardware is executed? This is the problem that the generalized VM aims to solve.
The most important kernel in the VM is LLVM (low-level virtual machine), which can be seen as the most crucial kernel of the compiler. The diagram shows the operation scheme of the original EVM, where smart contracts are transformed through LLVM IR intermediate code into bytecode. These bytecodes are stored on the blockchain, and when a smart contract is called, the bytecode is converted into the corresponding opcode, which is then executed by the EVM and node hardware.
Combining ZK, how do various solutions implement this?
Starkware
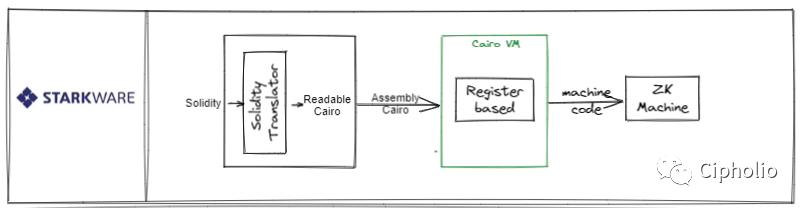
Starkware started early in the entire ZK field, has accumulated sufficient technology, and possesses a certain technological lead. It is a representative ZK-centric technical architecture that has built Cairo VM and the Cairo language around ZK. However, due to its closed-source status, some technical details are unclear. Its drawback lies in the learning cost of Cairo. Although the official has developed some frameworks for converting Solidity to Cairo, since its underlying core is built on CairoVM, it means that many Solidity-EVM compatible features will be lost.
Zksync
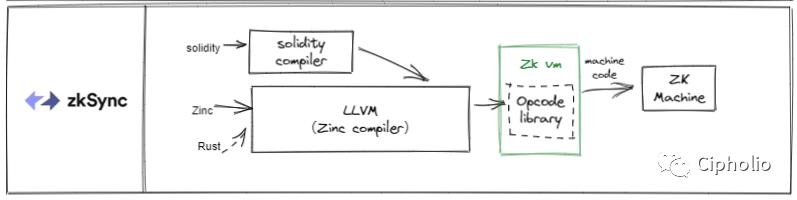
The ZKsync framework integrates both EVM and ZK characteristics, merging Solidity with its independently developed circuit language Zinc, unifying the two at the IR level within the compiler. Its advantage lies in the compiler kernel LLVM's ability to support multiple languages. Zksync is also a closed-source framework.
Hermez by Polygon
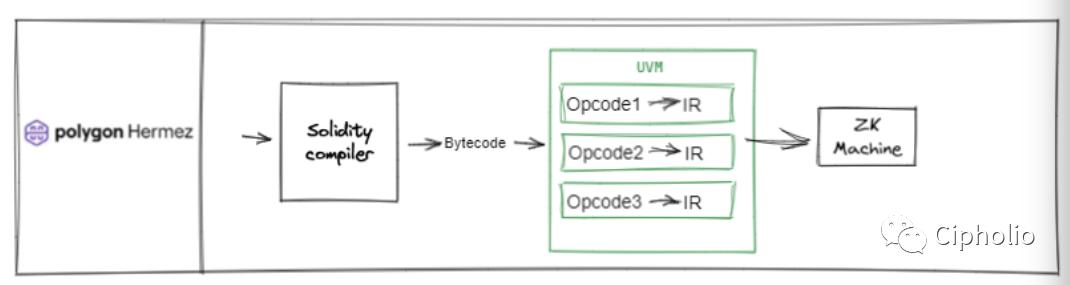
Scroll
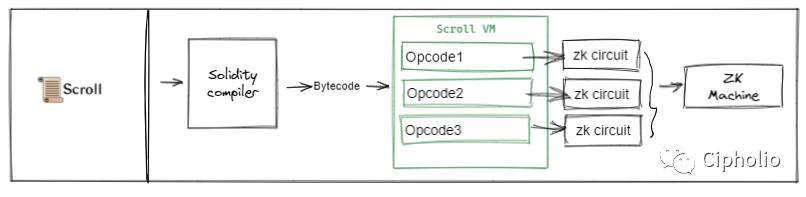
Both HermZ and Scroll focus more on the Ethereum ecosystem, integrating with the ETH ecosystem at the bytecode level. Since EVM natively supports bytecode and its corresponding opcodes, these two have a higher degree of integration with the ETH ecosystem. Solidity can fully call EVM's APIs on these two ZKVMs, retaining the architectural advantages of EVM. The two solutions differ in that Hermz will unify the opcodes internally before proving; while Scroll will decompose the opcodes into circuits for proof and then integrate them.
Why choose to be EVM compatible? Because some architectures in EVM have been validated, offering good security and compatibility. For example, the Geth model and RPC architecture, these APIs have been well encapsulated by EVM and have been historically validated.
In summary,
- Starkware unifies at the lowest level from the WASM and machine code level, ZKsync unifies at the IR level, while Hermz and Scroll unify at the bytecode level;
- Starkware is the most thorough in technological transformation but also has the highest learning threshold for users; ZKsync is relatively balanced, retaining some Solidity features while leveraging partial ZK performance;
- Hermz and Scroll are relatively easy to apply and decompose, fully integrating bytecode and EVM, especially Scroll, which opens up ZK proof and provides greater space for hardware acceleration.
- Overall, whether driven by technology or ecological integration, each has its development space in the future, and both "trade and technology" and "technology and trade" have opportunities to find their scenarios and create greater value.
If we reflect on the history of Windows, before the emergence of powerful operating systems, different developers needed to master different development tools for different hardware. Developers who do not master assembly language or understand the underlying workings of computers encounter many setbacks during development. Operating systems seek the greatest common divisor among hardware, encapsulating all I/O systems outside the CPU into a unified interface. This technological accumulation has significantly lowered the threshold for software development, allowing most programmers to understand high-level languages, enabling them to write beautiful apps even without knowledge of assembly or low-level code.
Reflecting on the development of ZKVM, we can see some clues. If current ZK apps require traditional programmers + assembly + cryptographic knowledge reserves to develop, in the future, as ZKVM matures, more and more underlying technologies will be encapsulated into high-level languages, gradually lowering the development threshold, and ecological prosperity is foreseeable.
For founders, there are two points to note:
ZK technology transforms on-chain consensus into off-chain proof. Currently, proof technology is relatively mature, but there are still many security risks in proof decomposition and data storage. Relevant auditing institutions and testing tools are still lacking.
The use cases for ZK technology are yet to be explored. General-purpose ZKVM is being developed intensively, and the corresponding high-level languages for ZK also require learning from technical personnel. There is still some time from technological maturity to problem-solving. Founders need to answer: if it is a niche scenario, do they need to build it themselves using WASM? Once ZKVM matures, will their technical accumulation still have a first-mover advantage? Will it support calls from other ZK apps?
Outlook and Conclusion
ZK technology has two main use cases: privacy and scalability. When we discuss privacy, we are actually protecting off-chain data from being accessed; when we discuss scalability, we are using ZK to save on-chain computation space.
- The core trade-off in the development of ZKVM is between technology and developers. Focusing on leveraging ZK potential means hardware acceleration of CPU registers, reorganization of IR languages and assembly languages; while focusing on utilizing developer resources means addressing the issue of how to perform ZK proofs on the opcodes mapped from the bytecode after converting Solidity.
- Designing specialized ZK apps using assembly language independently will face significant obstacles in future development due to low composability and decoupling capabilities. These solutions are incompatible with other ZK solutions' VMs, languages, and proofs, leading to considerable invocation difficulties.
- According to the modular blockchain perspective, L1 solves the consensus problem, L2 addresses computation and execution issues, and the DA layer resolves data availability and integrity issues. Due to ZK-type solutions, data security and proof integrity determine the reliability of execution. There is a contradiction here; if we do not trust off-chain nodes and wish to hand over data to DA for independent storage, it raises security requirements for the DA chain; if there is local assurance that data is not tampered with, it requires proof that the nodes themselves do not act maliciously. All these increase the demand for MPC/FHE solutions.
- With most ZK solutions currently being closed-source, much consensus is still based on the self-discipline of off-chain nodes, lacking a series of necessary tools (testing, proof, etc.) to ensure the security of the off-chain environment. In the future, constraint design and algebraic proof will become the two main auditing processes.
- The main risks in the ZK ecosystem. Typical issues include: inadequacy of the constraint system. When proving some complex intersecting propositions, the constraints face inadequacy; private data leaks, treating private data as public; attacks on off-chain data, "metadata-attack" at the contract layer; malicious behavior of ZK proof nodes, etc.
- As different circuits continue to mature, Sequencer/Roller/Miner will also see efficiency improvements and specialization, and we look forward to opportunities for hardware acceleration of ZK proofs.
 Risk warning
Risk warning Risk warning
Risk warning











