

















ZONFF Research: What are we talking about when we talk about Web3 data?

 The usage paradigm of Web3 data is significantly different from that of Web2, primarily in the way data is aggregated, meaning that the storage, indexing, extraction, integration, and utilization methods for different types of data will vary.
The usage paradigm of Web3 data is significantly different from that of Web2, primarily in the way data is aggregated, meaning that the storage, indexing, extraction, integration, and utilization methods for different types of data will vary.Author: Lewis Liao, Zonff Partners
When we talk about Web3 data, what are we discussing? To clarify this question, we first need to understand what data looks like in Web2. This article will discuss the entire lifecycle of data generation, collection, storage, management, and usage. Before that, we need to clarify how data is defined.
The "Cybersecurity Standard Practice Guide - Data Classification and Grading Guidelines" (Draft for Comments - v1.0 - 202109) issued by the National Information Security Standardization Technical Committee of China classifies data into personal information, public data, and corporate data.
The specific definitions and examples are shown in the table below,
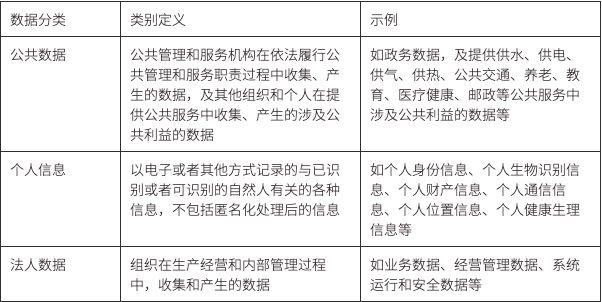
Above each category, data is further divided into five levels based on the harm caused by data breaches: Public Level (Level 1), Internal Level (Level 2), Sensitive Level (Level 3), Important Level (Level 4), and Core Level (Level 5). Public level data is more like a public product, being non-competitive and non-exclusive. This type of data is generally provided by government/public organizations, with benefits accruing to them, such as weather forecasts, macroeconomic data, etc.
1.1 Data Generation, Collection, and Storage
Most public data, personal data, and corporate data are generated while we use computer applications in our daily lives, with personal data and corporate data being particularly relevant to ordinary users.
So how are personal data and corporate data generated and collected? A highly abstract system architecture diagram of an internet product is shown below,
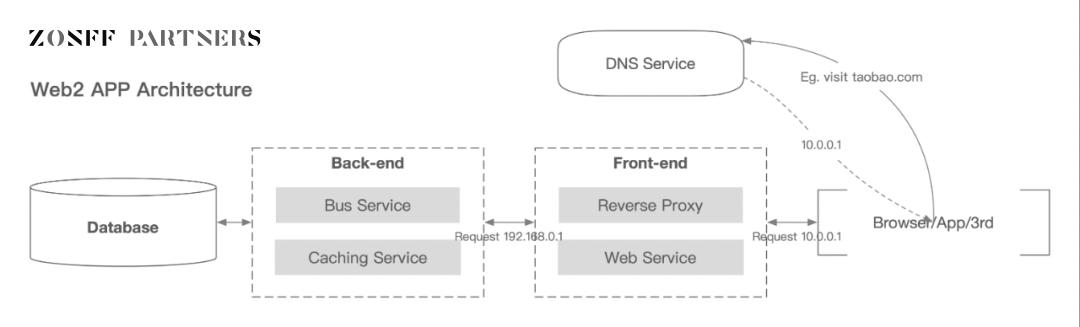
Web2 Application Architecture
Image Source: Zonff Partners
At the lowest level, the database stores data generated from user interactions with the frontend, transmitted from the backend. Broadly speaking, all of this is user data.
For mobile applications, data can generally be divided into the following categories:
- User Information: Information related to users recorded while using application services, including user identity information, devices, networks, geographic locations, and even a list of applications installed on mobile devices, collected through server data tables and tracking points;
- Content Data: Data produced by users while using application services, including any non-personal information content actively written by users in the application, which is part of the application service and generally collected directly by server data tables;
- Behavioral Data: Data generated from user interactions during application usage, including user behavior habits such as viewing duration, click-through rates, penetration rates, scrolling behavior, etc., generally collected through tracking points;
- Log Data: Data generated by the application itself during user usage, including application crash logs, etc.;
- Code Data: Non-user interaction data including frontend and backend code, which, like user data, is stored on a centralized server somewhere;
In this classification, user information belongs to personal data, while log and code data belong to corporate data. Notably, content data and behavioral data are often categorized as business data by centralized entities in the Web2 era, i.e., corporate data.
Is there anything different in Web3 applications? Preethi Kasireddy's Web3 product architecture can help us understand.
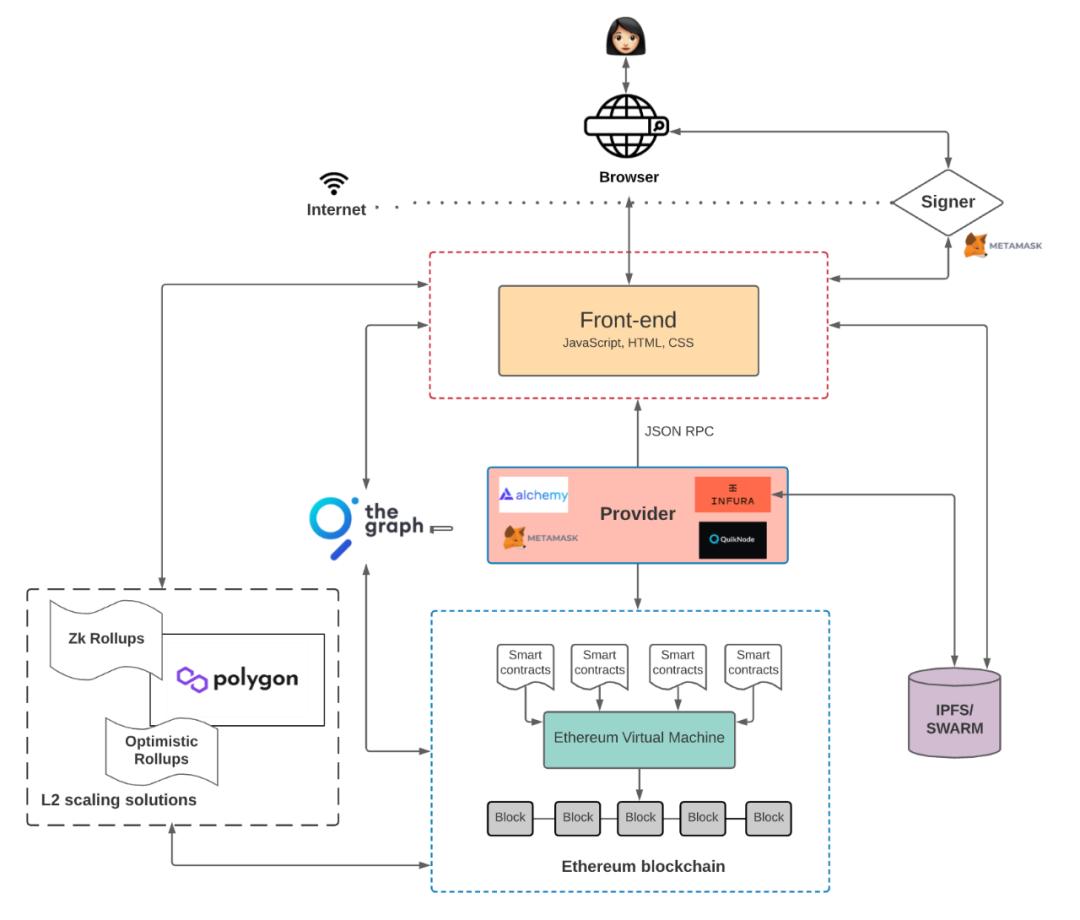
Web3 Product Architecture
Image Source: Preethi Kasireddy
Compared to Web2 applications, there is almost no change in the user terminal and frontend; the difference lies in the backend and database. Users interact with node providers through the frontend (rather than a centralized server), accessing contract code deployed on blockchains like Ethereum (rather than a backend environment on a server) and engaging in interactions. This process will also generate the aforementioned types of data. Due to the differences in technical architecture, the data generated in Web3 is not stored by a centralized server, and the storage methods for data generated in different ways may vary.
Data generated from interactions with smart contracts is published on the blockchain, accessible to anyone, thus becoming a public product. This includes asset information, transaction data, and contract code. Theoretically, as long as there is enough block space on the blockchain, any data can be stored on the blockchain, and some projects are even attempting to use the blockchain as a database for data storage.
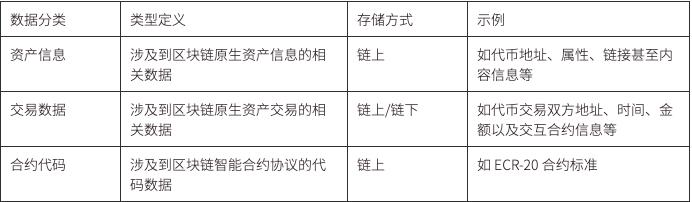
At the current stage, the data generated by a Web3 application, aside from the three types mentioned above, still mostly adopts centralized server storage methods, including frontend code, user information, content data, behavioral data, and log data. This is due to the current inadequacies in related storage infrastructure, where project teams may be limited by technical issues or choose centralized solutions for reasons such as ensuring access speed. With the continuous development of infrastructure, many increasingly powerful storage infrastructures have emerged, such as IFPS, Stroj, Filecoin, and Ceramic, and more applications have begun deploying themselves on decentralized storage, such as hosting frontend websites on IPFS and accessing them via ENS, thereby building a decentralized website frontend and using Arweave for permanent storage of images and files corresponding to NFT projects, etc.
In summary, when building a Web3 application, developers typically have three choices for data storage:
- Store it on the blockchain; this choice is very expensive, leading to applications being as simple as possible, and the data is completely public. The benefit is that it directly protects application sovereignty;
- Store smart contract logic on the blockchain, while other data resides on traditional backends. This method sacrifices user sovereignty and carries centralization risks. This is the approach adopted by most Web3 applications currently;
- Store smart contract logic on the blockchain, while other data is stored on IPFS, Arweave, and Ceramic, managing and updating data through smart contracts. This method is relatively expensive (Ceramic is currently free) and somewhat slow, but it can protect application sovereignty;
Currently, the vast majority of Web3 applications are built using the second method, while some specific applications can already use the third method, and very few applications are built using the first method. So, which storage method should we choose? What kind of storage method is the trend?
1.2 Trend: Decentralized Storage - Data and Application Sovereignty
When discussing the three ways to build Web3 applications, there is a key term: sovereignty. This term is an unavoidable topic when we talk about the characteristics of Web3, generally including data sovereignty and application sovereignty. So, is sovereignty important? This is another topic that will not be explored here; interested readers can refer to related articles such as "Prospects for Web3 Data Markets" and "Web3 - Let the 'Right to Data' Awaken." Here, I want to approach the establishment of Web3 sovereignty from the perspective of data and deduce the direction and focus of infrastructure development.
Regarding data sovereignty, including digital asset sovereignty and user data sovereignty, the article "Vertical Liquidity: How Value Interconnects" discusses how tokens can define users' digital asset sovereignty (identity, relationships, and property rights), determined by a difficult-to-alter broad consensus. At its most basic level, these rights can be defined by the blockchain itself, such as which address a token belongs to. However, once it involves more complex rights to digital products, many issues arise, a typical example being the storage issue of images (or articles, etc.) corresponding to NFTs, which is discussed in "NFT: The Revolution of Digital Ownership." The current state of most NFTs is that their corresponding digital products are stored on a centralized server somewhere; if that server crashes or is hacked, what users own is merely a string of on-chain hashes, while the actual "item" behind the hash can be stolen or replaced at any time, rendering it worthless.
Moreover, user data sovereignty, as one of the most obvious dividing lines between Web2 and Web3, is the banner for innovation and progress in Web3. In this regard, Ceramic envisions a data universe, a composable, network-scale data ecosystem owned by everyone but not exclusively owned by anyone. User data follows users from one application to another, with users at the center controlling their digital universe. Currently, there are almost no applications that can achieve this; Cyberconnect has made a good attempt by creating a decentralized social graph protocol, hoping to achieve interoperability of user social relationship data across applications. However, at this stage, the application does not guarantee user data sovereignty, even though they have begun transitioning to build on Ceramic; everything is still a work in progress.
Regarding application sovereignty, some refer to sovereign applications as "superstructures," characterized by being unstoppable, free, valuable, scalable, permissionless, having positive externalities, and being credibly neutral. Together, these provide a public product for the digital world, laying the foundation for the "metaverse" (if you believe in it). Currently, the vast majority of so-called Web3 applications have low levels of application sovereignty; they are not truly public products and can easily be sanctioned and altered by powerful entities. The Tornado Cash incident directly illustrates this issue. One of the main reasons is that although the contract code of these application protocols is published on the blockchain, components such as the frontend and domain names are still controlled by third-party centralized entities.
To achieve data sovereignty and application sovereignty, the construction method of Web3 applications is crucial, with the foundational starting point being storage. Where data is stored and how it is stored to ensure users can have sovereignty? In general, different solutions can be proposed based on the type of user data:
- User asset information and transaction data should be public ledger data, stored on-chain to ensure verifiability, but applications like Aztec that ensure user privacy in on-chain transactions are very valuable;
- User information, content data, and behavioral data as personal information must ensure user control; with user consent, these data can be selectively made public as public products to explore positive externalities;
- Log data and code data as corporate data can be privatized, which is acceptable and somewhat necessary, but applications of "superstructure" type Web3 infrastructure should possess characteristics of public infrastructure, and the storage of application code should be public and have resistance to censorship beyond platform level;
Currently, most Web3 applications adopt the method of "storing smart contract logic on the blockchain, while other data resides on traditional backends" because there are not yet sufficiently usable decentralized infrastructure solutions to replace the original centralized infrastructure plans.
Firstly, decentralized storage solutions like IPFS, Filecoin, and Arweave are all static storage, which makes them lack computational and state management capabilities, unable to achieve more advanced database-like functions (such as mutability, version control, access control, and programmable logic). Although Ceramic is dynamic storage and has solved some of these issues to a certain extent, its access speed remains relatively slow, and its development toolkit is not yet comprehensive, and its degree of decentralization has also been criticized.
The main role of decentralized storage solutions like IPFS, Filecoin, and Arweave is to statically store unstructured data such as images, documents, and static code, as their difficult-to-alter characteristics provide a certain degree of assurance for digital sovereignty like NFTs. Once the connection between on-chain hash codes and off-chain decentralized storage addresses is established, it is difficult for external forces to influence them through extreme means. Hosting frontend code on top of this also promotes the integrity of application sovereignty, but due to the current stage of storage technology being merely storage, the lack of computational capabilities leads to its functional support lagging far behind centralized server solutions.
The current mainstream decentralized storage situation in the market is shown in the table below, which is summarized and updated based on "The Evolution of Decentralized Storage in Web3,"
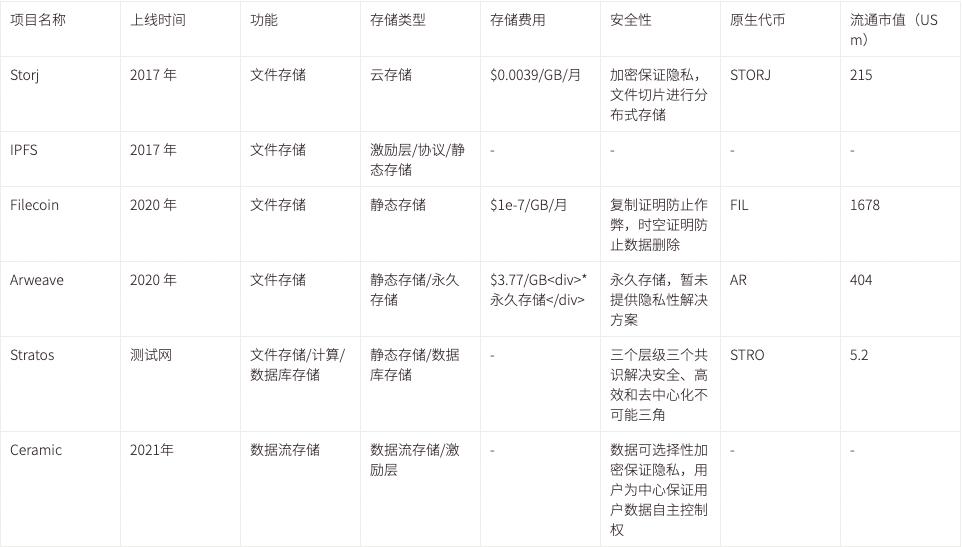 Data Source: CoinmarketCap
Data Source: CoinmarketCap
Date: August 23, 2022
Currently, most storage solutions have only achieved a "decentralized hard drive," meeting the most basic needs, while more advanced storage-based computational needs have not been fully met. These computations include local development environment rendering, data stream insertion and extraction, etc., which are the most commonly used and necessary functional modules in current Web2 applications. Ceramic's innovation based on data stream storage enables permission management, version control, dynamic storage, and composability, while Stratos is attempting to provide a more comprehensive, all-in-one solution, including database storage, static storage, computation, and consensus modules. Additionally, Arweave and Filecoin have also recognized the importance of computation and are either building or encouraging the construction of related modules in their ecosystems, such as Filecoin's launch of FVM to support computation on Filecoin.
2.1 Data Management
Building Web3 applications on decentralized storage makes them less susceptible to external interference, breaking monopolies and powerful entities. However, mere storage is not enough; support from technologies such as rendering computation, data processing, permission configuration, and privacy protection in the storage environment is also needed to ensure application sovereignty and user data sovereignty, thus realizing the rise of personal sovereignty in the digital world. Especially regarding permission control and privacy protection issues, they should be implemented through a high-level sovereignty technology solution. In Web2 applications, these levels of data are stored on specific centralized servers according to different security protection levels, with their security guaranteed by network security and their sovereignty guaranteed by the platform (such as corporate platforms, government platforms, etc.). In this data management model, users are subject to super administrators, and users have no rights over the data itself. Moreover, data security is also subject to the centralized entity of the super administrator; for instance, a recent incident involving police data leakage in a certain region occurred when a super administrator leaked their private key, resulting in the exposure of personal confidential information of hundreds of millions of people.
Web3 data management should have the following two major characteristics:
- Data Sovereignty Assurance. This should transcend platform-level and even reach world-level, ensuring a common power for users in the digital world through world-class consensus. In the traditional world, this aspect of assurance is platform-level, and the rules come from non-consensus; a single platform-level company can control all rules and systems and can change them at any time, thus infringing on users' personal sovereignty at any time;
- Data Privacy Assurance. This should mathematically guarantee user data privacy through cryptography, rather than relying on database network security methods for protection. User-controlled selective encryption is one of the basic rights of user data sovereignty;
How to manage Web3 data depends on how that data is stored.
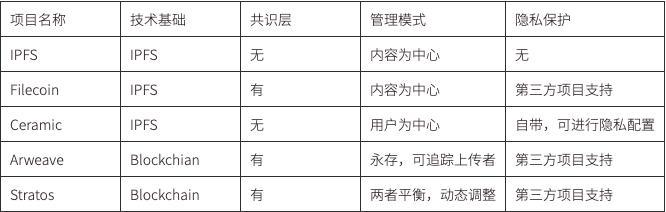
IPFS and Filecoin are content-centric, accessing stored content through Content ID (CID). On this basis, third-party applications can be built for data management; for example, through ChainSafe Files, after solving the single sign-on issue in a localized manner, data can be conveniently encrypted for storage using asymmetric encryption. The content-centric management model makes user management difficult, complicating the assignment of ownership to data. In addition to providing storage, Filecoin's ecosystem is much more extensible than other underlying solutions. Especially after the upcoming launch of FVM, there may be some specialized tools for data storage and retrieval in vertical fields that can help users and enterprises better manage their data and ensure its security, leading to the development of many new applications.
Ceramic is also based on IPFS but is user-centric, building a Ceramic-native account system based on IDX Protocol and 3ID DID method (CIP - 79), which can be used for authentication on Ceramic. Users can control the 3ID DID to execute transactions on the data stream and manage their data using a blockchain wallet. This is achieved by associating the DID with data and storing it in a data model, which defines the format (schema) of user data. Any application using the same data model shares that data format.
Arweave is a decentralized storage project for on-chain data with a one-time payment for permanent storage, with data stored transparently on-chain and accessible to anyone. The data management model under this mode is identical to managing on-chain data, lacking access control and "hot updates" for original data; each time data is updated, its index address changes. This is not an issue for IPFS and Filecoin, but the benefit is that it is very clear which user the data belongs to, facilitating the tracing of data rights.
Stratos is also based on blockchain consensus storage, maintaining an index tree to record the path of data storage, thus keeping track of data updates. Unlike Arweave, each storage node (Resource Node) in Stratos is designed to have computing power, storage, and content access control services simultaneously. The project itself will build a database based on the blockchain for dynamic data throughput, making its form and management model similar to decentralized cloud computing.
2.2 Trend: Decentralized Data Market
With users owning data ownership, a data market is an inevitable trend, where data circulates as a capital factor. There have been attempts at data markets on Filecoin; Fivehive, built and maintained by the decentralized application development studio OB1, is an open-source market supporting the uploading, maintenance, purchase, and (or) transfer of datasets. The project's GitHub has not been updated or maintained for two years, likely indicating failure.
Ceramic's Data Model Market
Ceramic has mentioned in its data universe that it aims to create an open data model market, as data needs interoperability, which can greatly enhance productivity. Such a data model market is realized through urgent consensus on data models, similar to the ETC contract standard in Ethereum, allowing developers to choose from it as a functional template, thus having an application that conforms to that data model. Currently, this market is not a trading market.
Regarding data models, a simple example is that in a decentralized social network, the data model can be simplified into four parameters, namely:
- PostList: Index of user posts
- Post: Storage of a single post
- Profile: Storage of user profiles
- FollowList: Storage of user follow lists
So how can data models be created, shared, and reused on Ceramic to achieve cross-application data interoperability?
Ceramic provides a DataModels Registry, which is an open-source, community-built repository for reusable application data models for Ceramic. Here, developers can publicly register, discover, and reuse existing data models—this is the foundation for building client applications based on shared data models. Currently, it is based on GitHub storage, and in the future, it will be decentralized on Ceramic.
All data models added to the registry will be automatically published under the npm package @datamodels. Any developer can install one or more data models using @datamodels/model-name, making these models available for use at runtime with any IDX client for storing or retrieving data, including DID DataStore or Self.ID.
Additionally, Ceramic has also built a DataModels forum based on GitHub, where each model in the data model registry has its own discussion thread, allowing the community to comment and discuss. This forum can also be used by developers to post ideas about data models, seeking community feedback before adding them to the registry. Currently, everything is in the early stages, and there are not many data models in the registry. Data models entering the registry should be evaluated by the community to become CIP standards, similar to Ethereum's smart contract standards, providing composability for data.
Ocean's Data Trading Market
Ocean Protocol centers around a data trading market, establishing a decentralized data service supply chain network. The diagram below shows the main services required to create a data service supply chain, providing data, algorithms, computation, storage, analysis, and curation. These components are bound together with service execution agreements (such as service level agreements), secure computation, access control, and permissions.
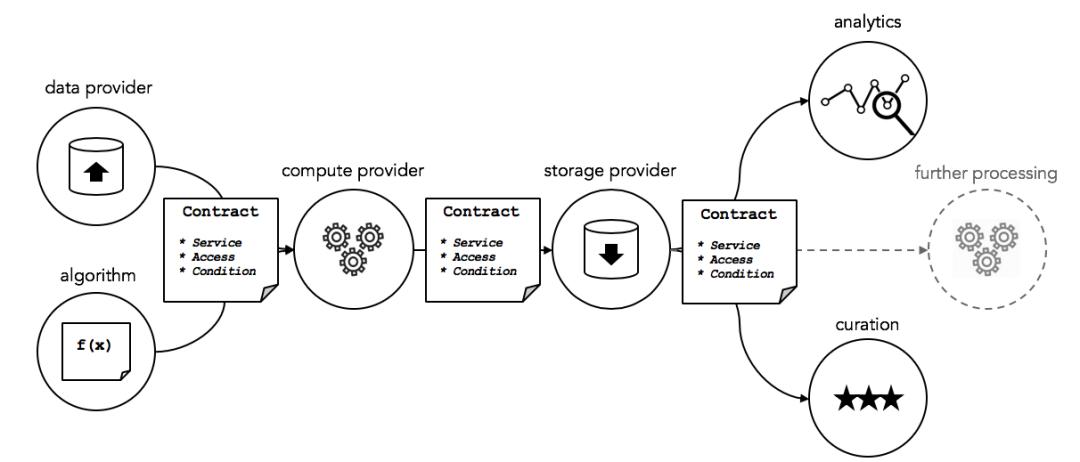
Image Source: Ocean Protocol
The main participants include data users, service providers, markets, service publishers, validators, and curators. Ocean provides a full suite of data science tools, allowing data users to establish data service pipelines on Ocean to automate data algorithms for processing and value discovery. In this process, data users cannot download the entire dataset or see the entire dataset, thus protecting the dataset from theft; users purchase the right to use the dataset rather than owning it.
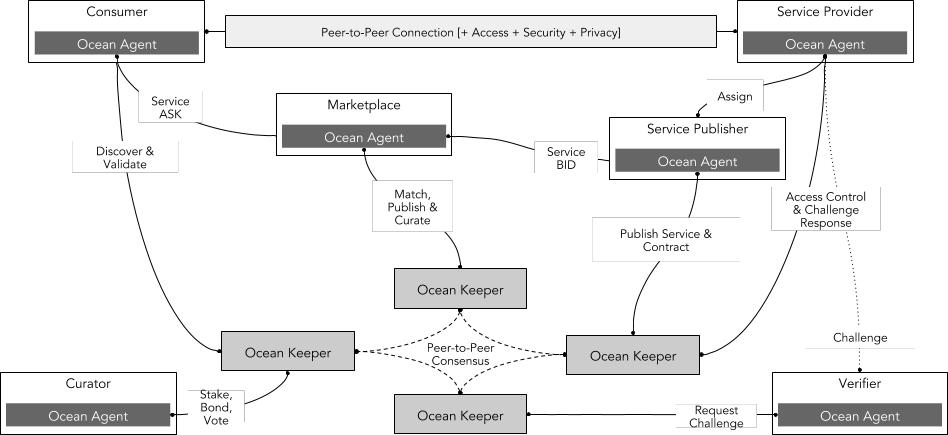
Source: Ocean Protocol
In addition, Ocean has collaborated with other institutions to establish data markets, such as its decentralized data market Acentrik in partnership with Mercedes-Benz in its recently launched Enterprise Release. Acentrik Marketplace is powered by OceanONDA V4 smart contracts and libraries, allowing the publication of data services, deployment and minting of data tokens, and Acentrik asset management tokens, consumable through expenditure on data services.
3.1 Data Usage and Stack
Based on the understanding of the above content, we propose the Web3 data stack, as shown in the diagram below,
- The bottom layer is where data sources are stored, including decentralized storage, on-chain and off-chain data, etc.;
- The next layer includes management applications for this data, such as databases, data tables, index middleware, and data markets;
- Under a certain data management paradigm, data can be mined, including algorithm modeling, statistical analysis, and data visualization;

Web3 Data Stack
Image Source: Zonff Partners
Currently, in the industry regarding Web3 data usage, the vast majority is on-chain data, with a plethora of data analysis and indexing tools emerging; this massive gold mine of on-chain data has been fully mined, and most of the data tables and analysis applications in the above diagram pertain to on-chain data mining, with only a small portion involving off-chain data. In general, the data usage link is an ETLA (Extract, Transform, Load, Analysis) process, with representative projects at each node. The representative project for extraction (Extract) is The Graph, while the representative projects for transformation (Transform) into usable data tables and loading (Load) are Dune and Luabsae, and the representatives for analysis (Analysis) are Nansen and NFTGO.
In decentralized storage, however, there are almost no projects supporting the entire ETLA process, with only a few extraction-type projects, presenting huge opportunities and challenges. The Graph and the Ceramic community are working to extract data from Ceramic, and the founder of Orbis has also attempted to create a Cerscan for browsing data on Ceramic. Arweave can already read and manage data stored on Arweave through The Graph, and there are also relevant third-party projects doing this on Filecoin. However, the TLA process is currently neglected, with the main reason being the high heterogeneity of data stored on different decentralized storages, making it difficult to have a unified model to mine the value of this data. The most promising to take this step is Ceramic, as its data model significantly reduces the heterogeneity of data on Ceramic, thus increasing the usability of the data.
In addition to on-chain data, many projects are attempting to bridge on-chain data with off-chain data, which can be seen as "chain reform" type projects.
Type classifications include:
- Web2 Data Sovereignty Empowerment and Trading Market: Projects like Itheum, Navigate, Swash, and Phyllo. These projects primarily aim to combine traditional internet data with on-chain data, hoping to facilitate information exchange between Web2 and Web3, commonly by exporting Web2 data and importing it into designated data pools or directly binding traditional internet social accounts, etc.;
- Enterprise Data Consensus: Authtrail, which integrates with internal enterprise databases, adding a consensus layer to achieve data tamper-proofing and traceability within enterprises;
- On-chain and Off-chain Data Combination: Space and Time, which, like Authtrail, integrates off-chain databases but lacks a consensus layer, focusing more on joint computation of off-chain and on-chain data; additionally, Pool is doing similar things;
The usage paradigm of Web3 data differs significantly from Web2, mainly in how data is aggregated, meaning that the storage, indexing, extraction, integration, and utilization methods for different types of data will vary. Based on the previous classifications, here is a simple summary:
Public Data: Including public data and some corporate data classified in the "Cybersecurity Standard Practice Guide - Data Classification and Grading Guidelines." As a public product, it is data that can be publicly mined for value, with access requiring no permission but allowing for the tracing of user ownership, thus tracing airdrop profit-sharing. Typical examples include on-chain data and non-encrypted application data stored in decentralized storage (such as user posts, likes, and comments). The most important upstream support for its use is indexing applications, such as The Graph, or applications of Web3 native databases, such as Tableland.
Private Data: Including personal information and some corporate data classified in the "Cybersecurity Standard Practice Guide - Data Classification and Grading Guidelines." As a type of data that requires encrypted storage and certain privacy permission configurations, its access requires permission and cannot be publicly obtained. If stored in decentralized storage and on the blockchain, it requires permission-configurable encrypted storage, or it can be protected through other means, such as privacy technologies like ZK, MPC, and TEE. The most important upstream support for its use is database applications, such as Kwil and Ceramic.
 Risk warning
Risk warning Risk warning
Risk warning










