

















The Predicament of AIGC and the Path for Web3 to Break the Circle

 In the process of universal AI image generation, artists seem to stand on the opposite side.
In the process of universal AI image generation, artists seem to stand on the opposite side.Written by: wheart.eth

Image source: Generated by Wujie Map AI Tool
In the past year, with the development and growth of AIGC (AI-Generated Content) technology, more and more people have felt its terrifying aspects. AI has lowered the barriers to creation, giving every ordinary person the opportunity to showcase their creativity and produce works that rival professional standards. However, in the process of universal AI image generation, artists seem to have found themselves on the opposing side.
Industry giants represented by Stable Diffusion and Midjourney are often met with collective resistance from artists! The reasons boil down to two points: first, these models use artists' works for training without permission, producing images that closely resemble the artists' styles, which raises copyright concerns; second, some traditional artists believe that AI merely performs simple stitching of images and cannot be considered art, and its misuse has led to turbulence in the art market, resulting in a phenomenon of "bad money driving out good."
Overall, the current AIGC market resembles a giant carrying a bomb; it appears very powerful on the outside, but there are unresolved fatal threats within. If this threat is not eliminated, the development of the industry will ultimately be limited. This article will discuss in detail the causes and consequences of this situation and propose possible solutions.
Recently, more and more painters have discovered that their own works are included in the datasets used by AIGC models like Stable Diffusion, and many of these works have been developed over decades into unique styles. Now, people can use AI to generate content in the same style within seconds, which is clearly unfair to artists.

(Left: AI-generated image, Right: Original artwork by the artist)
This has raised serious concerns among artists: their own art is being used to train a computer program that may one day affect their livelihoods. More urgently, anyone using systems like Stable Diffusion or DALL-E to generate images holds copyright and ownership over the generated images (specific terms may vary). An illustrator explained: people will use AI to generate book covers, article illustrations, and other content, which threatens their livelihoods. After all, from the buyer's perspective, when you can freely choose from 1,000 images, why pay $1,000 to the creator? Moreover, all of this is happening without the artists' knowledge.
In response to this issue, Emad Mostaque, founder and CEO of Stability AI, stated that art constitutes only a small part of the LAION training data behind Stable Diffusion, with artistic images making up far less than 0.1% of the dataset, and they are only created when users choose to invoke them. However, some search tools have collected data indicating that many works by living artists are indeed included in the dataset, with thousands of artworks being quite common.
Is technology the original sin?
The emergence of this issue is not accidental but inevitable, and it is a problem that AI development cannot avoid. To understand the reasons in detail, we might gain some insight through the principles and development paths of AIGC technology.
AIGC utilizes artificial intelligence technology to generate content. Before 2021, AIGC primarily generated text (ghostwriting), while the new generation of models can handle various formats of content, including text, sound, images, video, actions, and more. AIGC is considered a new type of content creation method following professional-generated content (PGC) and user-generated content (UGC), capable of fully leveraging technological advantages in creativity, expressiveness, iteration, dissemination, and personalization. The development speed of AIGC in 2022 was astonishing; it transitioned from a novice stage at the beginning of the year to a professional level within a few months, capable of producing images that are indistinguishable from real ones.
The "Generative Adversarial Network" (GAN) proposed in 2014 was a popular deep learning model in recent years and can be considered a practical framework for AIGC (it was still a mainstream research topic at the end of last year).
The basic principle of GAN is quite simple, illustrated here with image generation as an example. Suppose we have two networks, G (Generator) and D (Discriminator). As its name suggests, G is a network that generates images; it receives a random noise z and generates an image, denoted as G(z). D is a discriminative network that determines whether an image is "real." Its input parameter is x, representing an image, and the output D(x) indicates the probability that x is a real image. If it is 1, it means it is 100% a real image; if the output is 0, it means it cannot be a real image. During training, the goal of the generator network G is to generate images that can deceive the discriminator network D into thinking they are real. Meanwhile, D's goal is to distinguish between images generated by G and real images. Thus, G and D form a dynamic "game process." What is the final outcome of this game? In the ideal state, G can generate images that are "indistinguishable from real." For D, it becomes difficult to determine whether the images generated by G are real, hence D(G(z)) = 0.5.
Thus, our goal is achieved: we have obtained a generative model G that can be used to generate images.
However, GAN has three shortcomings: first, it has weak control over output results, making it prone to generating random images; second, the resolution of generated images is relatively low; third, since GAN requires a discriminator to judge whether the generated images belong to the same category as other images, this leads to generated images being imitations of existing works rather than innovations. Therefore, it is difficult to create new images based on the GAN model, and it cannot generate new images from text prompts.
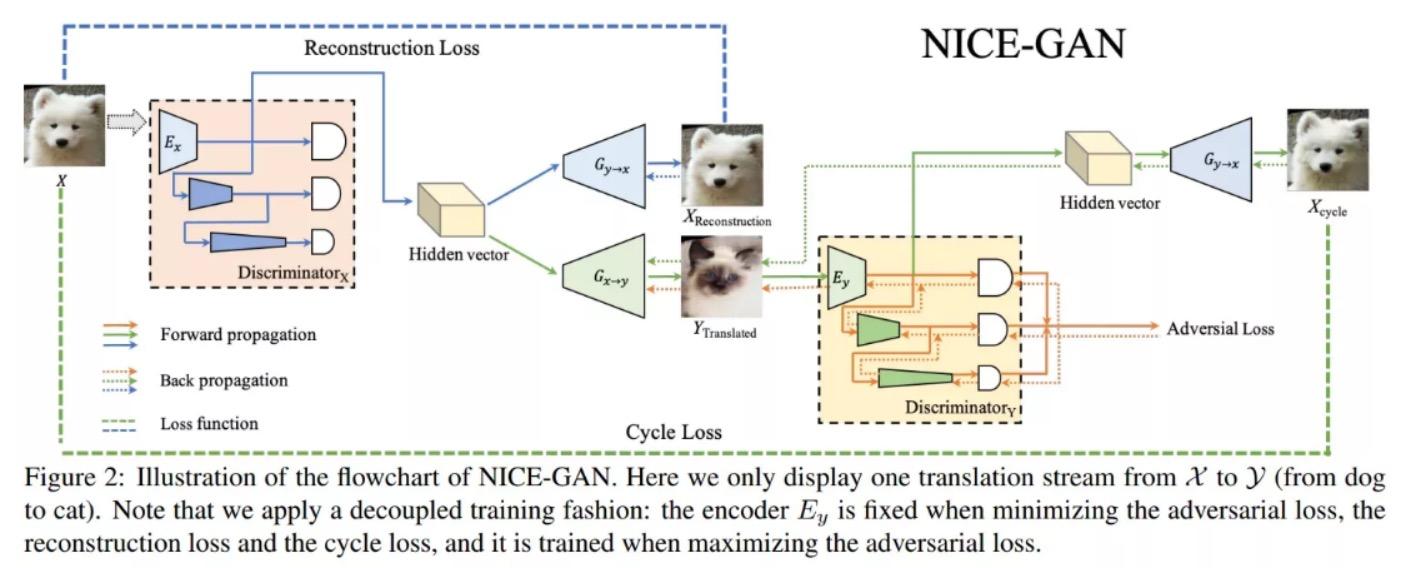
GAN Technical Principle
In 2021, the OpenAI team open-sourced the cross-modal deep learning model CLIP (Contrastive Language-Image Pre-Training). The CLIP model can associate text and images by first collecting a dataset of 400 million uncleaned image-text pairs for pre-training to complete the task. It trains using a contrastive learning objective: encoding images and text separately (text being a complete sentence), then calculating cosine similarity pairwise, and classifying for each row of images or column of text to find matching positive examples. Each image has 32,768 text candidates, which is twice that of SimCLR, and the increased number of negative examples is one reason for its effectiveness. The prediction process is also straightforward: find an image classification dataset, convert the label into natural language (for example, "dog" can be converted to "a photo of a dog"). Then, use the pre-trained encoder to encode the label and the image, and calculate the similarity.
The overall process of the algorithm can be summarized as follows: input an image, predict which of the 32,768 randomly sampled text segments actually pairs with the dataset. Since the text description is not a specific category, it can perform zero-shot on various image classification tasks, where Zero-Shot is a form of transfer learning. For instance, to describe a zebra, one can use "the outline of a horse + the fur of a tiger + the black and white of a panda" to generate a new category. Ordinary supervised classifiers can correctly classify images of horses, tigers, and pandas, but when faced with a photo of a zebra that they have not learned about, they cannot classify it. However, the zebra shares commonalities with the classified images, allowing for the inference of this new category.
Thus, the idea is to set more finely-grained attributes to establish a connection between the test set and the training set. For example, converting the feature vector of a horse into semantic space, where each dimension represents a category description, [has a tail 1, horse outline 1, has stripes 0, black and white 0], while a panda would be [has a tail 0, horse outline 0, has stripes 1, black and white 1]. This way, a zebra's vector can be defined, and by comparing the similarity between the input image's vector and the zebra vector, discrimination can be made.
Therefore, the CLIP model has two advantages: on one hand, it simultaneously performs natural language understanding and computer vision analysis, achieving image and text matching. On the other hand, to have enough labeled "text-image" pairs for training, the CLIP model extensively utilizes images from the internet, which generally come with various text descriptions, becoming natural training samples for CLIP. It is estimated that the CLIP model has collected over 4 billion "text-image" training data from the web, laying the foundation for subsequent AIGC applications, especially for generating images/videos from input text.
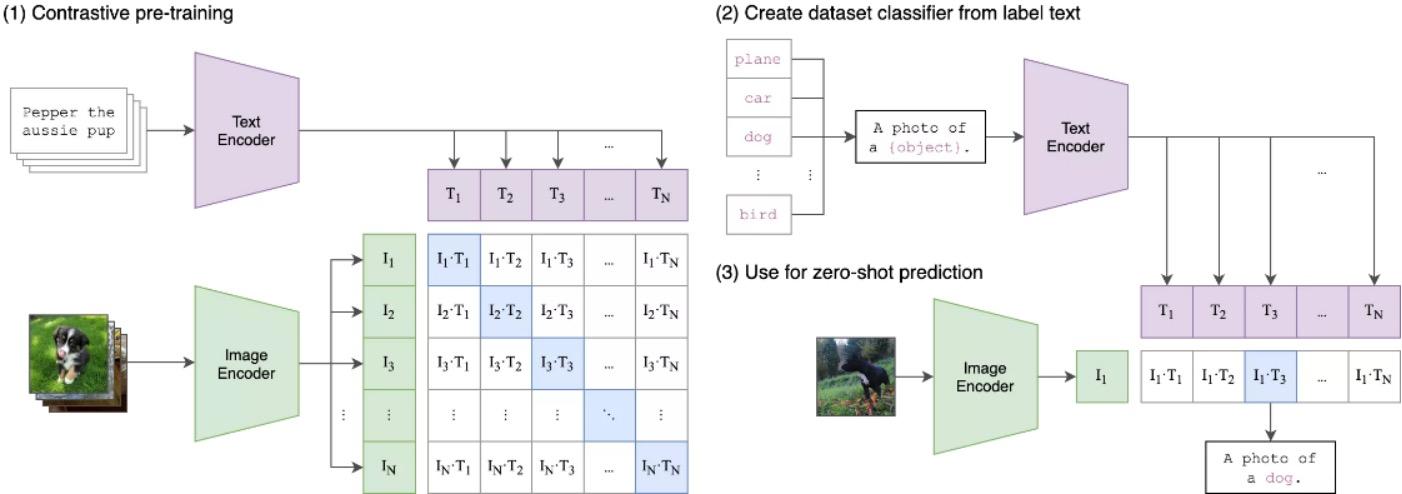
CLIP Technical Principle Diagram
The subsequent emergence of diffusion models truly made the AIGC application of text-to-image generation known to the public and is also a crucial technical core of Stable Diffusion applications in the second half of 2022.
The inspiration for diffusion models comes from non-equilibrium thermodynamics. It defines a Markov chain of diffusion steps (where the current state only depends on the previous state), gradually adding random noise to real data (the forward process), and then learning the reverse diffusion process (the reverse diffusion process) to construct the desired data samples from noise.
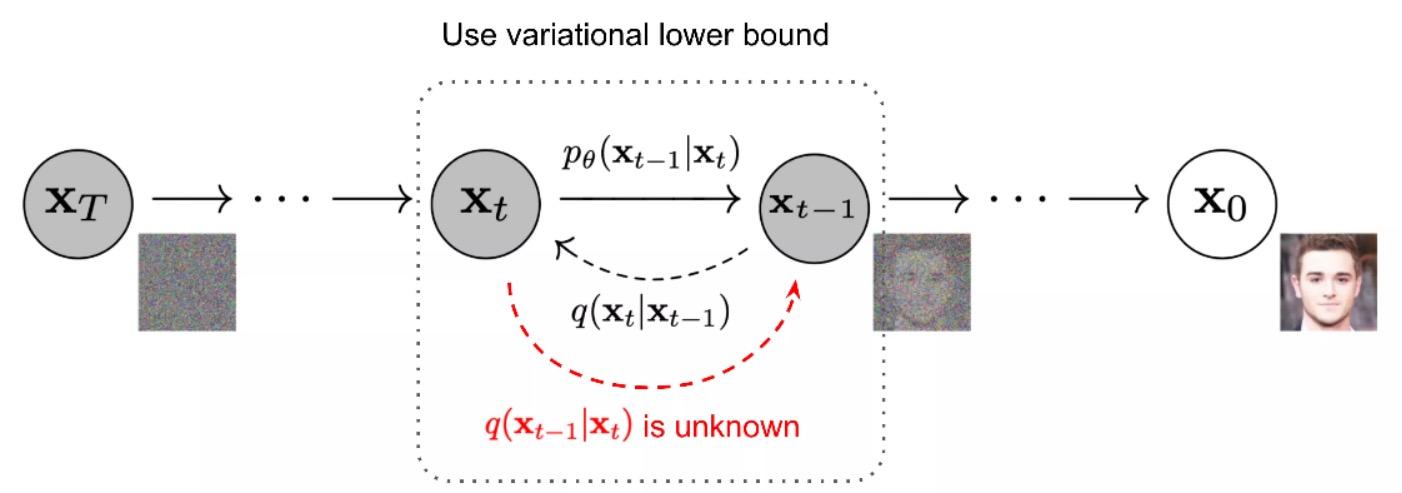
Diffusion Models Technical Principle Diagram
The forward process is a continuous noise-adding process, where the noise added increases with time steps. According to the Markov theorem, the correlation of this moment after noise addition is highest with the previous moment and is related to the noise being added (whether the influence of the previous moment is greater or the influence of the added noise is greater; as the forward moment progresses, the weight of the noise influence increases because initially adding a little noise is effective, but later, more noise needs to be added).
The reverse process starts from a random noise and gradually restores it to the original image without noise—denoising and generating data in real-time. Here, we need to know the entire dataset, so we need to learn a neural network model (currently mainstream is U-net + attention structure) to approximate these conditional probabilities to run the reverse diffusion process.
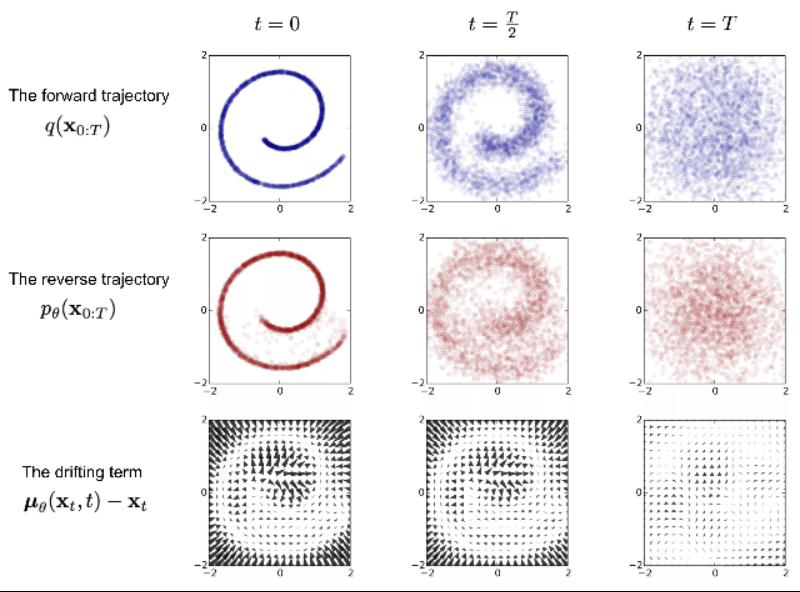
Diffusion Models Reverse Process
Diffusion models have two characteristics: on one hand, they add Gaussian noise to images, learning by destroying training data, and then finding out how to reverse this noise process to restore the original image. After training, the model can synthesize new data from random inputs. On the other hand, Stable Diffusion transforms the model's computational space from pixel space into a low-dimensional probability space through mathematical transformation, significantly reducing computational load and time, greatly improving model training efficiency. This innovative algorithmic pattern has directly driven breakthrough progress in AIGC technology.
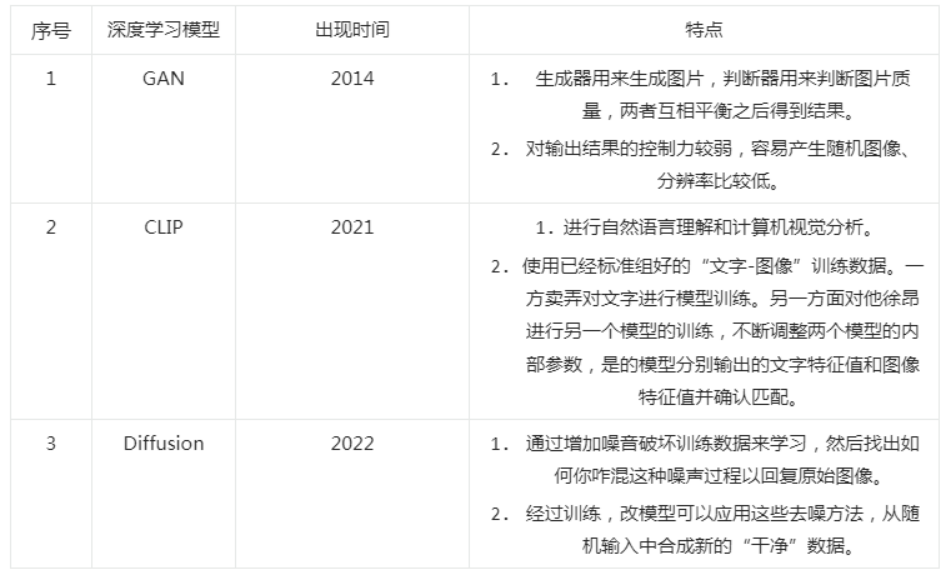
Summary of AIGC-related Deep Learning Models
Vulnerabilities!
From the above algorithm introduction, it is clear that AIGC is essentially machine learning. Since this is the case, it cannot avoid using large datasets for training, and within this, there are indeed interests that harm the rights of image copyright holders.
Although we all know this situation exists, it is still very difficult to resolve.
For artists, while they believe these platforms infringe on their rights, there are currently no comprehensive legal provisions for such infringement, and in some legal texts, such actions are even legal.
On one hand, AIGC is difficult to be called an "author." Copyright law generally stipulates that authors can only be natural persons, legal persons, or unincorporated organizations. Clearly, AIGC is not a legally recognized rights holder, so it cannot be the subject of copyright. However, there are differing views on the copyright issues of images generated by AIGC; it is still unclear whether the images belong to the platform, are completely open-source, or belong to the generator.
On the other hand, the "works" produced by AIGC remain controversial. Traditionally, a work refers to an intellectual achievement that is original and can be reproduced in some tangible form in the fields of literature, art, and science. AIGC's works exhibit strong randomness and algorithmic dominance, making it difficult to accurately prove the possibility of AIGC works infringing. Additionally, whether AIGC has originality is currently hard to generalize, as individual cases vary greatly.
Even if one now deletes their works from the dataset, it cannot prevent the generation of works in their style. First, the AI model has already been trained and has mastered the corresponding style. Moreover, due to OpenAI's CLIP model (which trains Stable Diffusion to understand the relationship between text and images), users can still invoke specific artistic styles.
For AI project parties, it is unrealistic to obtain authorization for every image in the dataset. If such legislation passes, the development of the AI industry will face significant obstacles, possibly even a catastrophe. Therefore, we need a compromise solution.
Solutions?
First, let's analyze the creative closed loop of AIGC:
In terms of creative conception, AIGC has built a new pathway for creative enhancement. In the traditional creative process, digestion, understanding, and repetitive tasks are expected to be handled by AIGC, ultimately transforming the creative process into a "creativity-AI-creation" model.
In terms of creative realization, the relationship between creators and AIGC is similar to that between photographers and cameras. Photographers construct shooting ideas and plans, configure camera parameters, but do not need to understand the camera's working mechanism, generating high-quality content with a single click. Similarly, creators conceive and plan, configure AI models, and do not need to understand the model's principles; they can directly click to output content. Creativity and realization present a state of separation, and the realization process becomes a repeatable task that can be completed by AIGC, gradually pushing costs towards zero.
Thus, there are two major subjects here: creators and AIGC. Creativity is important, and creation is equally important. The images produced by AI represent the "creative copyright" of the creator, while the "underlying creative/creation copyright" belongs to AIGC or the artistic style adopted. Both should have rights to the generated content, but currently, the artist's share of the profits is missing.
In fact, artists do not mind AI learning from their works; they simply want to receive corresponding benefits. Therefore, as long as this design is recognized by the artists, the vulnerabilities of AIGC can be repaired.
The results of creators are the objects of AIGC's learning, but the creativity of creators is key. The creativity itself is more valuable than the paintings generated by AIGC, so how to quantify and even price the creator's "creativity" will help build the business model of AIGC. In this, the "attention mechanism" will become a potential quantification carrier for AIGC. For example, some institutional experts suggest that by calculating the area and intensity of the painting influenced by keywords in the input text, we can quantify the contribution of each keyword. Then, based on the generation cost and the artist's contribution ratio, we can determine the value generated by the creator. Finally, sharing profits with the platform proportionally would theoretically yield the earnings generated by the creator's contribution of creativity.
For instance, if an AIGC platform generates tens of thousands of works within a week, and there are 30,000 works related to this creator's keywords, with an average contribution of 0.3 per piece and a generation cost of 0.5 yuan per AIGC painting, with the platform taking a 30% cut, then this creator's earnings on the platform for that week would be: 30,000 * 0.3 * 0.5 * (1 - 30%) = 3,150 yuan in earnings. In the future, participating in the establishment of AI datasets may become an additional source of income for artists.
However, the above design also has flaws, as AI is not perfect, and not every image has value. Therefore, an optimized solution could be to not pay artists during generation, but only require payment when they wish to download satisfactory content. This also resembles the traditional art creation process, where the client places an order, and the provider receives full payment upon delivering satisfactory work.
To make the process more compliant, a more perfect approach would be to first publicly open the style library to global artists, allowing each artist to choose whether to include their works in the training set gallery. If included, they could earn corresponding benefits when other users create in the corresponding style. This also seeks new revenue streams for artists. In a market where "infringement" is so prevalent, this "legitimate authorized" gallery would undoubtedly receive support from the artist community, creating a more positive and virtuous model.
Web3?
Web3 has consistently emphasized the "creator economy," which aligns with the issues AIGC aims to address. Utilizing blockchain technology, it is entirely possible to create an ecological network centered around AIGC.
Creators can exponentially amplify their creativity and influence through the empowerment of AICG, combined with the economic model under the Web3 paradigm. This also allows more people to transition from consumers to participants, from users to owners. At the same time, artists can receive their earned share of profits, achieving a win-win situation.
In fact, Web3 + AI is not a novel concept; the leader in generative art NFTs, Art Blocks, serves as a successful application case. (Although the algorithms differ, they still resonate in essence.)
Art Blocks is a platform for generating random artworks. Launched by Erick Snowfro in 2020, it focuses on programmable, generative content, with the generated content being immutable on the Ethereum blockchain. So how is "random art" random? This random process is controlled by a string of numbers stored on a non-fungible token (NFT) on the Ethereum chain. The string of numbers stored in this token controls a series of attributes of the artwork you purchase, ultimately generating a unique piece of art for you.
If you are a buyer who particularly appreciates a certain artist's style, you can pay and start minting, and a randomly generated artwork in that style will be sent to your account in the form of a token. The final output could be a static image, a 3D model, or an interactive artwork. Each output is different, and the types of content created on the platform have infinite possibilities, but the number of artworks that can be minted for each project is fixed. This means that once the minting limit is reached, no new works will be generated for that project.
For creators: they need to adjust and deploy their generative art scripts on Art Blocks in advance, ensuring that the output results are related to the input hash values. This script will be stored on the Ethereum chain through Art Blocks.
For collectors: when collectors mint a series of works (you can think of it as clicking the purchase button), they essentially obtain a random hash value, and then the script executes, creating a generative artwork corresponding to that hash value on the spot.
This model allows collectors to participate in the creation of generative art.
The content of this artwork is determined by the original artist's style, the generative algorithm, and your minting timing. Tools, creators, and buyers jointly complete such a work, and this new NFT creation model gives the artwork more commemorative value, leaving a mark of the latest technology of the time.
Unlike purchasing mainstream NFT avatar projects, buying NFTs on Art Blocks feels more like directly supporting an artist—these artists are often real names with a wealth of historical works, and Art Blocks conducts in-depth interviews related to their works. For NFTs sold for the first time on Art Blocks, artists can receive 90% of the income, with the remaining 10% going to Art Blocks.
Thus, one can see that Art Blocks has opened a "broad avenue" for AIGC. Of course, this path cannot be simply copied, but modifications in detail can certainly create a commercial closed loop for AIGC + Web3! Moreover, there are already projects doing similar things.
It is precisely because there are so many pioneers paving the way that we have reason to believe that AIGC will go further and further, and the current flaws will gradually be repaired and improved.
 Risk warning
Risk warning Risk warning
Risk warning



Popular articles








