Dialogue EthStorage, building Ethereum's storage network with Layer2 thinking

 How to reduce Ethereum's storage costs using Ethereum's Rollup technology and Layer 2 technology?
How to reduce Ethereum's storage costs using Ethereum's Rollup technology and Layer 2 technology?Guest: Qi Zhou, EthStorage
Host: Jenny, BinaryDAO
Organizer: Ashley, Sarah, Binary DAO
Thank you very much for the invitation from BinaryDAO. Today, I am honored to discuss with you the infrastructure we are building around Ethereum—the EthStorage project.
I have been active in the blockchain field of the Ethereum ecosystem for many years, frequently participating in various online and offline events in the Ethereum community. I have also written some EIPs related to Ethereum development improvements. Therefore, I have been thinking about what the future Web3 infrastructure will look like, what improvements we should make to enhance Ethereum, and how we can make this industry better.
Last year, I spent a considerable amount of time engaging in in-depth discussions with members of the Ethereum Foundation on topics such as Data Availability, and I conducted a lot of research in this area. I was fortunate to receive a grant from them last year, mainly working on data recovery and error correction related to Danksharding, which has now been largely completed.
Moreover, just two weeks ago, our EthStorage project also received a grant from the ETH Foundation.
So, what is EthStorage?
In simple terms, it has two main goals:
The first is to leverage Ethereum's security properties and the open ecosystem that Ethereum has already established. With the upcoming Layer 2 scaling, we see many different scaling strategies, including Optimistic Rollup and ZK Rollup, all of which aim to address Ethereum's performance issues related to computation, transactions, and TPS, while benefiting from Ethereum's security.
Another important goal is to reduce Ethereum's storage costs using Rollup technology and Layer 2 technology. If you are familiar with Ethereum's storage model, you will know that its storage costs are very high. By using EthStorage, we hope to reduce Ethereum's storage costs to one-thousandth of the current level and increase the existing storage capacity to over PB levels.

How do we achieve this goal?
Here, more technical details may be needed, but the Rollup we are working on is fundamentally different from other Ethereum Rollups. Other Rollups focus on solving Ethereum's computation and transaction issues, scaling TPS performance, which belongs to the scaling of the ETH computation layer, while EthStorage is focused on scaling the ETH storage layer.
Our core requirement is how to prove on Ethereum Layer 1 contracts that our Layer 2 has such a large number of replica data, with the number of replicas reaching TB or even hundreds of TB or PB levels. This magnitude is very important. Currently, the storage levels of existing Rollups are still relatively low, including those like Arbitrum and Arbitrum Nova, which have relatively high storage overhead; their storage levels are still at the TB level and have not yet reached the PB level.
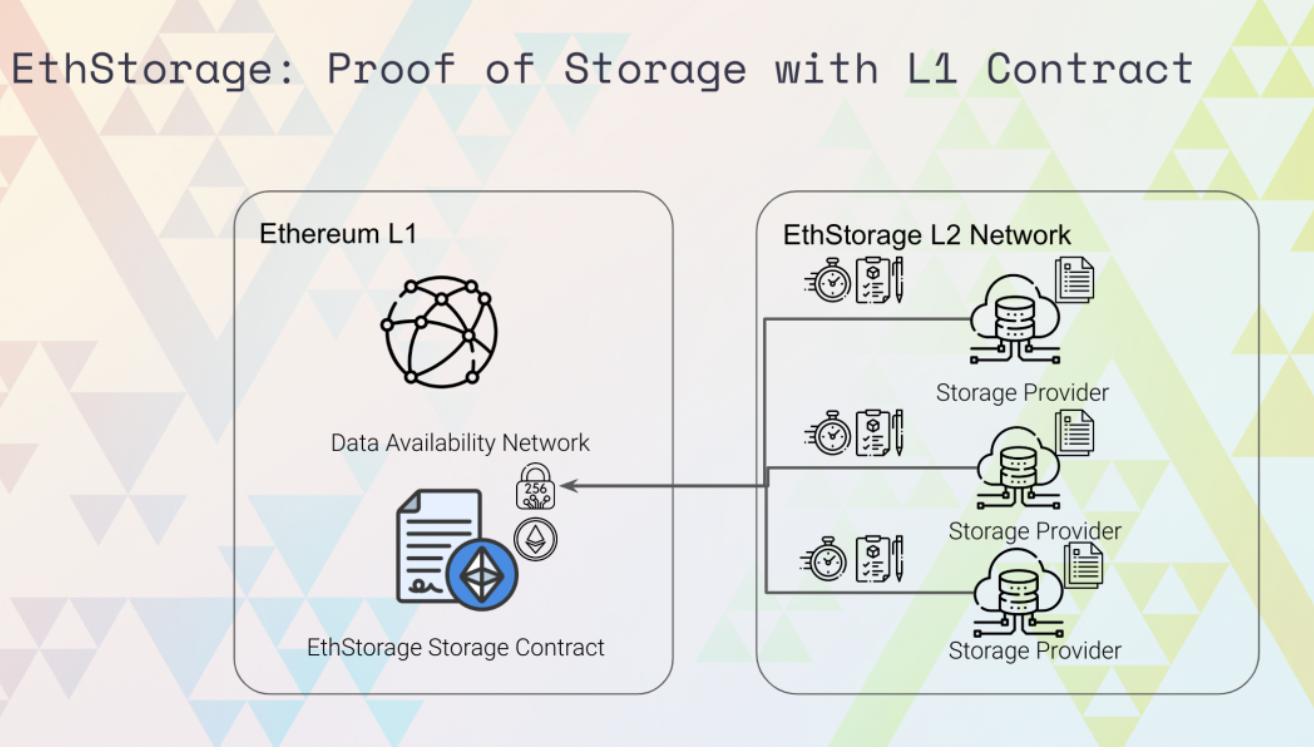
If we can prove on Ethereum Layer 1 contracts that the number of replica data stored on our Layer 2 can reach a very high magnitude, we can create more interesting applications based on this scaling solution.
This is the design goal we want to achieve; based on such a scaling solution, we can create some interesting applications on Ethereum.
On the other hand, for Rollups focused on the computation layer, if they need a long-term storage mechanism, EthStorage can serve not only as a decentralized long-term storage solution but also be highly integrated with Ethereum and its entire ecosystem. Everyone can verify all storage data through smart contracts, which is a very direct application scenario.
Additionally, we have also noticed that in the design of static websites, some decentralized storage applications, such as Filecoin or Arweave, already exist. For instance, Uniswap has backed up its front end, but due to some constraints in the storage system design of IPFS, Filecoin, and Arweave, they can only handle static website data. Once we need a very rich, dynamically interactive front end created by multiple users, we find that Filecoin or Arweave also struggles to provide complete support.
With storage scaling and the upcoming promotion of computation scaling, if we combine these two resources, we can run a large number of rich dynamic applications from Web2 in the form of Web3, which has tremendous application prospects.
If it involves NFTs, the application becomes even smoother. In addition to images, videos and music can also use EthStorage as their native storage on the ETH chain.
For users, there is no need to worry about data storage suddenly disappearing or being located on a single server that might go down. In this way, EthStorage can better support all existing applications on Ethereum. To support these applications, we have also developed a Web3 access protocol.

The Web3 access protocol is defined in our ERC-4804 proposal. What kind of version is this protocol? You can think of it as a decentralized version of HTTP or a more flexible version of IPFS. First of all, this scheme is Web3, and its style is very similar to HTTP, but the way resources are located is through a smart contract rather than a centralized server.
Why do we need such an access protocol?
One important reason is that when we have a large amount of data stored on Ethereum, which can be directly referenced by smart contracts, we need a decentralized way to access it without relying on centralized or semi-centralized services like MetaMask or Infura. Access can be done directly through a link. For example, if I want to access Vitalik's website, it is hosted on a smart contract, or if I want to access a decentralized social network, it is also hosted on a smart contract, while all the content data is stored in EthStorage.
Finally, let me give a more intuitive example. We conducted some early community experiments with EthStorage, such as uploading Vitalik's blog to a smart contract, which cost about 0.13 Ethereum, roughly two to three hundred dollars. The price is still quite expensive, but compared to the Ethereum mainnet, it is already very cheap. We implemented this on Arbitrum Nova, with a total of 40 MB of data, and these websites can be accessed through our Gateway.
When you execute the access, the Gateway accesses the Vitalikblog.eth contract, ultimately finding the corresponding website on the ENS. Therefore, this website is permanently hosted on the Arbitrum Nova network, including all the text, all sub-articles, and all images, which are parsed and returned by the smart contract. Moreover, in the future, when the EthStorage mainnet goes live, the storage costs can be further reduced by an order of magnitude of 10 or even 100 times.

At ETHDenver, we also have some projects, including decentralized GitHub and Dropbox, as well as various special and crazy ideas that are starting to be built on our platform. These projects at ETHDenver have the opportunity to showcase how to use EthStorage to build richer intelligent applications.
This is an overview of what we are doing with EthStorage from the application layer perspective. Thank you all.
 Risk warning
Risk warning Risk warning
Risk warning