

















Foresight Ventures: A Rational Perspective on Decentralized Computing Networks

 The question of who needs a decentralized computing power network has not been validated. The application of idle computing power in the training of large models, which have a huge demand for computing resources, is obviously the most sensible and has the greatest potential for imagination.
The question of who needs a decentralized computing power network has not been validated. The application of idle computing power in the training of large models, which have a huge demand for computing resources, is obviously the most sensible and has the greatest potential for imagination.Author: Ian Xu, Foresight Research
TL;DR
- Currently, the main directions for the combination of AI and Crypto are two major areas: distributed computing power and ZKML; for ZKML, you can refer to one of my previous articles. This article will analyze and reflect on decentralized distributed computing power networks.
- Under the trend of large AI models, computing power resources will be the battleground of the next decade and the most important asset for human society in the future, and it will not only remain in commercial competition but also become a strategic resource in great power games. Future investments in high-performance computing infrastructure and computing power reserves will rise exponentially.
- The demand for decentralized distributed computing power networks in training large AI models is the greatest, but it also faces the biggest challenges and technical bottlenecks, including complex data synchronization and network optimization issues. Additionally, data privacy and security are also significant constraints. Although some existing technologies can provide preliminary solutions, they are still not applicable in large-scale distributed training tasks due to the enormous computational and communication overhead.
- Decentralized distributed computing power networks have more opportunities to land in model inference, and the predicted future incremental space is also large enough. However, they also face challenges such as communication latency, data privacy, and model security. Compared to model training, the computational complexity and data interactivity during inference are lower, making it more suitable for distributed environments.
- Through the cases of two startups, Together and Gensyn.ai, this article illustrates the overall research direction and specific ideas of decentralized distributed computing power networks from the perspectives of technical optimization and incentive layer design.
I. Distributed Computing Power - Large Model Training
When discussing the application of distributed computing power in training, we generally focus on the training of large language models. The main reason is that small models do not require much computing power; it is not cost-effective to tackle data privacy and a bunch of engineering issues through distribution, and it is better to solve them centrally. Large language models, on the other hand, have enormous computing power demands, and we are currently at the initial stage of an explosion. From 2012 to 2018, the computational demand for AI doubled approximately every four months, and now it is a concentrated point of demand for computing power, with a huge incremental demand expected to continue for the next 5-8 years.
While there are enormous opportunities, we also need to clearly see the problems. Everyone knows the scenarios are vast, but where are the specific challenges? Who can target these issues rather than blindly entering the field is the core to judging excellent projects in this track.

(NVIDIA NeMo Megatron Framework)
1. Overall Training Process
Taking the training of a large model with 175 billion parameters as an example. Due to the enormous scale of the model, it needs to be trained in parallel across many GPU devices. Assume there is a centralized data center with 100 GPUs, each with 32GB of memory.
- Data Preparation: First, a massive dataset is needed, which includes various data such as internet information, news, books, etc. Before training, this data needs to be preprocessed, including text cleaning, tokenization, vocabulary building, etc.
- Data Segmentation: The processed data will be divided into multiple batches for parallel processing on multiple GPUs. Assume the chosen batch size is 512, meaning each batch contains 512 text sequences. Then, the entire dataset is split into multiple batches, forming a batch queue.
- Data Transmission Between Devices: At the start of each training step, the CPU retrieves a batch from the batch queue and sends the data of this batch to the GPU via the PCIe bus. Assuming the average length of each text sequence is 1024 tokens, the data size of each batch is approximately 512 * 1024 * 4B = 2MB (assuming each token is represented by a 4-byte single-precision floating point). This data transmission process usually takes only a few milliseconds.
- Parallel Training: After each GPU device receives the data, it begins to perform forward pass and backward pass calculations to compute the gradients for each parameter. Due to the enormous scale of the model, a single GPU's memory cannot hold all the parameters, so we use model parallelism to distribute the model parameters across multiple GPUs.
- Gradient Aggregation and Parameter Update: After the backward pass calculations are completed, each GPU obtains a portion of the parameter gradients. These gradients then need to be aggregated across all GPU devices to compute the global gradient. This requires data transmission over the network; assuming a 25Gbps network, transmitting 700GB of data (assuming each parameter uses single-precision floating point, then 175 billion parameters are approximately 700GB) would take about 224 seconds. Each GPU then updates its stored parameters based on the global gradient.
- Synchronization: After parameter updates, all GPU devices need to synchronize to ensure they are using consistent model parameters for the next training step. This also requires data transmission over the network.
- Repeat Training Steps: Repeat the above steps until all batches are trained or the predetermined number of training epochs is reached.
This process involves a large amount of data transmission and synchronization, which may become a bottleneck for training efficiency. Therefore, optimizing network bandwidth and latency, as well as using efficient parallel and synchronization strategies, is crucial for large-scale model training.
2. Bottleneck of Communication Overhead:
It is important to note that the communication bottleneck is also the reason why the current distributed computing power network cannot perform large language model training.
Each node needs to frequently exchange information to work collaboratively, which generates communication overhead. For large language models, this issue is particularly severe due to the enormous number of model parameters. Communication overhead can be divided into several aspects:
- Data Transmission: During training, nodes need to frequently exchange model parameters and gradient information. This requires transmitting a large amount of data over the network, consuming significant network bandwidth. If network conditions are poor or the distance between computing nodes is large, data transmission latency will be high, further increasing communication overhead.
- Synchronization Issues: During training, nodes need to work collaboratively to ensure the correctness of training. This requires frequent synchronization operations between nodes, such as updating model parameters and calculating global gradients. These synchronization operations require transmitting a large amount of data over the network and waiting for all nodes to complete their operations, leading to significant communication overhead and waiting time.
- Gradient Accumulation and Update: During training, each node needs to compute its gradients and send them to other nodes for accumulation and updates. This requires transmitting a large amount of gradient data over the network and waiting for all nodes to complete gradient computation and transmission, which is also a significant source of communication overhead.
- Data Consistency: It is necessary to ensure that the model parameters of each node remain consistent. This requires frequent data verification and synchronization operations between nodes, leading to significant communication overhead.
Although there are some methods to reduce communication overhead, such as compression of parameters and gradients, and efficient parallel strategies, these methods may introduce additional computational burdens or negatively impact the training effectiveness of the model. Moreover, these methods cannot completely solve the communication overhead problem, especially in cases of poor network conditions or large distances between computing nodes.
For example:
Decentralized Distributed Computing Power Network
The GPT-3 model has 175 billion parameters. If we use single-precision floating point (4 bytes per parameter) to represent these parameters, storing them would require approximately 700GB of memory. In distributed training, these parameters need to be frequently transmitted and updated across various computing nodes.
Assuming there are 100 computing nodes, each node needs to update all parameters at every step, which means approximately 70TB (700GB * 100) of data needs to be transmitted at each step. If we assume that one step takes 1 second (a very optimistic assumption), then 70TB of data needs to be transmitted every second. This demand for bandwidth far exceeds that of most networks, posing a feasibility issue.
In reality, due to communication latency and network congestion, the time for data transmission may far exceed 1 second. This means that computing nodes may spend a significant amount of time waiting for data transmission rather than performing actual computations. This greatly reduces training efficiency, and this reduction in efficiency is not something that can be resolved by simply waiting; it represents a difference between feasibility and infeasibility, making the entire training process unworkable.
Centralized Data Center
Even in a centralized data center environment, training large models still requires significant communication optimization.
In a centralized data center environment, high-performance computing devices are connected as a cluster via high-speed networks to share computing tasks. However, even in this high-speed network environment, the communication overhead remains a bottleneck when training models with a vast number of parameters, as model parameters and gradients need to be frequently transmitted and updated between computing devices.
As mentioned earlier, assume there are 100 computing nodes, each server has a network bandwidth of 25Gbps. If each server needs to update all parameters at every training step, then each training step requires transmitting approximately 700GB of data, which takes about 224 seconds. With the advantages of a centralized data center, developers can optimize the network topology within the data center and use model parallelism and other techniques to significantly reduce this time.
In contrast, if the same training is conducted in a distributed environment, assuming there are still 100 computing nodes distributed globally, with an average network bandwidth of only 1Gbps for each node, transmitting the same 700GB of data would take approximately 5600 seconds, which is much longer than the time required in a centralized data center. Moreover, due to network latency and congestion, the actual time required may be even longer.
However, compared to the situation in a distributed computing power network, optimizing communication overhead in a centralized data center environment is relatively easier. This is because, in a centralized data center environment, computing devices are typically connected to the same high-speed network, with relatively good bandwidth and latency. In a distributed computing power network, computing nodes may be located globally, and network conditions may be relatively poor, making the communication overhead issue more severe.
OpenAI used a model parallel framework called Megatron during the training of GPT-3 to address the communication overhead issue. Megatron reduces the amount of parameters each device needs to handle by splitting the model parameters and processing them in parallel across multiple GPUs, with each device only responsible for storing and updating a portion of the parameters, thereby reducing communication overhead. At the same time, high-speed interconnect networks were used during training, and the network topology was optimized to reduce the length of communication paths.

(Data used to train LLM models)
3. Why Distributed Computing Power Networks Cannot Optimize These Issues
It is possible to make these optimizations, but compared to centralized data centers, the effectiveness of these optimizations is very limited.
- Network Topology Optimization: In a centralized data center, network hardware and layout can be directly controlled, allowing for the design and optimization of network topology as needed. However, in a distributed environment, computing nodes are located in different geographical locations, and it is impossible to directly control the network connections between them. Although software can be used to optimize data transmission paths, it is not as effective as directly optimizing hardware networks. Additionally, due to geographical differences, network latency and bandwidth can vary significantly, further limiting the effectiveness of network topology optimization.
- Model Parallelism: Model parallelism is a technique that splits model parameters across multiple computing nodes to improve training speed through parallel processing. However, this method typically requires frequent data transmission between nodes, which places high demands on network bandwidth and latency. In centralized data centers, due to high network bandwidth and low latency, model parallelism can be very effective. However, in distributed environments, due to poor network conditions, model parallelism is significantly constrained.
4. Challenges of Data Security and Privacy
Almost all aspects of data processing and transmission may affect data security and privacy:
- Data Distribution: Training data needs to be distributed to each participating computing node. During this process, data may be maliciously used or leaked at distributed nodes.
- Model Training: During training, each node uses its allocated data for computation and then outputs updates to model parameters or gradients. If the computation process of a node is compromised or the results are maliciously interpreted, it may also leak data.
- Parameter and Gradient Aggregation: The outputs from each node need to be aggregated to update the global model, and the communication during the aggregation process may also leak information about the training data.
What solutions are there for data privacy issues?
- Secure Multi-Party Computation: SMC has been successfully applied in certain specific, smaller-scale computational tasks. However, in large-scale distributed training tasks, due to its computational and communication overhead, it has not been widely adopted.
- Differential Privacy: Applied in certain data collection and analysis tasks, such as user statistics in Chrome. However, in large-scale deep learning tasks, DP can impact the accuracy of the model. Additionally, designing appropriate noise generation and addition mechanisms is also a challenge.
- Federated Learning: Applied in some model training tasks on edge devices, such as vocabulary prediction in Android keyboards. However, in larger-scale distributed training tasks, FL faces issues such as high communication overhead and complex coordination.
- Homomorphic Encryption: Successfully applied in some tasks with lower computational complexity. However, in large-scale distributed training tasks, due to its high computational overhead, it has not been widely adopted.
In summary
Each of the above methods has its applicable scenarios and limitations, and no single method can completely solve the data privacy issues in large model training within distributed computing power networks.
Can ZK, which is highly anticipated, solve the data privacy issues during large model training?
In theory, ZKP can be used to ensure data privacy in distributed computing, allowing a node to prove that it has performed calculations as required without revealing the actual input and output data.
However, in practice, applying ZKP in the scenario of large-scale distributed computing power network training faces the following bottlenecks:
- Increased Computational and Communication Overhead: Constructing and verifying zero-knowledge proofs requires a large amount of computational resources. Additionally, the communication overhead of ZKP is also significant, as the proof itself needs to be transmitted. In the case of large model training, these overheads can become particularly pronounced. For example, if each mini-batch computation requires generating a proof, this would significantly increase the overall time and cost of training.
- Complexity of ZK Protocols: Designing and implementing a ZKP protocol suitable for large model training is very complex. This protocol needs to handle large-scale data and complex computations and must be able to deal with potential exceptions and errors.
- Compatibility of Hardware and Software: Using ZKP requires specific hardware and software support, which may not be available on all distributed computing devices.
In summary
To apply ZKP in large-scale distributed computing power network training of large models, several years of research and development are still needed, and more attention and resources from academia in this direction are required.
II. Distributed Computing Power - Model Inference
Another significant scenario for distributed computing power is in model inference. According to our judgment on the development path of large models, the demand for model training will gradually slow down after reaching a peak as large models mature, while the demand for model inference will correspondingly rise exponentially with the maturity of large models and AIGC.
Inference tasks generally have lower computational complexity and weaker data interactivity compared to training tasks, making them more suitable for distributed environments.

(Power LLM inference with NVIDIA Triton)
1. Challenges
Communication Latency:
In a distributed environment, communication between nodes is essential. In a decentralized distributed computing power network, nodes may be spread across the globe, so network latency can be an issue, especially for inference tasks that require real-time responses.
Model Deployment and Updates:
Models need to be deployed to each node. If a model is updated, each node needs to update its model, consuming significant network bandwidth and time.
Data Privacy:
Although inference tasks typically only require input data and the model, without needing to return large amounts of intermediate data and parameters, the input data may still contain sensitive information, such as users' personal information.
Model Security:
In a decentralized network, models need to be deployed on untrusted nodes, which can lead to model leakage and issues of model ownership and misuse. This may also raise security and privacy concerns; if a model is used to process sensitive data, nodes can infer sensitive information by analyzing the model's behavior.
Quality Control:
Each node in a decentralized distributed computing power network may have different computing capabilities and resources, making it difficult to guarantee the performance and quality of inference tasks.
2. Feasibility
Computational Complexity:
During the training phase, models need to iterate repeatedly, requiring forward and backward pass calculations for each layer, including activation function calculations, loss function calculations, gradient calculations, and weight updates. Therefore, the computational complexity of model training is high.
In the inference phase, only a single forward pass calculation is needed to predict results. For example, in GPT-3, the input text needs to be converted into vectors, then passed through the model's layers (usually Transformer layers) for forward propagation, and finally, the output probability distribution is obtained, from which the next word is generated. In GANs, the model generates an image based on the input noise vector. These operations only involve the model's forward propagation, without needing to compute gradients or update parameters, resulting in lower computational complexity.
Data Interactivity:
In the inference phase, models typically handle single inputs rather than large batches of data as in training. Each inference result only depends on the current input and not on other inputs or outputs, so there is no need for extensive data interaction, which reduces communication pressure.
For example, in a generative image model using GANs, we only need to input a noise vector into the model, and the model will generate a corresponding image. In this process, each input generates only one output, with no dependency between outputs, so no data interaction is needed.
In the case of GPT-3, generating the next word only requires the current text input and the model's state, without needing to interact with other inputs or outputs, thus the requirements for data interactivity are also low.
In summary
Whether for large language models or generative image models, the computational complexity and data interactivity of inference tasks are relatively low, making them more suitable for decentralized distributed computing power networks. This is also a direction where we see most projects currently focusing their efforts.

III. Projects
The technical threshold and breadth of decentralized distributed computing power networks are very high, and they also require hardware resources to support them. Therefore, we do not currently see many attempts. Taking Together and Gensyn.ai as examples:
1. Together
(RedPajama from Together)
Together is a company focused on open-source large models and dedicated to decentralized AI computing power solutions, hoping that anyone can access and use AI anywhere. Together has just completed a $20 million seed round of financing led by Lux Capital.
Together was co-founded by Chris, Percy, and Ce, with the original intention being that training large models requires a large number of high-end GPU clusters and expensive expenditures, and these resources and model training capabilities are concentrated in a few large companies.
From my perspective, a reasonable entrepreneurial plan for distributed computing power is:
Step 1. Open Source Models
To achieve model inference in a decentralized distributed computing power network, a prerequisite is that nodes must be able to access models at low cost, meaning that models used in the decentralized computing power network need to be open source (if models need to be used under corresponding licenses, it will increase the complexity and cost of implementation). For example, ChatGPT, as a non-open-source model, is not suitable for execution on a decentralized computing power network.
Therefore, it can be inferred that a company's invisible barrier to providing a decentralized computing power network is the need for strong capabilities in large model development and maintenance. Developing and open-sourcing a powerful base model can to some extent free the company from reliance on third-party model open-sourcing, solving the most fundamental issues of decentralized computing power networks. It also better demonstrates that the computing power network can effectively train and infer large models.
Together is doing just that. The recently released RedPajama, based on LLaMA, was jointly initiated by Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, and Hazy Research, aiming to develop a series of fully open-source large language models.
Step 2. Implementing Distributed Computing Power in Model Inference
As mentioned in the previous two sections, compared to model training, the computational complexity and data interactivity of model inference are lower, making it more suitable for decentralized distributed environments.
Based on open-source models, Together's R&D team has made a series of updates to the RedPajama-INCITE-3B model, such as using LoRA for low-cost fine-tuning, making the model run more smoothly on CPUs (especially on MacBook Pro with M2 Pro processors). Moreover, although this model is relatively small, its capabilities surpass those of other models of the same scale and have been applied in legal, social, and other scenarios.
Step 3. Implementing Distributed Computing Power in Model Training

(Diagram of Overcoming Communication Bottlenecks for Decentralized Training)
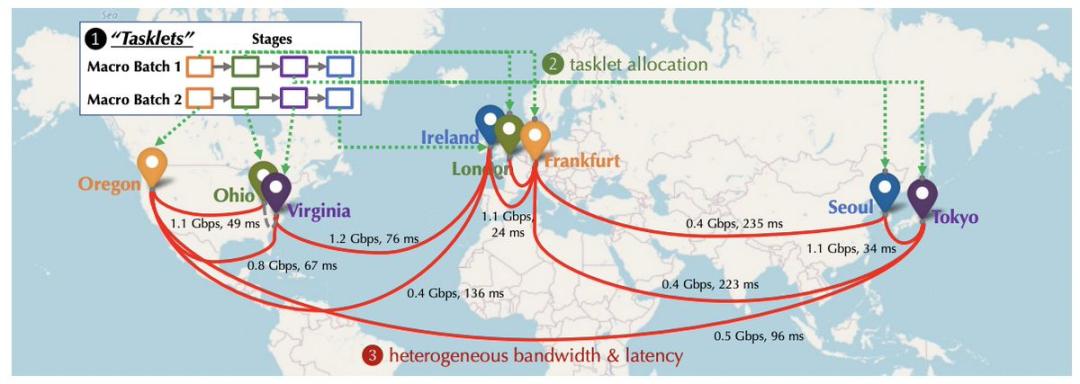
In the medium to long term, although facing significant challenges and technical bottlenecks, meeting the computing power demand for AI large model training is undoubtedly the most attractive. Together began planning how to overcome communication bottlenecks in decentralized training from the outset. They also published a related paper at NeurIPS 2022: Overcoming Communication Bottlenecks for Decentralized Training. We can summarize the following directions:
Scheduling Optimization
When training in a decentralized environment, it is important to assign tasks that require heavy communication to devices with faster connections, as the connections between nodes have different latencies and bandwidths. Together builds models to describe the costs of specific scheduling strategies to better optimize scheduling strategies, minimizing communication costs and maximizing training throughput. The Together team also found that even if the network is 100 times slower, the end-to-end training throughput only slows down by 1.7 to 2.3 times. Therefore, it is promising to catch up with the gap between distributed networks and centralized clusters through scheduling optimization.
Communication Compression Optimization
Together proposed communication compression for forward activations and backward gradients, introducing the AQ-SGD algorithm, which provides strict guarantees for the convergence of stochastic gradient descent. AQ-SGD can fine-tune large base models on slow networks (like 500 Mbps) and only slows down by 31% compared to end-to-end training performance in centralized computing power networks (like 10 Gbps) without compression. Additionally, AQ-SGD can be combined with state-of-the-art gradient compression techniques (like QuantizedAdam) to achieve a 10% end-to-end speed improvement.
Project Summary
The Together team is very comprehensive, with members having strong academic backgrounds and industry experts supporting various areas from large model development to cloud computing and hardware optimization. Moreover, Together has indeed demonstrated a long-term patient approach in its path planning, from developing open-source large models to testing idle computing power (like Macs) for model inference in decentralized computing power networks, and then laying out distributed computing power in large model training. --- There is a sense of accumulating strength for a breakthrough :)
However, we have not yet seen much research output from Together in the incentive layer, which I believe is equally important as technological research and is a key factor in ensuring the development of decentralized computing power networks.
2. Gensyn.ai
(Gensyn.ai)
From Together's technical path, we can roughly understand the landing process of decentralized computing power networks in model training and inference, as well as the corresponding R&D focus.
Another critical aspect that cannot be overlooked is the design of the incentive layer/consensus algorithm for the computing power network. For example, an excellent network needs to have:
- Ensure that the rewards are sufficiently attractive;
- Ensure that each miner receives their due rewards, including anti-cheating measures and pay-for-performance;
- Ensure that tasks are reasonably scheduled and allocated among different nodes, avoiding a large number of idle nodes or overcrowding at certain nodes;
- The incentive algorithm should be simple and efficient, avoiding excessive system burden and latency;
……
Let's see how Gensyn.ai does it:
- Becoming a Node
First, solvers in the computing power network compete for the right to process tasks submitted by users through bidding, and based on the scale of the task and the risk of being caught cheating, solvers need to stake a certain amount.
- Verification
While updating parameters, solvers generate multiple checkpoints (ensuring transparency and traceability of work) and periodically generate cryptographic encrypted inference proofs about the tasks (proof of work progress);
When a solver completes work and produces some computational results, the protocol selects a verifier, who also stakes a certain amount (to ensure the verifier honestly performs the verification) and decides which part of the computational results needs to be verified based on the provided proofs.
- If there is a Discrepancy Between Solver and Verifier
Using a Merkle tree data structure, the exact location of the discrepancy in the computational results can be pinpointed. The entire verification operation will be recorded on-chain, and the cheater will lose their staked amount.
Project Summary
The design of the incentive and verification algorithms allows Gensyn.ai to avoid replaying all results of the entire computational task during the verification process. Instead, it only needs to replicate and verify a portion of the results based on the provided proof, significantly improving verification efficiency. Additionally, nodes only need to store partial computational results, reducing storage space and computational resource consumption. Furthermore, potential cheating nodes cannot predict which parts will be selected for verification, thus reducing the risk of cheating.
This method of verifying discrepancies and identifying cheaters can quickly locate errors in the computation process without needing to compare the entire computational results (starting from the root of the Merkle tree and traversing downwards), which is very effective for handling large-scale computational tasks.
In summary, the goal of Gensyn.ai's incentive/verification layer design is: simplicity and efficiency. However, this is currently limited to the theoretical level, and specific implementations may still face the following challenges:
- In terms of the economic model, how to set appropriate parameters to effectively prevent fraud without imposing excessive barriers on participants.
- In terms of technical implementation, how to establish an effective periodic cryptographic inference proof is also a complex issue requiring advanced cryptographic knowledge.
- In terms of task allocation, how the computing power network selects and allocates tasks to different solvers also requires support from reasonable scheduling algorithms. Simply allocating tasks based on a bidding mechanism is clearly debatable in terms of efficiency and feasibility. For example, nodes with strong computing power can handle larger tasks but may not participate in bidding (which involves incentivizing node availability), while nodes with lower computing power may bid the highest but may not be suitable for handling complex large-scale computational tasks.
IV. Thoughts on the Future
The question of who needs a decentralized computing power network has not been validated. Applying idle computing power to the training of large models, which have a huge demand for computing resources, clearly makes the most sense and has the greatest imaginative potential. However, the bottlenecks of communication, privacy, and others force us to rethink:
Is decentralized training of large models really hopeful?
If we step out of this widely accepted "most reasonable landing scenario," could applying decentralized computing power to the training of small AI models also represent a significant scenario? From a technical perspective, the current limiting factors have been resolved due to the scale and architecture of the models. Meanwhile, from a market perspective, we have always believed that the training of large models will be enormous from now into the future, but does the market for small AI models lack attractiveness?
I think not necessarily. Compared to large models, small AI models are easier to deploy and manage, and they are more efficient in terms of processing speed and memory usage. In many application scenarios, users or companies do not need the more general reasoning capabilities of large language models but rather focus on a very refined predictive target. Therefore, in most scenarios, small AI models remain a more feasible choice and should not be prematurely overlooked in the tide of FOMO for large models.
 Risk warning
Risk warning Risk warning
Risk warning




Popular articles








