Dialogue with Gensyn Founder: Maximizing the Use of Idle Computing Resources through Decentralized Networks to Support Machine Learning

 Blockchain provides a way to break the need for a single decision-maker or arbitrator, as it enables consensus among large groups.
Blockchain provides a way to break the need for a single decision-maker or arbitrator, as it enables consensus among large groups.Video Link: 《Ben Fielding & Harry Grieve: Gensyn -- The Deep Learning Compute Protocol》
Host: Dr. Friederike Ernst, Epicenter Podcast
Speakers: Ben Fielding & Harry Grieve, Co-founders of Gensyn
Organized & Compiled by: Sunny, Deep Tide TechFlow
The blockchain AI computing protocol Gensyn announced on June 12 that it has completed a $43 million Series A funding round led by a16z.
Gensyn's mission is to provide users with access to computing scale equivalent to owning a private computing cluster, and crucially, to achieve fair access without being controlled or shut down by any central entity. At the same time, Gensyn is a decentralized computing protocol focused on training machine learning models.
Looking back at the podcast from the end of last year featuring Gensyn founders Harry and Ben with Epicenter, it delves deeply into the investigation of computing resources, including AWS, local infrastructure, and cloud infrastructure, to understand how to optimize and utilize these resources to support the development of AI applications.
They also discuss in detail Gensyn's design philosophy, goals, and market positioning, as well as the various constraints, assumptions, and execution strategies faced during the design process.
The podcast introduces four main roles in the Gensyn off-chain network, explores the characteristics of the Gensyn on-chain network, and highlights the importance of the Gensyn token and governance.
Additionally, Ben and Harry share some interesting AI popular science insights, allowing everyone to gain a deeper understanding of the basic principles and applications of artificial intelligence.

Blockchain as a Trust Layer for Decentralized AI Infrastructure
The host asked Ben and Harry why they combined their extensive experience in AI and deep learning with blockchain.
Ben stated that their decision was not made overnight but was the result of a relatively long period of consideration. Gensyn aims to build a large-scale AI infrastructure, and while researching how to achieve maximum scalability, they realized the need for a trustless layer.
They needed a way to integrate computing power without relying on centralized new vendor access, or else they would face limitations of administrative expansion. To address this issue, they began exploring verifiable computing research, but they found that it always required a trusted third party or arbiter to verify the computation.
This limitation led them to blockchain. Blockchain provides a way to break the need for a single decision-maker or arbitrator, as it can achieve consensus among large groups.
Harry also shared his philosophy, emphasizing that he and Ben strongly support free speech and are concerned about censorship.
Before turning to blockchain, they were researching federated learning, a field of deep learning where multiple models are trained on distributed data sources and then combined to create a meta-model that can learn from all data sources. They collaborated with banks on this approach. However, they quickly realized that the bigger issue was acquiring the computing resources or processors needed to train these models.
To maximize the integration of computing resources, they needed a decentralized coordination method, which is where blockchain comes into play.
Market Survey of Computing Resources: AWS, Local Infrastructure, and Cloud Infrastructure
Harry explained the different computing resource options for running AI models, depending on the scale of the model.
Students might use AWS or local machines, while startups might opt for on-demand AWS or cheaper reserved options.
However, for large-scale GPU demands, AWS may face limitations in cost and scalability, often leading to the choice of building internal infrastructure.
Research shows that many organizations are struggling to scale, with some even choosing to purchase and manage GPUs themselves. Overall, buying GPUs is more cost-effective in the long run compared to running on AWS.
The choices for machine learning computing resources include cloud computing, running AI models locally, or building one's own computing cluster. Gensyn aims to provide access to computing scale equivalent to owning a private cluster, and crucially, to achieve fair access that cannot be controlled or shut down by any central entity.

Table 1: Current Market Options for Computing Resources
Discussion on Gensyn's Design Philosophy, Goals, and Market Positioning
The host asked how Gensyn differs from previous blockchain computing projects, such as Golem Network.
Harry explained that Gensyn's design philosophy is primarily considered along two axes:
- The granularity of the protocol: Unlike general computing protocols like Golem, Gensyn is a fine-grained protocol focused on training machine learning models.
- Scalability of verification: Early projects often relied on reputation or less tolerant Byzantine fault replication methods, which did not provide sufficient confidence in machine learning outcomes. Gensyn aims to leverage the learning experiences of computing protocols in the cryptographic world and apply them specifically to machine learning to optimize speed and cost while ensuring satisfactory levels of verification.
Harry added that when considering the properties the network must possess, it needs to cater to machine learning engineers and researchers. It needs to have a verification component, but crucially, it must resist censorship and remain hardware-neutral while allowing anyone to participate.
Constraints, Assumptions, and Execution in the Design Process
In the design process of Gensyn's platform, Ben emphasized the importance of system constraints and assumptions. Their goal is to create a network that can transform the entire world into an AI supercomputer, for which they need to find a balance between product assumptions, research assumptions, and technical assumptions.
Regarding why they built Gensyn as their own Layer 1 blockchain, their reasoning was to maintain greater flexibility and decision-making freedom in key technical areas such as consensus mechanisms. They wanted to be able to future-proof their protocol and did not want to impose unnecessary constraints at the early stages of the project. Additionally, they believe that in the future, various chains will be able to interact through a widely accepted information protocol, so their decision aligns with this vision.
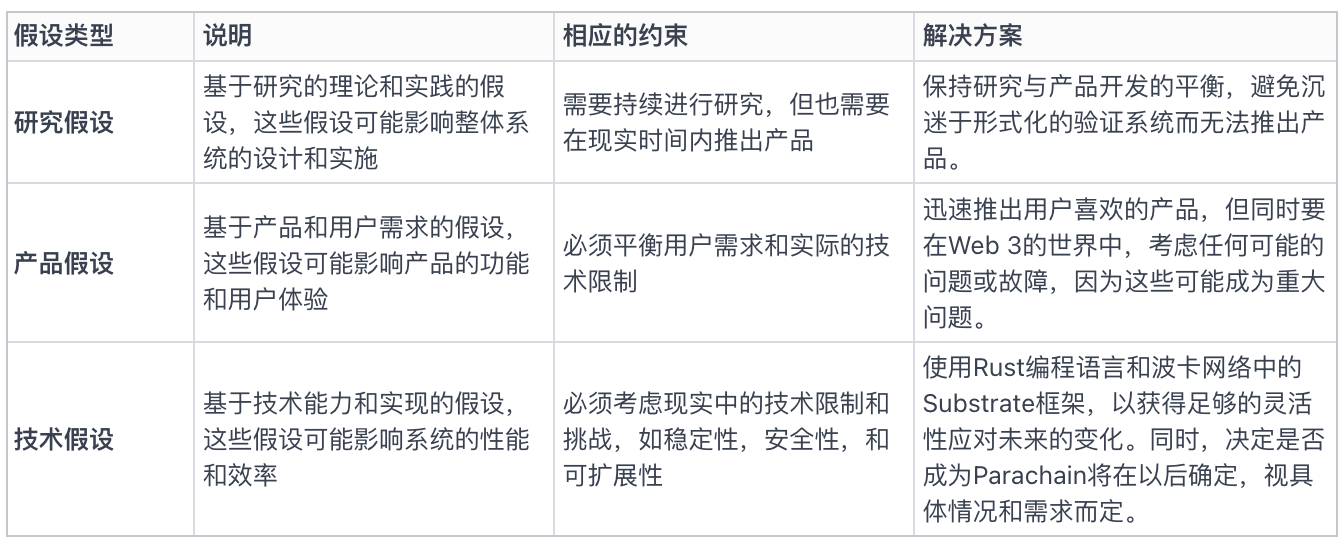
Chart 2: Product Assumptions, Research Assumptions, and Technical Assumptions, Constraints, and Execution
Four Main Roles in the Gensyn Off-Chain Network
In this Gensyn economic discussion, four main roles were introduced: Submitter, Worker, Verifier, and Whistleblower. Submitters can submit various tasks to the Gensyn network, including generating specific images or developing AI models capable of driving cars.
Submitter Submits Tasks
Harry explained how to use Gensyn to train models. Users first define the expected outcome, such as generating an image based on a text prompt, and then build a model that takes the text prompt as input and generates the corresponding image. Training data is crucial for the model's learning and improvement. Once the model architecture and training data are ready, users submit them to the Gensyn network along with hyperparameters such as learning rate schedules and training duration. The result of this training process is a trained model that users can host and utilize.
When asked how to choose an untrained model, Harry proposed two methods.
- The first is based on the current popular foundational model concept, where large companies like OpenAI or Midjourney build foundational models that users can then train on specific data.
- The second option is to build a model from scratch, which differs from the foundational model approach.
In Gensyn, developers can submit various architectures using methods similar to evolutionary optimization for training and testing, continuously optimizing to build the desired model.
Ben provided an in-depth perspective on foundational models from their viewpoint, believing that this is the future of the field.
As a protocol, Gensyn hopes to be utilized by DApps implementing evolutionary optimization techniques or similar methods. These DApps can submit individual architectures to the Gensyn protocol for training and testing, refining iteratively to build the ideal model.
Gensyn aims to provide pure machine learning computing infrastructure, encouraging the development of an ecosystem around it.
While pre-trained models may introduce biases due to organizations using proprietary datasets or concealing information about the training process, Gensyn's solution is to open the training process rather than eliminate the black box or rely on full determinism. By collectively designing and training foundational models, we can create global models without being biased by any specific company's dataset.
Worker
For task allocation, one task corresponds to one server. However, a model may be split into multiple tasks.
Large language models are designed to fully utilize the maximum hardware capacity available at the time. This concept can be extended to the network, considering the heterogeneity of devices.
For specific tasks, such as Verifiers or Workers, they can choose to take on tasks from the Mempool. A Worker is randomly selected from those who express willingness to take on the task. If a model and data cannot adapt to a specific device, but the device owner claims it can, they may incur penalties due to system congestion.
Whether a task can run on a machine is determined by a verifiable random function that selects a Worker from the available subset of Workers.
Regarding the verification of Workers' capabilities, if a Worker does not possess the claimed computing power, they will be unable to complete the computational task, which will be detected during proof submission.
However, the size of the task is an issue. If the task is set too large, it may lead to system problems, such as denial-of-service attacks (DoS), where Workers claim to complete tasks but never do, wasting time and resources.
Thus, determining the task size is crucial and needs to consider factors such as parallelization and task structure optimization. Researchers are actively exploring and investigating the best approaches based on various constraints.
Once the testnet is launched, real-world scenarios will also be considered to observe how the system operates in reality.
Defining the perfect task size is challenging, and Gensyn is prepared to adjust and improve based on real-world feedback and experience.
Verification Mechanism and Checkpoints for Large-Scale On-Chain Computation
Harry and Ben indicated that verifying the correctness of computations is a significant challenge, as it is not deterministic like hash functions, making it impossible to simply verify computations through hashing. The ideal solution to this problem is to utilize zero-knowledge proofs for the entire computation process. Currently, Gensyn is still working to achieve this capability.
At present, Gensyn has introduced a hybrid approach using checkpoints to verify machine learning computations through probabilistic mechanisms and checkpoints. By combining random auditing schemes and gradient space paths, a relatively robust checkpoint can be established. Additionally, zero-knowledge proofs have been introduced to enhance the verification process and have been applied to the global loss of the model.
Verifier and Whistleblower
The host and Harry discussed two additional roles involved in the verification process: Verifier and Whistleblower. They elaborated on the specific responsibilities and functions of these two roles.
The Verifier's task is to ensure the correctness of the checkpoints, while the Whistleblower's task is to ensure the accuracy of the Verifier's duties. The Whistleblower addresses the dilemma of the Verifier, ensuring that the Verifier's work is correct and trustworthy. The Verifier intentionally introduces errors into the work, and the Whistleblower's role is to identify and reveal these errors, thereby ensuring the integrity of the verification process.
The Verifier intentionally introduces errors to test the Whistleblower's vigilance and ensure the system's effectiveness. If there are errors in the work, the Verifier will detect them and notify the Whistleblower. The errors are then recorded on the blockchain and verified on-chain. Periodically, and at a rate related to the system's security, the Verifier intentionally introduces errors to maintain the Whistleblower's engagement. If the Whistleblower identifies issues, they will participate in a game called the "pinpoint protocol," through which they can narrow down the computation to a specific point in the Merkle tree of a neural network. This information is then submitted for arbitration on-chain. This is a simplified version of the Verifier and Whistleblower process, which will undergo further development and research after the seed round concludes.
Gensyn On-Chain Network
Ben and Harry discussed in detail how the Gensyn coordination protocol operates on-chain and its implementation details. They first mentioned the process of building network blocks, which involves staking tokens as part of the staking network. They then explained how these components relate to the Gensyn protocol.
Ben explained that the Gensyn protocol is largely based on the vanilla substrate Polkadot network protocol. They adopted a proof-of-stake-based Grandpa Babe consensus mechanism, with Verifiers operating in the usual way. However, all previously introduced machine learning components are executed off-chain, involving various off-chain participants performing their respective tasks.
These participants are incentivized through staking, which can be done through the staking module in Substrate or by staking a specific amount of tokens in a smart contract. When their work is ultimately verified, they will receive rewards.
The challenges mentioned by Ben and Harry lie in ensuring a balance between the staked amount, potential slashing amounts, and reward amounts to prevent incentives for lazy or malicious behavior.
Additionally, they discussed the complexities that come with increasing the number of Whistleblowers, but due to the demand for scalable computation, their presence is crucial for ensuring the honesty of Verifiers. While they are continuously exploring ways to potentially eliminate Whistleblowers through zero-knowledge proof technology, they stated that the current system aligns with what is described in the lite paper, but they are actively working to simplify every aspect.
The host asked if they have any data availability solutions, and Henry explained that they introduced a layer called proof of availability (POA) on top of Substrate. This layer utilizes techniques such as erasure coding to address the limitations they encounter in the broad storage layer market. They expressed interest in developers who have already implemented such solutions.
Ben added that their needs involve not only storing training data but also intermediate proof data, which does not require long-term storage. For example, when they complete a specific number of block releases, they may only need to retain data for about 20 seconds. However, the storage costs they currently pay on Arweave cover hundreds of years, which is unnecessary for these short-term needs. They are looking for a solution that combines the guarantees and functionalities of Arweave while meeting short-term storage needs at a lower cost.
Gensyn Token and Governance
Ben explained the importance of the Gensyn token in the ecosystem, as it plays a key role in staking, penalties, providing rewards, and maintaining consensus. Its primary purpose is to ensure the financial soundness and integrity of the system. Ben also mentioned the careful use of inflation rates to pay Verifiers and leverage game-theoretic mechanisms.
He emphasized the purely technical use of the Gensyn token and stated that they will technically ensure the timing and necessity of introducing the Gensyn token.
Harry noted that they belong to a minority in the deep learning community, especially under the widespread skepticism of AI scholars towards cryptocurrency. Nevertheless, they recognize the value of cryptocurrency in both technical and ideological aspects.
However, at the network launch, they expect that most deep learning users will primarily use fiat currency for transactions, with the conversion to tokens occurring seamlessly in the background.
In terms of supply, Workers and Submitters will actively participate in token trading, and they have already received interest from Ethereum miners who possess substantial GPU resources and are seeking new opportunities.
Here, it is important to ensure the elimination of deep learning and machine learning practitioners' fears regarding cryptocurrency terminology (such as tokens), separating it from the user experience interface. Gensyn states that this is an exciting use case that connects the worlds of Web 2 and Web 3, as it possesses economic rationality and the technology needed to support its existence.

Figure 1: The operational model of Gensyn's on-chain and off-chain network based on the podcast; if there are any errors in the operational mechanism, readers are encouraged to point them out (Image Source: Deep Tide)
Popular Science on Artificial Intelligence
AI, Deep Learning, and Machine Learning
Ben shared his views on the developments in the AI field in recent years. He believes that while the AI and machine learning fields have experienced a series of small bursts over the past seven years, the current advancements seem to be creating real impact and valuable applications that resonate with a broader audience. Deep learning is the fundamental driving force behind these changes. Deep neural networks have demonstrated their ability to surpass benchmarks set by traditional computer vision methods. Additionally, models like GPT-3 have accelerated this progress.
Harry further explained the distinctions between AI, machine learning, and deep learning. He believes these three terms are often used interchangeably, but they have significant differences. He likened AI, machine learning, and deep learning to Russian nesting dolls, with AI being the outermost layer.
- Broadly speaking, AI refers to programming machines to perform tasks.
- Machine learning became popular in the 1990s and early 2000s, using data to determine the probability of decisions rather than relying on expert systems with if-then rules.
- Deep learning builds on machine learning but allows for more complex models.

Chart 3: The Differences Between Artificial Intelligence, Machine Learning, and Deep Learning
Artificial Narrow Intelligence, Artificial General Intelligence, and Artificial Super Intelligence
In this section, the host and guests delved into three key areas of artificial intelligence: Artificial Narrow Intelligence (ANI), Artificial General Intelligence (AGI), and Artificial Super Intelligence (ASI).
- Artificial Narrow Intelligence (ANI): Current AI primarily exists in this stage, where machines are very good at performing specific tasks, such as detecting certain types of cancer from medical scans through pattern recognition.
- Artificial General Intelligence (AGI): AGI refers to machines that can perform tasks that are relatively simple for humans but are quite challenging to reflect in computational systems. For example, enabling machines to navigate smoothly in crowded environments while making discrete assumptions about all surrounding inputs is an example of AGI. AGI refers to models or systems that can perform everyday tasks like humans.
- Artificial Super Intelligence (ASI): After achieving AGI, machines may further develop into ASI. This refers to machines that surpass human capabilities due to the complexity of their models, increased computational power, infinite lifespan, and perfect memory. This concept is often explored in science fiction and horror films.
Additionally, the guests mentioned that the fusion of the human brain with machines, such as through brain-machine interfaces, could be a pathway to achieving AGI, but this also raises a series of moral and ethical questions.
Unraveling the Black Box of Deep Learning: Determinism vs. Probability
Ben explained that the black box nature of deep learning models is attributed to their absolute size. You are still tracking paths through a series of decision points in the network. It's just that this path is so large that it is difficult to connect the weights or parameters within the model to their specific values, as these values are derived after inputting millions of samples. You can do this deterministically; you can track every update, but the amount of data you ultimately generate will be very large.
He sees two things happening:
As our understanding of the models being built increases, the black box nature is gradually disappearing. Deep learning is a research field that has gone through an interesting rapid period, conducting a lot of experiments that are not driven by foundational research. Instead, it is more about seeing what we can get out of it. Thus, we feed it more data, try new architectures, just to see what happens, rather than starting from first principles and designing this thing while knowing exactly how it works. So there has been this exciting period where everything is a black box. But he believes this rapid growth is starting to slow down, and we are seeing people re-examine these architectures and check and say, "Why does this work so well? Let's dig deeper and prove it." So to some extent, this curtain is being lifted.
Another thing that may be more controversial is the shift in perspective regarding whether computational systems need to be completely deterministic or if we can live in a probabilistic world. We, as humans, live in a probabilistic world. The example of self-driving cars may be the clearest; when we drive, we accept that random events can occur, there may be minor accidents, and there may be issues with the self-driving car system. However, we cannot accept this at all; we say it must be a completely deterministic process. One of the challenges in the self-driving car industry is that they assume people will accept the probabilistic mechanisms applied to self-driving cars, but in reality, people do not accept this. He believes this situation will change, and what may be controversial is whether we, as a society, will allow probabilistic computational systems to coexist with us. He is unsure if this path will be smooth, but he believes it will happen.
Gradient Optimization: The Core Optimization Method of Deep Learning
Gradient optimization is one of the core methods in deep learning, playing a crucial role in training neural networks. In a neural network, a series of layer parameters are essentially real numbers. Network training involves setting these parameters to actual values that allow data to be correctly transmitted and trigger the expected output at the final stage of the network.
Gradient-based optimization methods have brought significant changes to the fields of neural networks and deep learning. This method uses gradients, which are the derivatives of the parameters at each layer of the network with respect to the error. By applying the chain rule, gradients can be backpropagated through the entire layered network. In this process, you can determine your position on the error surface. The error can be modeled as a surface in Euclidean space that appears to be a region filled with highs and lows. The goal of optimization is to find the area that minimizes the error.
The gradient shows you your position on this surface for each layer and the direction in which you should update the parameters. You can navigate this undulating surface using the gradient to find the direction that reduces the error. The size of the step depends on the steepness of the surface. If it is steep, you will jump further; if it is less steep, you will jump less. Essentially, you are navigating this surface, looking for a trough, and the gradient helps you determine your position and direction.
This method is a significant breakthrough because the gradient provides a clear signal and useful direction, allowing you to navigate more effectively than randomly jumping in parameter space, knowing where you are on the surface, whether you are at the top of a mountain, in a valley, or on flat ground.
Although there are many techniques in deep learning to solve the problem of finding optimal solutions, real-world situations are often more complex. Many regularization techniques used in deep learning training make it more of an art than a science. That is why gradient-based optimization in practice resembles art rather than precise science.

Figure 2: Simply put, the optimization goal is to find the bottom of the valley (Image Source: Deep Tide)
Conclusion
Gensyn's goal is to build the world's largest machine learning computing resource system, fully utilizing those computing resources that are idle or underutilized, such as personal smartphones, computers, and other devices.
In the context of machine learning and blockchain, the records kept on the ledger are typically the computational results, which represent the state of data that has already been processed through machine learning. This state can be expressed as: "I have machine-learned this batch of data, it is effective, and it occurred at time X year X month." The primary goal of this record is to express the result state rather than detail the computational process.
In this framework, blockchain plays an important role:
- Blockchain provides a way to record the results of data state. Its design can ensure the authenticity of data, preventing tampering and denial.
- The blockchain has an economic incentive mechanism that can coordinate the behavior of different roles in the computing network, such as the four roles mentioned: Submitter, Worker, Verifier, and Whistleblower.
- Through the current survey of the cloud computing market, we find that cloud computing is not without merit, but rather that various computing methods have their specific issues. The decentralized computing approach of blockchain can play a role in some scenarios but cannot fully replace traditional cloud computing, meaning that blockchain is not a panacea.
- Finally, AI can be seen as a productive force; however, how to effectively organize and train AI falls within the realm of production relations. This includes factors such as collaboration, crowdsourcing, and incentives. In this regard, Web 3.0 offers numerous possible solutions and scenarios.
Therefore, we can understand that the combination of blockchain and AI, especially in areas such as data and model sharing, coordination of computing resources, and verification of results, provides new possibilities for addressing some issues in the training and use of AI.
Citation
- https://docs.gensyn.ai/litepaper/
- https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
 Risk warning
Risk warning Risk warning
Risk warning