

















ZONFF Research:Web3データについて話すとき、私たちは何を話しているのでしょうか?

 Web3データの使用パラダイムはWeb2と明らかに異なり、主にデータが集まる方法にあります。つまり、異なる種類のデータの保存、インデックス、抽出、統合、利用の方法には違いがあります。
Web3データの使用パラダイムはWeb2と明らかに異なり、主にデータが集まる方法にあります。つまり、異なる種類のデータの保存、インデックス、抽出、統合、利用の方法には違いがあります。?作者:Lewis Liao,Zonff Partners
Web3 データについて話すとき、私たちは何を話しているのでしょうか?この問題を明らかにするためには、まず Web2 におけるデータのあり方を理解する必要があります。本稿では、データの生成、収集、保存、管理、使用の全ライフサイクルについて議論します。その前に、データがどのように定義されるかを明確にします。
中国全国情報安全標準化技術委員会が発表した「ネットワークセキュリティ標準実践ガイド - データ分類・格付けガイドライン」(意見募集稿 - v1.0 - 202109)では、データを個人情報、公共データ、法人データに分類しています。
具体的な定義と実例は以下の表の通りです。
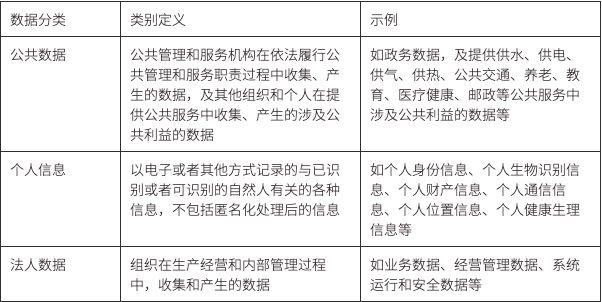
各カテゴリの上には、データ漏洩の危害対象と程度に基づいて 5 つのレベルに分けられています:公開レベル(1 レベル)、内部レベル(2 レベル)、敏感レベル(3 レベル)、重要レベル(4 レベル)、およびコアレベル(5 レベル)。公開レベルのデータは、公共財に近く、非競争的かつ非排他的です。このタイプのデータは一般的に政府や公共組織によって提供され、その利益はすべてその組織に帰属します。例えば、天気予報やマクロ経済データなどです。
1.1 データの生成、収集と保存
公共データ、個人データ、法人データの大部分は、私たちが日常的にコンピュータアプリケーションを使用する際に生成されます。その中で、一般ユーザーに直接関連するのは個人データと法人データです。
では、個人データと法人データはどのように生成され、収集されるのでしょうか?高度に抽象化されたインターネット製品システムアーキテクチャ図は以下の通りです。
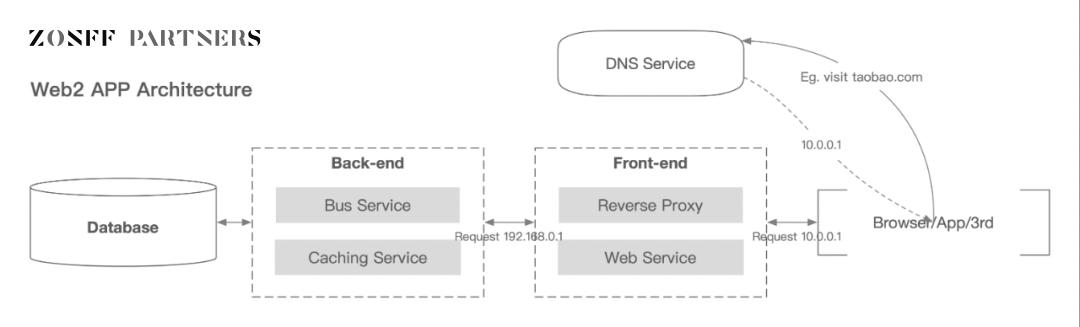
Web2 アプリケーションアーキテクチャ
画像出典:Zonff Partners
最下層のデータベースには、バックエンドから送信されたユーザーとフロントエンドのインタラクションによって生成されたデータが保存されています。広義には、これらはすべてユーザーデータです。
モバイルアプリケーションに関しては、データは以下のように分類できます:
- ユーザー情報:ユーザーがアプリサービスを使用する際に記録される、ユーザーに関連する情報。これにはユーザーの身分情報、デバイス、ネットワーク、地理的位置、さらにはモバイルデバイスにインストールされたアプリのリストなどが含まれ、サーバーデータベースと埋め込みポイントによって収集されます。
- コンテンツデータ:ユーザーがアプリサービスを使用して生成するデータ。これには、ユーザーがアプリ上でインタラクションを行って書き込む非個人情報のコンテンツデータが含まれ、アプリサービスの一部として、一般的にはサーバーデータベースによって直接収集されます。
- 行動データ:ユーザーがアプリを使用する際に生成されるインタラクションデータ。これには、ユーザーがアプリを使用している間の行動習慣(視聴時間、クリック率、浸透率、スワイプ状況など)が含まれ、一般的には埋め込みポイントによって収集されます。
- ログデータ:ユーザーがアプリを使用する際にアプリ自体が生成するデータ。これにはアプリのクラッシュログなどが含まれます。
- コードデータ:ユーザーインタラクションに関与しないデータで、フロントエンドとバックエンドのコードが含まれます。これらのデータはユーザーデータと同様に、どこかの中央集権的なサーバーに保存されています。
この分類の中で、ユーザー情報は個人情報データに、ログとコードデータは法人データに属します。特に議論の余地があるのはコンテンツデータと行動データで、これらは Web2 時代において中央集権的な実体によって自社のビジネスデータ、すなわち法人データとして分類されることが多かったです。
Web3 のアプリケーションには何が違うのでしょうか?Preethi Kasireddy のこの Web3 製品アーキテクチャが私たちの理解を助けてくれます。
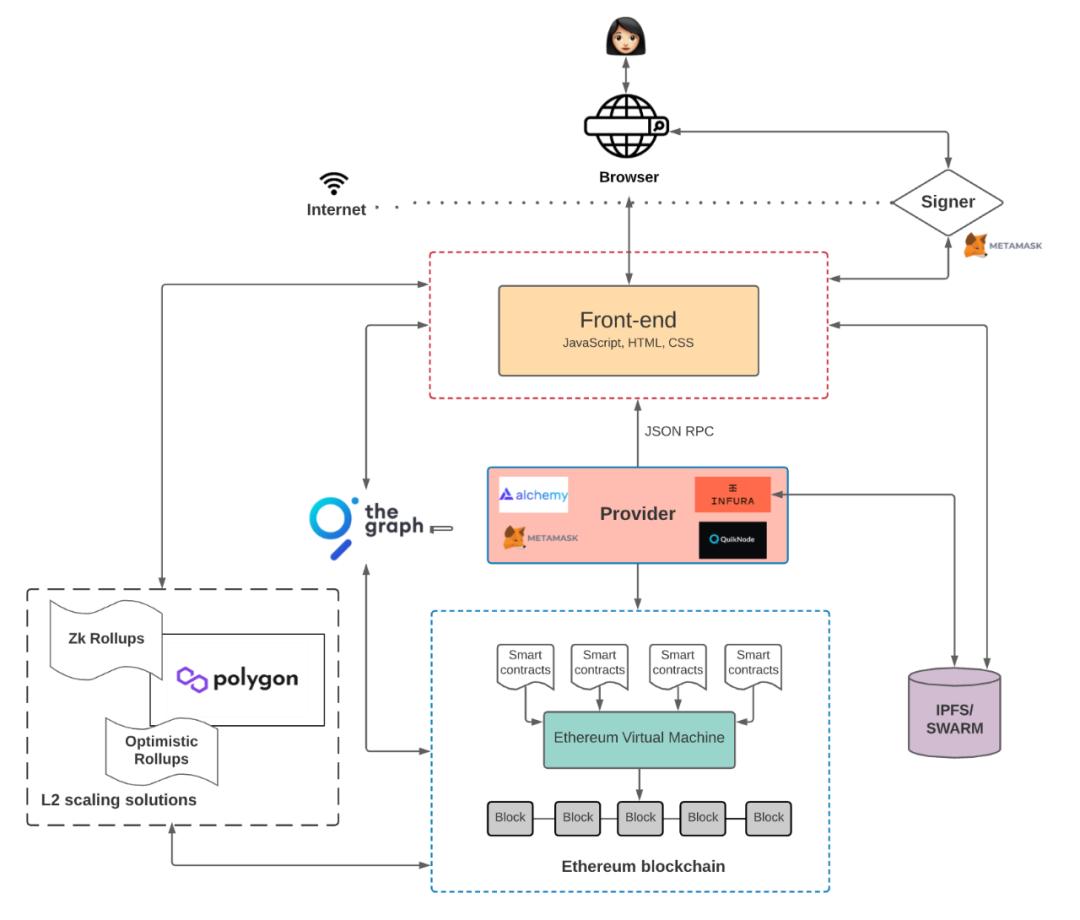
Web3 製品アーキテクチャ
画像出典:Preethi Kasireddy
Web2 アプリケーションと比較して、ユーザー端末とフロントエンドにはほとんど変化がありませんが、後端とデータベースが異なります。ユーザーはフロントエンドを通じてノードプロバイダーとインタラクションし(中央集権的なサーバーではなく)、イーサリアムなどのブロックチェーン上に配置されたコントラクトコードにアクセスし、インタラクションを行います。このプロセスでも、上述のいくつかのタイプのデータが生成されます。技術アーキテクチャの違いにより、Web3 で生成されたデータは中央集権的なサーバーに保存されることはなく、異なる方法で生成されたデータの保存方法には違いがあるかもしれません。
スマートコントラクトのインタラクションによって生成されたデータはすべてブロックチェーンに公開され、誰でもアクセスできるため、公共財となります。これには資産情報、取引データ、コントラクトコードが含まれます。理論的には、ブロックチェーンのブロックスペースが十分に大きければ、あらゆるデータをブロックチェーンに保存でき、さらには一部のプロジェクトではブロックチェーンをデータベースとして使用してデータを保存することを試みています。
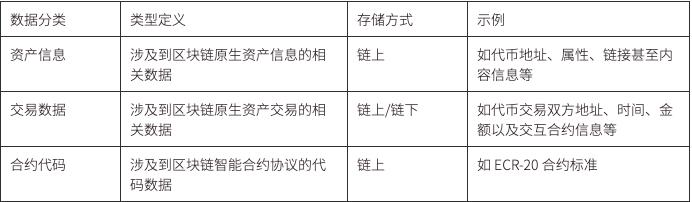
現段階では、Web3 アプリケーションが生成するデータは、上記の 3 種類のデータを除いて、大部分が依然として中央集権的なサーバーの保存方式を採用しています。これにはフロントエンドコード、ユーザー情報、コンテンツデータ、行動データ、ログデータが含まれます。これは、現在関連するストレージインフラが不十分であり、プロジェクト側が技術的な問題に制約されているか、アクセス速度を保証するためなどの理由で中央集権的なソリューションを採用しているためです。インフラの発展に伴い、IFPS、Stroj、Filecoin、Ceramic などの機能がますます強化されたストレージインフラが登場し、前端ウェブサイトを IPFS に配置し、ENS を通じてアクセスすることで、去中心化されたウェブサイトのフロントエンドを構築したり、NFT プロジェクトに関連する画像などのファイルデータを Arweave を使用して永続化するなど、ますます多くのアプリケーションが去中心化ストレージに自らを展開し始めています。
総じて、Web3 アプリケーションを構築する際に、アプリデータの保存に関して、開発者は通常 3 つの選択肢があります:
- データをブロックチェーン上に保存する。この選択肢は非常に高価で、アプリをできるだけシンプルにし、データを完全に公開することになります。利点は、アプリの主権を直接保護することです。
- スマートコントラクトのロジックをブロックチェーン上に保存し、他の部分を従来のバックエンドに保存する。この方法はユーザーの主権を犠牲にし、中央集権的なリスクがあります。これは現在のほとんどの Web3 アプリケーションが採用している方法です。
- スマートコントラクトのロジックをブロックチェーン上に保存し、他の部分を IPFS、Arweave、Ceramic などのストレージに保存し、スマートコントラクトを通じてデータを管理・更新する。この方法は高価(Ceramic は現在無料)であり、一時的には遅いですが、アプリの主権を保護することができます。
現在、ほとんどの Web3 アプリケーションは第 2 の方法で構築されており、一部の特定のアプリケーションはすでに第 3 の方法で構築できるようになっています。第 1 の方法で構築されているアプリケーションはごくわずかです。では、どの方法で保存すべきでしょうか?どのような保存方法がトレンドなのでしょうか?
1.2 トレンド:去中心化ストレージ - データとアプリの主権
Web3 アプリケーションを構築する 3 つの方法について話すとき、キーワードがあります:主権(sovereign)。この言葉は Web3 の特徴について話すときに避けて通れないトピックであり、一般的にはデータ主権とアプリ主権を含みます。では、主権は重要なのでしょうか?これは別のトピックであり、本稿では探討しませんが、興味があれば関連する記事を読むことをお勧めします。「Web3 データ市場展望」や「Web3 - Let the "right to data" awaken」などです。ここでは、データの観点から Web3 の主権確立の必然的な道筋に切り込み、インフラの発展の方向性と重点を推演します。
データ主権については、デジタル資産主権とユーザーデータ主権が含まれます。「縦の流動性:価値はどのように相互接続されるか」という記事では、トークンがユーザーのデジタル資産主権(アイデンティティ、関係、物権)を定義できることについて述べています。これは、改ざんが難しい広範な合意によって決定されます。最も基本的には、これらの権利の定義はブロックチェーン自体によって行われます。例えば、あるトークンがどのアドレスに属するかなどです。しかし、より複雑なデジタル製品の権利帰属に関わると、多くの問題が発生します。典型的な例は、NFT に対応する画像(または記事など)の保存問題です。「NFT:デジタル所有権の革命」ではこの問題について議論されています。ほとんどの NFT の現状は、その対応するデジタル製品がどこかの中央集権的なサーバーに保存されており、一度サーバーがクラッシュしたりハッキングされると、ユーザーが持っているのは単なるチェーン上のハッシュであり、ハッシュの背後にある本当の「物品」はいつでも盗まれたり置き換えられたりして、無価値になってしまいます。
さらに、ユーザーデータ主権は Web2 と Web3 の最も明確な境界線の一つであり、Web3 の革新と進歩を叫ぶ旗印です。この点に関して、Ceramic はデータ宇宙を構想しました。これは、誰もが所有するが、誰にも独占されない、組み合わせ可能なネットワーク規模のデータエコシステムです。ユーザーデータは、ユーザーがアプリからアプリへと移動する際にユーザーに付随し、ユーザーは自分のデジタル宇宙を中心に制御します。現在、これを実現できるアプリはほとんどありませんが、Cyberconnect は良い試みを行い、去中心化されたソーシャルグラフプロトコルを作成し、アプリ間でユーザーのソーシャル関係データの相互運用性を実現しようとしています。しかし、現時点では、このアプリはユーザーのデータ主権を保証しておらず、彼らはすでに Ceramic に移行して構築を始めていますが、すべてはまだ道半ばです。
アプリ主権については、主権アプリを「スーパー構造」と呼ぶ人もいます。これは、停止不可能、無料、有価、拡張可能、無許可、正の外部性、信頼できる中立性などの特性を持ち、これらを総合してデジタル世界の公共財を提供し、「メタバース」(信じるなら)を構築するインフラを作り出します。現在、ほとんどのいわゆる Web3 アプリケーションは、アプリ主権の程度が高くありません。彼らは真の公共財ではなく、権力によって容易に制裁され、変更される可能性があります。Tornado Cash の事件はこの問題を非常に直接的に示しています。その主な理由の一つは、これらのアプリのプロトコル層のコントラクトコードはすべてブロックチェーンに公開されていますが、フロントエンドやドメイン名などのコンポーネントは依然として第三者の中央集権的な実体によって制御されているからです。
データ主権とアプリ主権を実現するためには、Web3 アプリケーションの構築方法が重要です。その基本的な出発点はストレージです。データはどこに保存され、どのように保存すればユーザーが主権を持てるのか?一般的に、ユーザーデータのタイプに応じて、異なる解決策があります:
- ユーザーの資産情報、取引データは公共台帳データであり、チェーン上に存在することで検証可能性を保証することが最も重要ですが、Aztec のようなアプリがユーザーのチェーン上の取引のプライバシーを保護するために登場することは非常に価値があります。
- ユーザーのユーザー情報、コンテンツデータ、行動データは個人情報として、ユーザーの制御権を保証することが非常に重要です。ユーザーの同意の下で、これらのデータを選択的に公開し、公共財として正の外部性を発掘することができます。
- ログデータとコードデータは法人データとして、プライベート化は受け入れられ、一定の必要性がありますが、「スーパー建築」タイプの Web3 インフラアプリケーションに関しては、公共インフラの特性を持つべきであり、アプリコードの保存は公開され、プラットフォームレベルを超えた検閲耐性を持つべきです。
現在、ほとんどの Web3 アプリケーションが「スマートコントラクトのロジックをブロックチェーン上に保存し、他の部分を従来のバックエンドに保存する」方法を採用しているのは、現在十分に使いやすい去中心化インフラが存在しないためです。
まず、IPFS、Filecoin、Arweave などの去中心化ストレージは静的ストレージであり、計算能力や状態管理能力が不足しているため、データベースのような高度な機能(可変性、バージョン管理、アクセス制御、プログラム可能なロジックなど)を実現できません。一方、Ceramic は動的ストレージであり、これらの問題をある程度解決していますが、Ceramic の現在のアクセス速度は依然として遅く、開発キットも十分ではなく、その去中心化の程度も常に批判されています。
IPFS、Filecoin、Arweave などの去中心化ストレージの主な役割は、画像、文書、静的コードなどのファイルの非構造化データを静的に保存することです。これにより、改ざんが難しい特性が一定程度で NFT のようなデジタル主権を保証します。チェーン上のハッシュコードとチェーン外の去中心化ストレージアドレスとの関係が一度確立されると、外部の力によって非常に手段で影響を受けることは難しくなります。また、フロントエンドコードがその上に構築されることで、アプリ主権の完全性も促進されますが、現在の段階のストレージ技術は単に保存するだけであり、計算能力の不足がその機能サポートを中央集権的なサーバーソリューションに大きく遅れさせています。
現在市場に出回っている主流の去中心化ストレージの状況は以下の表に示されています。この表は「Web3 去中心化ストレージ進化史」を参考にしてまとめたものです。
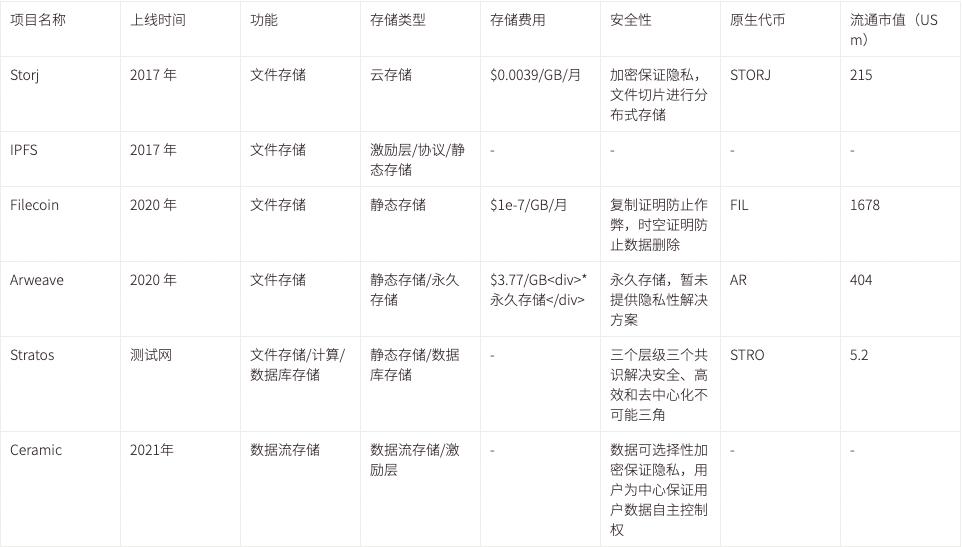 データ出典:CoinmarketCap
データ出典:CoinmarketCap
時間:2022 年 8 月 23 日
現在のところ、ほとんどのストレージソリューションは「去中心化ハードディスク」を実現しただけであり、最も基本的なニーズを満たしています。より高度なストレージに基づく計算ニーズは完全には満たされていません。これらの計算には、ローカル開発環境のレンダリング、データフローの挿入と抽出などが含まれ、これらは現在の Web2 アプリケーションで最も一般的で必要な機能モジュールです。Ceramic のデータフローストレージに基づく革新により、データの権限管理、バージョン管理、動的ストレージ、可組み合わせ性が実現され、Stratos はデータベースストレージ、静的ストレージ、計算、合意などの複数のモジュールを含む、より完全な一式のソリューションを提供しようとしています。さらに、Arweave と Filecoin も計算の重要性を認識し、関連モジュールのエコシステム構築を促進しています。例えば、Filecoin はすでに FVM を導入して Filecoin 上での計算をサポートしています。
2.1 データの管理
Web3 アプリケーションを去中心化ストレージの上に構築することで、外部からの干渉を受けにくくなり、独占と権力を打破します。しかし、単に保存するだけでは不十分で、ストレージ環境のレンダリング計算、データ処理、権限設定、プライバシー保護などの技術的サポートが必要です。これにより、アプリの主権とユーザーのデータ主権を保証し、デジタル世界における個人主権の台頭を実現します。特に権限制御とプライバシー保護の問題は、高度な主権技術ソリューションによって実現されるべきです。Web2 アプリケーションでは、これらのレベルのデータは異なるセキュリティ保護レベルに基づいて、特定の中央集権的なサーバーに保存されています。そのセキュリティはネットワークセキュリティによって保証され、主権はプラットフォームによって保証されます(企業プラットフォーム、政府プラットフォームなど)。このようなデータ管理モデルでは、ユーザーはスーパー管理者に従属し、データ自体に対してユーザーは何の権利も持ちません。さらに、データセキュリティもスーパー管理者という中央集権的な実体に制約されます。最近、ある地域での公安データ漏洩事件では、スーパー管理者がその秘密鍵を漏洩させ、数億人の個人情報が漏洩しました。
Web3 のデータ管理は以下の 2 つの特性を持つべきです:
- データ主権の保障。これはプラットフォームレベルを超え、さらには世界レベルで、世界的な合意によってデジタル世界のユーザーの共通の権利を保障するべきです。従来の世界では、この面での保障はプラットフォームレベルであり、ルールは合意から来ていません。プラットフォームレベルの企業がすべてのルール制度を掌握し、いつでも変更できるため、ユーザーの個人主権を侵害することができます。
- データプライバシーの保障。数学的にユーザーデータのプライバシーセキュリティを保障するために暗号学を使用し、データベースネットワークセキュリティの方法で保護するのではなく、ユーザーが制御する選択的な暗号化はユーザーデータ主権の基本的な権利の一つです。
Web3 データをどのように管理するかは、そのデータがどのように保存されているかに依存します。
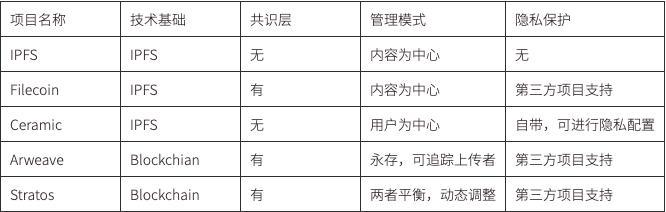
IPFS と Filecoin はコンテンツ中心で、Content ID(CID)を通じて保存されたコンテンツにアクセスします。この基盤の上に、ChainSafe Files のような第三者アプリケーションを構築してデータ管理を行うことができます。これにより、ローカル化された方法でシングルサインオンの問題を解決し、非対称暗号を使用してデータを暗号化して保存できます。コンテンツ中心の管理モデルは、ユーザー管理を困難にし、データに所有権を付与することが複雑になります。Filecoin はストレージを提供するだけでなく、そのエコシステムの拡張性は他の基盤よりも高いです。特に、今後 FVM が導入されることで、データストレージやデータ検索に関する特定のツールがいくつか登場し、ユーザーや企業がデータをより良く管理し、データの安全性を保証し、新しいアプリケーションを開発するのに役立つでしょう。
Ceramic も IPFS に基づいていますが、ユーザー中心で、IDX プロトコルに基づいて、3ID DID メソッド(CIP - 79)を使用して Ceramic-native のアカウントシステムを構築しています。これにより、ユーザーはブロックチェーンウォレットを使用して 3ID DID をデータフロー上で取引を実行し、自分のデータを管理できます。これは、DID をデータに関連付けてデータモデルに保存することで実現され、データモデルはユーザーデータのフォーマット(スキーマ)を定義します。同じデータモデルを使用するアプリは、そのデータフォーマットを共有します。
Arweave は、一度の支払いで永久保存されるチェーン上のデータ去中心化ストレージプロジェクトであり、データは公開透明にチェーン上に保存され、誰でもアクセスできます。Arweave ブロックチェーンブラウザを通じて、チェーン上に存在するデータを閲覧できます。このようなモデルでのデータ管理は、チェーン上のデータを管理するのと全く同じであり、アクセス権限の制御や元のデータの「ホットアップデート」はありません。データを更新するたびに、そのインデックスアドレスは変更されます。これは IPFS や Filecoin には問題がありませんが、その利点はデータがどのユーザーに帰属するかが非常に明確であり、データ権利の追跡に役立ちます。
Stratos もブロックチェーン合意に基づくストレージであり、データストレージのパスを記録するインデックスツリーを専用に維持し、データの更新を追跡します。Arweave とは異なり、Stratos の各ストレージノード(リソースノード)は、計算能力、ストレージ、コンテンツアクセス制御サービスを同時に持つように設計されています。プロジェクト側は、データの動的スループットのためにブロックチェーン自体に基づくデータベースを構築し、その形態と管理モデルは去中心化クラウドコンピュータに近いです。
2.2 トレンド:去中心化データ市場
ユーザーがデータの所有権を持つ場合、データ市場は必然的なトレンドです。データは資本要素として流通します。Filecoin ではデータ市場の試みがあり、Fivehive は去中心化アプリ開発スタジオ OB1 によって構築され、維持されています。これはオープンソース市場であり、データセットのアップロード、維持、購入、(または)譲渡をサポートしています。このプロジェクトは、2 年前に GitHub での更新と維持を停止しており、大多数の可能性は失敗したと考えられます。
Ceramic のデータモデル市場
Ceramic はそのデータ宇宙において、彼らが構築するオープンデータモデル市場について言及しています。データは相互運用性が必要であり、生産性の向上を大いに促進します。このようなデータモデル市場は、データモデルの緊急合意を通じて実現されます。これは、イーサリアムの ETC コントラクト標準に似ており、開発者は機能テンプレートとして選択でき、データモデルに準拠したすべてのデータを持つアプリケーションを所有できます。現時点では、このような市場は取引市場ではありません。
データモデルについての簡単な例は、去中心化ソーシャルネットワークにおいて、データモデルを 4 つのパラメータに簡略化できることです:
- PostList:ユーザーの投稿のインデックスを保存
- Post:単一の投稿を保存
- Profile:ユーザーのプロフィールを保存
- FollowList:ユーザーのフォロリストを保存
では、データモデルはどのように Ceramic 上で作成、共有、再利用され、アプリケーション間でデータの相互運用性を実現するのでしょうか?
Ceramic はデータモデルレジストリ(DataModels Registry)を提供しています。これはオープンソースで、コミュニティ共同構築のための Ceramic 用の再利用可能なアプリケーションデータモデルのリポジトリです。ここで、開発者は既存のデータモデルを公開登録、発見、再利用できます。これは、共有データモデルに基づく顧客操作アプリケーションの基盤です。現在、これは GitHub に基づいていますが、将来的には Ceramic に分散される予定です。
レジストリに追加されたすべてのデータモデルは、自動的に @datamodels の npm プラグインパッケージに公開されます。任意の開発者は @datamodels/model-name を使用して 1 つまたは複数のデータモデルをインストールし、これらのモデルを使用して、任意の IDX クライアントでデータを保存または取得できます。これには DID DataStore または Self.ID が含まれます。
さらに、Ceramic は GitHub に基づいて DataModels フォーラムも構築しており、データモデルレジストリ内の各モデルにはそのフォーラムに独自の議論スレッドがあります。コミュニティはこれを通じてコメントや議論を行うことができます。また、ここでは開発者がデータモデルに関するアイデアを投稿し、レジストリに追加する前にコミュニティの意見を求めることもできます。現在、すべては初期段階にあり、レジストリ内のデータモデルは多くありません。レジストリに収納されるデータモデルは、コミュニティの評価を通じて CIP 標準となるべきであり、これはイーサリアムのスマートコントラクト標準のようなものです。これにより、データに可組み合わせ性が提供されます。
Ocean のデータ取引市場
Ocean Protocol はデータ取引市場を中心に、去中心化されたデータサービス供給チェーンネットワークを構築しています。下の図は、データサービス供給チェーンを作成するために必要な主要なサービスを示しています。データ、アルゴリズム、計算、ストレージ、分析、キュレーションを提供します。これらのコンポーネントは、サービス実行プロトコル(サービスレベルアグリーメント)、安全な計算、アクセス制御、許可と結びついています。
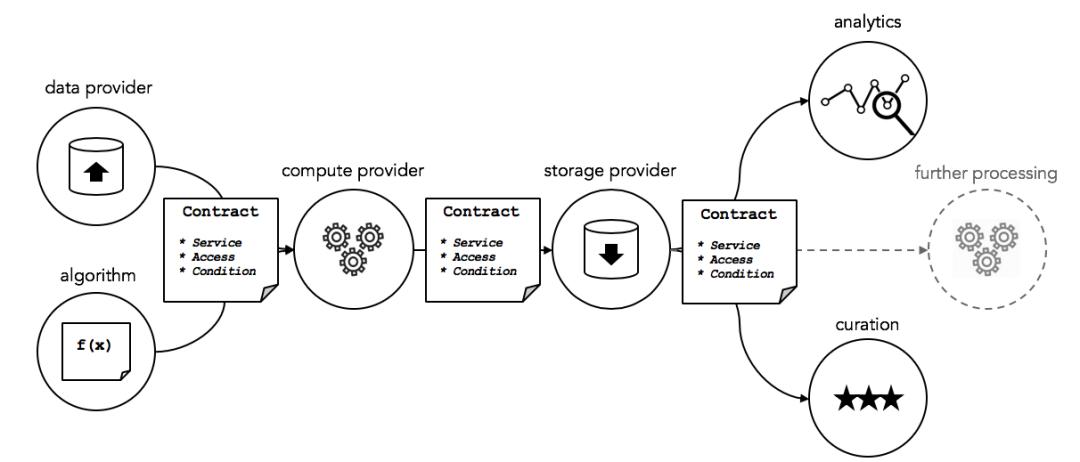
画像出典:Ocean Protocol
主要な参加者は、データ使用者、サービス提供者、市場、サービス発行者、検証者、キュレーターです。Ocean は全セットのデータサイエンスツールを提供し、データ使用者は Ocean 上でデータサービスパイプラインを構築し、データアルゴリズムを自動化してデータを加工処理し、価値を発見します。このプロセスでは、データ使用者はすべてのデータセットをダウンロードしたり、すべてのデータセットを見ることはできないため、データセットが盗まれることを防ぎます。使用者が購入するのはデータセットの使用権であり、そのデータセットを所有することではありません。
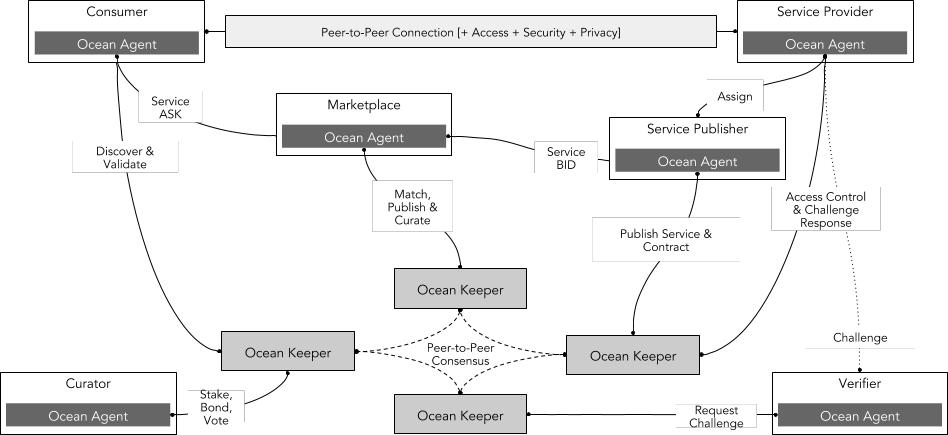
出典:Ocean Protocol
さらに、Ocean は他の機関と協力してデータ市場を構築しています。例えば、メルセデス・ベンツの去中心化データ市場 Acentrik と最近発表されたエンタープライズリリースで提携しました。Acentrik Marketplace は OceanONDA V4 スマートコントラクトとライブラリによって駆動され、データサービスを発行し、データトークンと Acentrik 資産管理トークンをデプロイおよび鋳造し、消費するために費用をかけます。
3.1 データの使用とスタック
上記の内容を理解した上で、Web3 データスタックを提案します。下の図を参照してください。
- 最下層はデータソースが保存される場所で、去中心化ストレージ、チェーン上およびチェーン下のデータなどが含まれます。
- 次に、これらのデータを管理するアプリケーションがあり、データベース、データテーブル、インデックスミドルウェア、データ市場などが含まれます。
- 一定のデータ管理パラダイムの下で、データを掘り起こすことができ、アルゴリズムモデリング、統計分析、データ可視化などが含まれます。

Web3 データスタック
画像出典:Zonff Partners
現在、業界内での Web3 のデータ使用は、ほとんどがチェーン上のデータであり、次々とデータ分析ツールやインデックスツールが登場しています。チェーン上のデータという巨大な金鉱はすでに十分に掘り起こされており、上の図のデータテーブルや分析アプリケーションの分類のほとんどはチェーン上のデータの掘り起こしに関するものであり、わずかにチェーン下のデータに関わるものがあります。一般的に、データの使用の流れは ETLA(Extract、Transform、Load、Analysis)のプロセスであり、各ノードには代表的なプロジェクトがあります。抽出(Extract)プロジェクトの代表は The Graph で
 リスク警告
リスク警告 リスク警告
リスク警告











