Talkie:現代の知識を剥ぎ取り、AIの基礎能力を再考する

 副題:1931年前のテキストを読み取るだけのモデルが、AIの知識記憶と基礎能力を再区別しています。
副題:1931年前のテキストを読み取るだけのモデルが、AIの知識記憶と基礎能力を再区別しています。最近、Talkieという名のレトロな言語モデルがAI界で議論を呼んでいます。その核心的な特徴は、訓練データが極度に制限されていることです。この13Bパラメータを持つモデルは、2600億トークンを基に訓練され、主に1931年以前の英語のテキストを読み込んでいます。これには古い書籍、新聞、雑誌、科学論文、特許、百科事典が含まれます。公式にはVintage Language Modelと定義されています。

より大きな文脈、広範な知識のカバレッジ、リアルタイムの更新を追求する時代において、Talkieの設定は異常に見えます。
現代の大規模モデルは通常、現代のインターネットコーパスで訓練されています。これらはPythonコードに精通し、GitHubのイシューに慣れ親しみ、今日のソーシャルメディアの文脈に精通しています。一方、Talkieは1930年代の知識の境界に閉じ込められた研究対象のようです。第二次世界大戦後の世界を見たことがなく、インターネット、暗号通貨、現代のソフトウェア工学に実際に触れたこともありません。この現代知識からの切り離しは、基礎的な能力を観察する実験サンプルとしての役割を果たしています。
知識と基礎能力の分解
Talkieを通じて、研究者は本質的な問題を観察できます:もしモデルが現代の世界を見たことがなければ、言語構造や文脈の例からどれだけの能力を学べるのでしょうか?
現代モデルの評価において、論理的推論はしばしば資料の記憶と混ざり合います。モデルがPythonコードや現代の政治問題に正解した場合、それが本当に基礎能力を持っているのか、単に訓練データに関連するテスト問題が含まれていただけなのかを見分けるのは難しいです。Talkieはこの二者を区別しました:
- 時代のずれ(Anachronism): もし「国連がいつ設立されたか」を知らなければ、それは言語理解能力が低いことを意味しません。なぜなら、1930年以前には国連の概念が存在しなかったからです。これは知識の欠如であり、能力の欠如ではありません。
- パターンの一般化: 研究者は、TalkieがPythonを全く見たことがないにもかかわらず、いくつかのfew-shotの例を通じて、言語構造から非常に単純なコードロジックを導き出せることを発見しました。これは、Transformerアーキテクチャ自体が基礎的な一般化能力を持っていることを証明しており、単に記憶に頼っているわけではありません。

「双子」対照実験
データ分布の影響を検証するために、研究チームは完全に同じアーキテクチャのModern Twinを作成しました。違いは、後者が現代のウェブデータFineWebを読んでいることだけです。
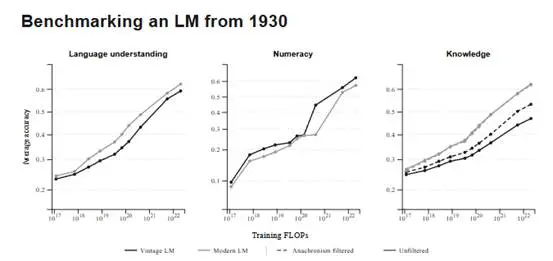
最初、Talkieは標準テストで全面的に劣っていましたが、これは1930年以降の知識が欠けているモデルにとって不公平です。興味深いことに、研究者が1930年の視点から見て「未来」に属する問題をフィルタリングすると、Talkieと現代モデルのパフォーマンスの差は約半分に縮まりました。
これは、言語理解の基礎能力が現代のインターネットに完全に依存していないことを示しています。高品質の古い新聞、科学雑誌、法律文書には、人類が蓄積した常識のパターン、論理的因果関係、論証のルールがすでに含まれています。モデルがこれらのテキストから学ぶのは、概念がどのように結びつき、証拠がどのように判断を支持するかということであり、これらの基礎的な論理は異なる時代において高度な安定性を持っています。
設計原則へのインスピレーション
可追跡性、検証、推論経路に関心を持つAIシステムにとって、Talkieは有用な設計原則を示しました:モデル本体は新しい事実をすべてパラメータに押し込む必要はありません。
より堅牢な道筋は、基礎モデルが安定した言語能力、推論構造、一般的なパターンに集中することです。これらの能力は、高品質で高密度の歴史的テキストから習得できます。そして最新の事実、技術仕様、リアルタイム情報は、検索システム、知識ベース、ツール呼び出しに任せるべきです。
モデルに理解と分解を担当させ、外部システムに更新と実行を担当させることが、単により大きな事前訓練コーパスを追求し、モデルを記憶に依存する「背題家」にすることよりも、実際の生産環境のニーズに近づくでしょう。
結論
Talkieの価値は、明確な実験の境界を定義したことにあります。それは業界に対して、「新しい資料」を「新しい能力」と直接同一視しないこと、また「知識のカバレッジ」を「基礎能力」と直接同一視しないことを思い出させます。
AIの進化論理は移行しています:無限にウェブデータを積み上げるよりも、厳選されたコーパスから論理的フレームワークを抽出し、外部の知識ベースを活用して実戦問題を解決するシステムが、次の段階の競争の核心に近づいています。
 リスク警告
リスク警告