

















Cipholio 심층 분석: ZKVM의 방안 및 미래에 대한 논의

 본 문서는 생태 발전 관점에서 ZK 기술과 그 응용 사례를 분석하고, 현재 ZK 관련 경쟁 구도를 설명하며, 미래 발전 방향에 대한 몇 가지 상상을 제시할 것입니다.
본 문서는 생태 발전 관점에서 ZK 기술과 그 응용 사례를 분석하고, 현재 ZK 관련 경쟁 구도를 설명하며, 미래 발전 방향에 대한 몇 가지 상상을 제시할 것입니다.作者: Yolo,Cipholio Ventures
TL; DR
ZK 기술은 프라이버시와 확장성 두 가지 주요 사용 사례를 가지고 있습니다. 프라이버시를 논할 때, 우리는 ZK 기술을 이용해 체인 외 데이터를 보호하여 외부에서 접근할 수 없도록 합니다. 반면, 확장성을 논할 때는 ZK를 이용해 체인 상의 계산 공간을 절약합니다. 예를 들어, 특정 계좌에 100원이 있는지 확인하려면 전통적인 블록체인 방식은 모든 노드가 한 번씩 확인해야 하지만, 이제는 하나의 노드만 필요하며, 데이터 무결성을 보장하는 전제 하에 최근 100원의 순유입 증명을 찾으면 계좌에 100원이 있음을 증명할 수 있습니다. 전자의 경우 많은 계산과 증명이 필요하지만, 후자는 체인 외 증명만 필요합니다.
ZKVM 발전의 핵심은 ZK 잠재력을 발휘하는 것이 중요한지, 아니면 현재 개발자 자원을 활용하는 것이 중요한지에 대한 균형입니다. ZK 잠재력을 발휘하는 것은 CPU 레지스터의 하드웨어 가속, IR 언어와 어셈블리 언어의 재구성을 의미합니다. 반면, 개발자 자원을 활용하는 것은 Solidity를 바이트코드로 변환한 후, 바이트코드가 매핑된 opcode를 ZK 증명하는 문제를 의미합니다.
모듈화 블록체인 관점에 따르면, L1은 합의 문제를 해결하고, L2는 계산 및 실행 문제를 해결하며, DA 계층은 데이터 접근성과 무결성 문제를 해결합니다. ZK 유형의 L2는 그 증명을 제공합니다.
어셈블리 언어로 독립적으로 설계된 ZK 증명의 전용 ZKapp는 낮은 조합성과 분리 능력으로 인해 미래 발전 과정에서 큰 장애물에 직면할 것입니다. 이러한 솔루션은 다른 ZK 솔루션과 호환되지 않는 VM, 언어, 증명과의 불일치로 인해 호출의 어려움이 큽니다.
의존성, 시계열 거래 로그, 데이터 보안성과 증명의 무결성은 실행의 신뢰성을 결정합니다. 현재 ZK 솔루션의 대부분이 폐쇄 소스 상태에서 ZK 보안 감사는 큰 발전 가능성을 가지고 있습니다.
ZKP는 체인 외 데이터에 의존하기 때문에 DA 체인에 맡기면 데이터의 프라이버시를 잃게 됩니다. 데이터 프라이버시와 ZK 증명 노드의 악의적 행동을 호환하려면 새로운 솔루션이 필요합니다. 우리는 MPC/FHE와 같은 안전한 계산 솔루션의 미래를 기대합니다.
다양한 회로의 지속적인 성숙에 따라 ZK 증명은 효율성과 분업을 맞이할 수 있으며, ZK 증명의 하드웨어 가속 솔루션과 전문 ZK 채굴자도 등장할 수 있습니다.
ZKP 경험의 한계 문제. 전형적인 문제에는 제약 시스템이 데이터를 효과적으로 제약하지 못하고, 복잡한 교차 명제를 증명할 때 제약이 충분하지 않은 문제; 개인 데이터 유출, 개인 데이터를 공개 데이터로 처리; 체인 외 데이터에 대한 공격, 계약 계층의 "메타데이터 공격"; ZK 증명 노드의 악의적 행동 등이 포함됩니다.
단기적으로 ZK 솔루션의 안전성에는 한계가 있으며, 현재 많은 합의는 체인 외 노드의 자율성에 기반하고 있으며, 체인 외 환경의 안전성을 보장하기 위한 일련의 필수 도구(테스트, 증명 등)가 부족합니다.
개요
ZK 기술은 복잡한 전문 용어로 인해 사람들이 이 주제에 대해 충분히 논의하기 어렵습니다. 본 문서는 생태계 발전 관점에서 ZK 기술과 그 응용 사례를 분석하고, 현재 ZK 관련 경쟁 구도를 설명하며, 미래 발전 방향에 대한 몇 가지 상상을 제시합니다. 본 문서에서는 다음을 중점적으로 논의합니다:
- ZK 기술을 논할 때 우리는 무엇을 논하고 있는가? (지식 기반, 기관 투자자는 두 번째 부분부터 읽을 수 있습니다.)
- 기술 발전 관점에서 gzkvm(일반화된 zk vm)의 발전 규칙과 구조는?
- 현재 주요 ZKvm 기술 솔루션의 비교?
- 분석 및 전망
1. 가상 머신 ABC--일상적인 컴퓨터에서 시작하기
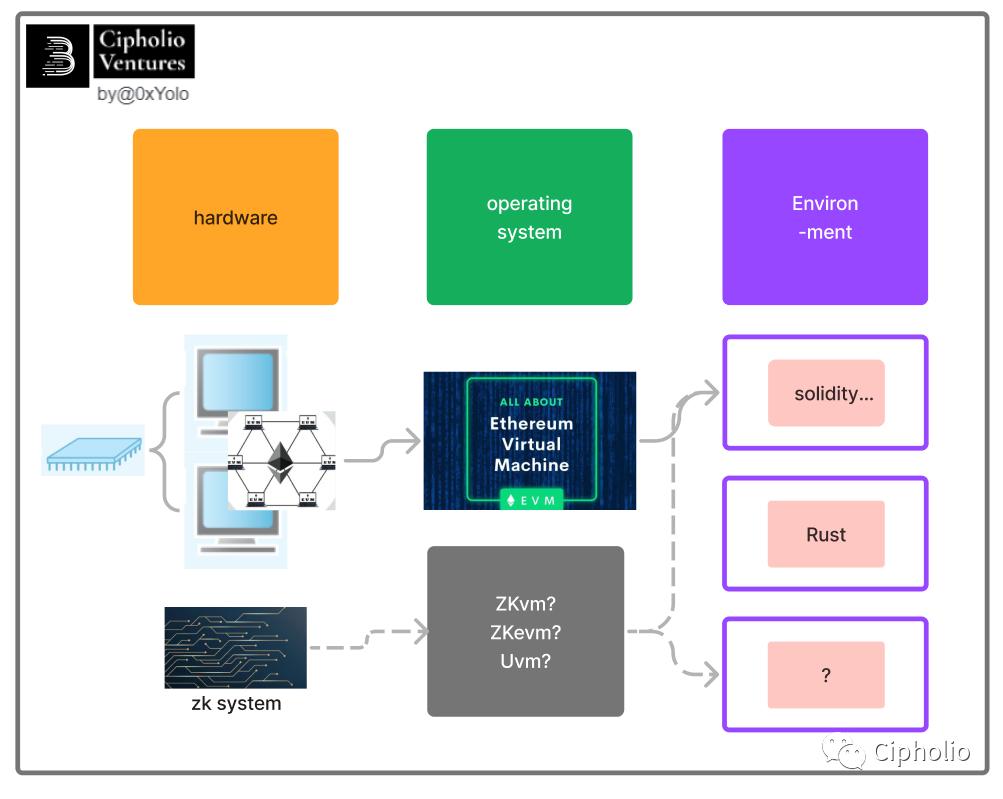
ZKEVM 관련 지식을 소개하기 전에, 먼저 우리가 일상적으로 사용하는 컴퓨터 구조에 대해 이야기하고자 합니다. 우리는 컴퓨터가 소프트웨어와 하드웨어 두 부분으로 나뉜다는 것을 알고 있습니다. 소프트웨어가 하드웨어에서 원활하게 실행되기 위해서는 소프트웨어에 적합한 실행 환경을 매칭해야 합니다. 구조적으로 실행 환경은 [하드웨어 + 운영 체제] 두 부분으로 구성됩니다.
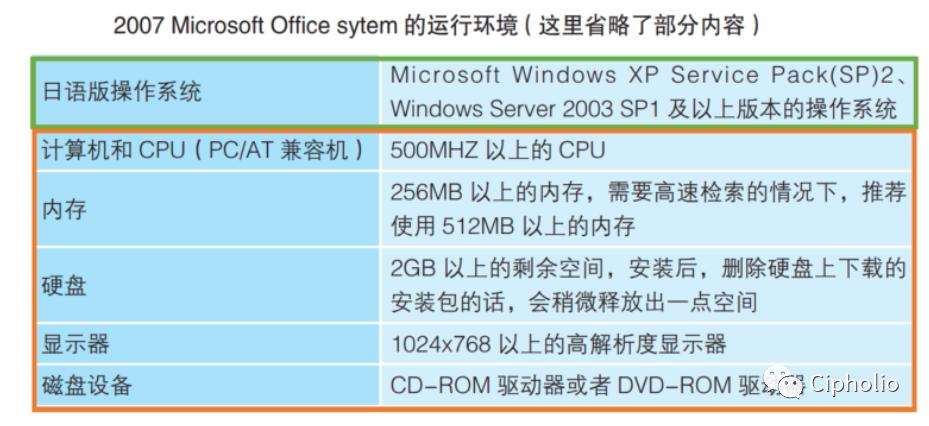
여기서 노란색 부분은 하드웨어, 초록색 부분은 운영 체제입니다. 여기서 학생들이 의문을 제기할 수 있습니다: 왜 실행 환경이 운영 체제와 동등하지 않은가? 이는 운영 체제가 모든 하드웨어와 호환되기 어렵기 때문이며, 운영 체제와 하드웨어의 매칭만이 소프트웨어에 서비스를 제공할 수 있습니다. 이 문제는 ZKVM 발전 경로에서도 다시 언급될 것입니다.
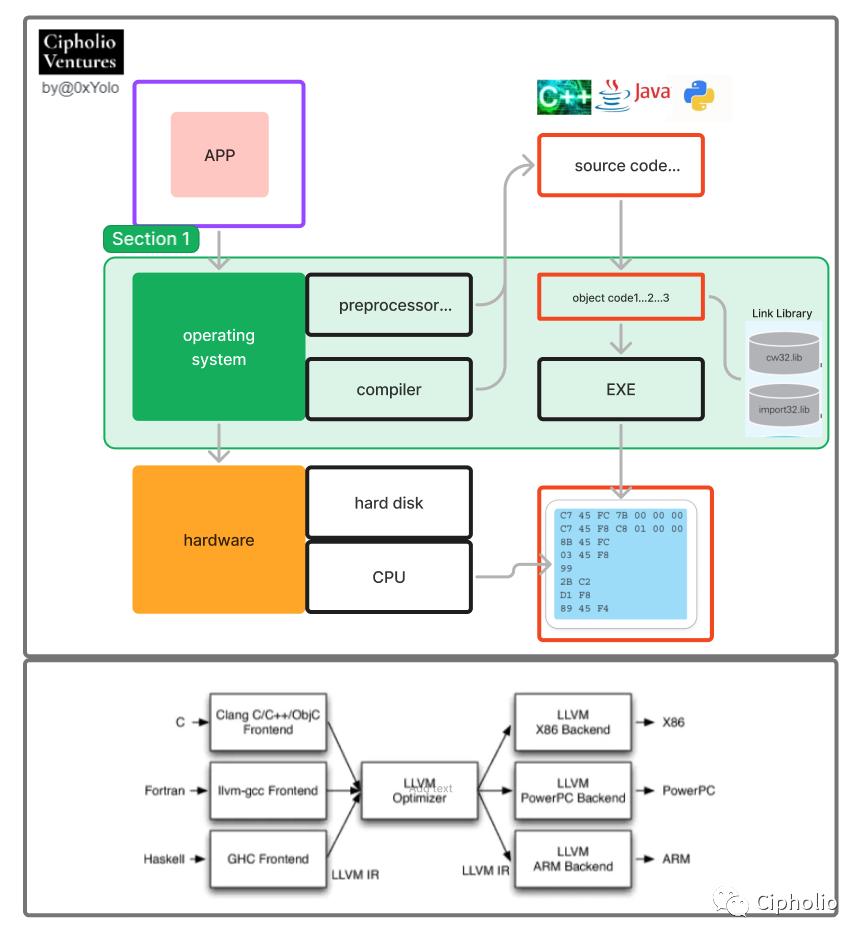
실행 환경이 마련되면, 구체적인 소프트웨어(프로그램/app)가 필요하여 구체적인 요구를 실현할 수 있습니다. 프로그램은 어떻게 실행될까요?
그림에서 볼 수 있듯이, 소프트웨어는 운영 체제를 통해 하드웨어 계층에서 계산을 수행하는 전체 프로세스를 거칩니다. 이 과정에서 프로그램 언어는 세 가지 단계의 변화를 겪습니다. 고급 언어는 프로그램을 작성하여 실제 요구를 완료하고, 어셈블리 언어는 컴퓨터와 소통하며, 저수준 로컬 코드(16진수)는 컴퓨터가 구체적으로 실행합니다. 구체적으로 보면, 프로그래머가 APP의 코드를 작성한 후, 번역기를 통해 obj(목표 언어)로 번역됩니다. 이러한 이산적인 목표 언어는 운영 체제 내의 링커를 통해 연결되어, 두 개의 출력 가능한 exe 파일이 하드디스크에 저장됩니다.
실행할 때 exe 파일은 데이터를 메모리에 넣고, CPU를 통해 Obj를 로컬 코드(바이트코드)로 변환하여 계산 작업을 수행하고, app의 I/O를 실현합니다. 이 과정에는 매우 많은 선택이 존재하며, 다양한 언어, 다양한 운영 체제, 다양한 하드웨어가 상업적 관점에서 매우 많은 트레이드오프를 직면하게 됩니다. 이러한 선택은 최종적으로 컴파일러 커널 LLVM(저수준 가상 머신)의 개선에 반영됩니다.
아래 그림에서 하드웨어(노란색)와 운영 체제 간의 다양한 대응 관계와 제한 조건을 볼 수 있습니다:
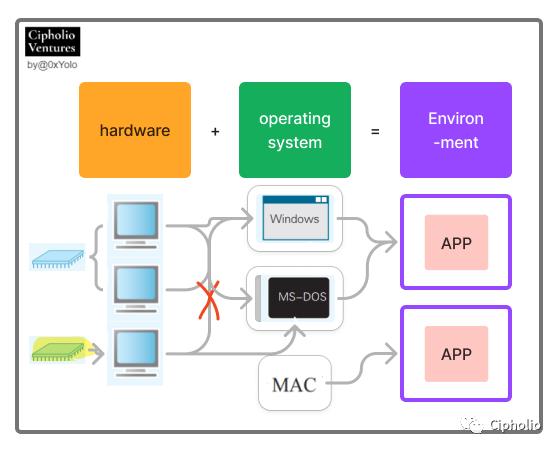
동일한 유형의 하드웨어는 여러 가지 운영 체제를 설치할 수 있으며, 서로 다른 하드웨어는 서로 다른 유형의 운영 체제와 매칭해야 합니다. 예를 들어, 동일한 AT 호환 기계 A에서 Windows와 LinuxB와 같은 운영 체제를 모두 설치할 수 있습니다. 또 다른 예로, X86 칩의 하드웨어는 x86 버전의 Windows와 매칭되어야 합니다. 이는 주로 운영 체제의 저수준 어셈블리 언어가 칩과 매칭되어야 하기 때문입니다.
앱의 성공적인 실행은 CPU와의 매칭이 필요하며, 운영 체제와의 매칭도 필요합니다. 예를 들어: 1. Office 2017의 정상적인 실행을 보장하기 위해서는 x86C CPU가 필요합니다; 2. 일부 APP는 Windows XP에서만 실행되며, 2000에서는 실행되지 않습니다.
CPU는 자신의 고유한 기계어만 해석할 수 있습니다. 서로 다른 CPU는 해석할 수 있는 기계어의 종류가 다릅니다. 즉, 서로 다른 고급 언어로 작성된 APP가 운영 체제를 통해 CPU가 계산할 수 있는 언어로 컴파일되지 않으면, CPU는 실행할 수 없습니다.
2. Zk VM은 무엇인가?
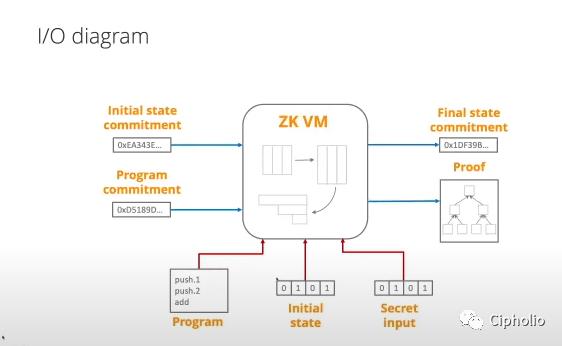
우리가 ZK를 논할 때, 일반적으로 세 가지 맥락에서 논의합니다:
- ZK를 스케일링 솔루션 RollupL2로 사용하는 것.
- ZKP를 이용한 증명의 응용, dydx, Zklink 등.
- zkproof를 암호 알고리즘으로 사용하는 것.
어떤 언어로, 어떤 환경에서, 어떤 하드웨어를 실행하는가? 이것이 광의의 VM이 해결해야 할 문제입니다.
앞서 전통적인 운영 체제(또한 VM의 일종)를 소개했듯이, ZKVM을 살펴보면 ZKVM도 유사한 기능을 수행하며, 하드웨어 계층(원주 체인 + ZK 증명 시스템)과 고급 언어(솔리디티 또는 원주 ZK 언어) 간의 소통을 완성합니다. 그 핵심은 데이터 증명과 상태 업데이트입니다. 시스템이 두 가지 입력, 원시 데이터(상태와 명령)와 증명(상태와 명령에 대한 관련 증명)을 수신하면, 비교 계산 후 명령(상태 업데이트)과 ZKP(증명)를 출력하고, L1에 제출하여 합의 방송을 합니다.

구체적으로 ZK 증명은 몇 가지 부분을 거칩니다(저자: JP Aumasson, Taurus):
로컬 계산;
회로의 정의. 예를 들어, 지갑에 돈이 있는지 확인하고, 정보가 완전한지 확인하며, 서명이 올바른지 확인합니다;
수학적 증명: 수학적 방법을 사용하여 계산이 실행 가능함을 증명합니다.
수학적 증명 결과와 실제 결과를 비교합니다.
결과를 체인에 제출합니다.
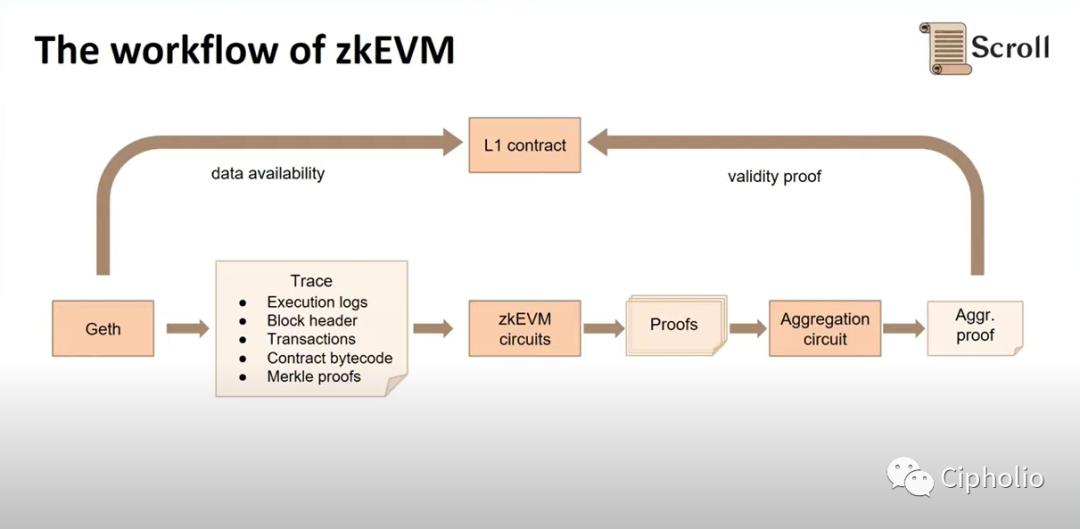
Scroll의 솔루션을 예로 들면, Geth에서 출발하여 시스템이 로컬 계산을 완료하고 거래 추적(거래의 역사 로그)을 분해하여 회로 연산자로 변환한 후, 수학적 방법(예: 다항식 분해, 암호학)을 사용하여 ZK 증명을 도출합니다. 그런 다음 데이터와 증명을 비교하여 오류가 없으면 체인에 방송합니다. 이 과정에는 회로를 설정하는 방법, 어떤 종류의 회로가 있는지, 회로를 어떻게 분해할 것인지와 같은 많은 핵심 기술이 포함됩니다. 전체 확인 방법은 거대한 표를 상상할 수 있으며, 각 변수는 그 매개변수를 가지고 있으며, 알려진 역사적 데이터의 배경 하에 특정 결과의 필연성을 구합니다.
예를 들어, 특정 계좌에 100원이 있는지 확인하려면 전통적인 블록체인 방식은 모든 노드가 한 번씩 확인해야 하지만, 이제는 하나의 노드만 필요하며, 데이터 무결성을 보장하는 전제 하에 최근 100원의 순유입 증명을 추가하여 확인하면 됩니다(사례의 경우는 비교적 간단하여 한눈에 알 수 있지만, 실제 상황에서는 수학적 연산이 필요합니다). 완료되면 계좌에 100원이 있음을 증명할 수 있으며, 전자는 모든 노드의 계산이 필요하지만 후자는 단일 노드의 계산과 zk 증명만 필요합니다. 이 예에서 확인하는 것은 "체인 외에서 계좌에 충분한 잔액이 있음을 증명하는 방법"이며, 증명에 필요한 제약은 "최근 역사 시간축 내에서 계좌의 순유입이 100을 초과할 때(실질적으로 Merkle Root의 증명에 기반하여), 노드 계산 결과와 ZKP를 비교하여 상태가 올바른지 결정합니다.
ZK 언어의 공약수

MidenVM의 요약에 따르면, 현재 시장에서 주요 Zkapp이 사용하는 도구는 주로 WASM과 RISC V 기반의 어셈블리 언어입니다. 일부 도구 키트는 애플리케이션에 "ZK" 개념이나 태그를 빠르게 부여할 수 있습니다. 그러나 구조를 조금 분해해 보면, 전통적인 스마트 계약은 L1이 안전성을 보장하고, 전체 네트워크 방송을 통해 합의의 안전성이 역사적으로 검증되었습니다. 반면, 체인 외 ZKP 증명을 이용할 경우 ZKP 증명 노드가 악의적 행동을 할 가능성이 존재합니다.
개발자가 제약(Contraint)을 합리적으로 설정할 수 있는 능력 문제는 차치하고, ZKP 증명 노드의 악의적 행동 의지를 방지하는 방법이 더욱 중요합니다.
예를 들어, 일부 ZK dex는 Cex와 Dex 사이에서 균형점을 찾으려는 경향이 있으며, Cex에 비해 사용자는 자신의 L1 계좌에 자금을 보관할 수 있습니다. 반면, Dex에 비해 더 나은 효율성을 보여줄 수 있습니다. 그러나 실제로 많은 프로젝트는 체인 외 증명의 안전성 문제를 안고 있습니다. 또한 APP 계층에서 IR 계층까지 모두 zkAPP 팀이 독립적으로 개발하므로, 각 팀마다 고유한 프로그래밍 습관과 라이브러리가 있어 팀 간의 조합성이 낮아지고, 시장 분업과 하드웨어 장비의 가속화에 불리합니다.
따라서 시장은 암호학과 고급 언어 사이에서 공약수를 찾으려 하고 있습니다. 이를 통해 다양한 응용 프로그램에 보편적인 프레임워크를 제공하며, ZK-VM은 전체 시스템을 조정하고 연결하는 중요한 부분입니다.
실행 모드 측면에서 EVM과 JVM은 매우 유사합니다. 두 시스템 모두 바이트코드를 실행하는 스택 머신입니다. EVM은 저장 개념을 추가했으며, 그 바이트코드 명령은 계약 개발에 더 적합합니다.
그림에서 ETH를 예로 들면, 전통적인 ETH는 세 부분으로 구성됩니다: ETH 네트워크(노드 + 합의 메커니즘), EVM, Dapp 개발 생태계. 여기서 우리는 ZK가 연결하는 역할을 매우 명확하게 느낄 수 있습니다:
- ZK 회로 하드웨어 계층의 관점에서:
EVM은 모든 것을 완전히 호환할 수 없을 수 있습니다. EVM에는 CALL, DATACOPY, EXP, CREATE 등과 같은 가변 길이 명령이 있어 ZK 회로에 불리합니다.
- 개발자 관점에서:
언어를 새로 배우지 않고(Solidity는 여전히 호환됨) EVM의 API 특성을 유지할 수 있는가? 이러한 경우, 전체 생태계는 일부 ZK 알고리즘에 대한 지원을 잃을 수 있습니다.
그 외에도 ZKVM은 많은 기술 호환성을 고려해야 합니다. 예를 들어:
레지스터 호환성. 머신 타입. 전통적인 EVM은 스택 기반 상태 머신이므로 많은 계산이 직렬로 연결되고 병렬 처리가 불가능합니다. 이는 전체 컴퓨터의 원자성을 보장합니다. 이 구조는 ZK에 매우 불리하며, ZK 알고리즘의 모든 효율성을 발휘하려면 레지스터 기반으로 설계해야 하며, 즉 CPU 레지스터를 중심으로 한 아키텍처를 설계해야 합니다.
언어 호환성. 함수 호출. VM 시스템은 저수준 특성을 API로 캡슐화하며, API가 동적 호출을 지원하고 Python과 같은 고급 언어를 지원하도록 하는 방법입니다.
컴퓨터 저수준 호환성. 네이티브 필드. 서로 다른 CPU는 서로 다른 비트 수를 가지며, 서로 다른 알고리즘에서의 성능이 다릅니다. ZK 전용 컴퓨터를 위해 계획해야 합니다.
전통적인 공공 체인 구조의 호환성: 시퀀서/롤러/채굴자.
3. ZKVM의 구조
주류 기술 솔루션
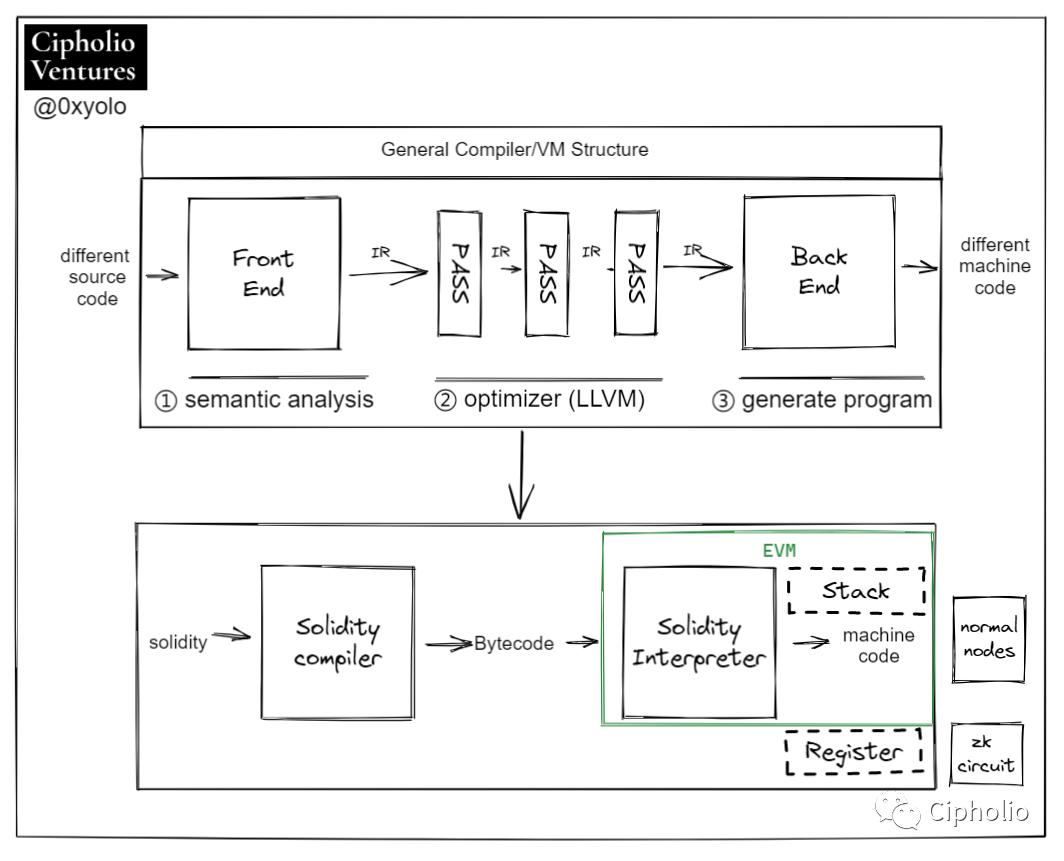
어떤 언어로, 어떤 환경에서, 어떤 하드웨어를 실행하는가? 이것이 광의의 VM이 해결해야 할 문제입니다.
VM에서 가장 중요한 커널은 LLVM(저수준 가상 머신)입니다. 이는 컴파일러의 가장 중요한 커널로 볼 수 있습니다. 그림은 원래 EVM의 작동 방식을 보여주며, 스마트 계약은 LLVM IR의 중간 코드로 변환되어 바이트코드로 변환됩니다. 이러한 바이트코드는 블록체인에 저장되며, 스마트 계약이 호출될 때 바이트코드는 해당 Opcode로 변환되고, EVM과 노드 하드웨어가 이를 실행합니다.
ZK와 결합하여 각기 다른 솔루션은 어떻게 구현되고 있을까요?
Starkware
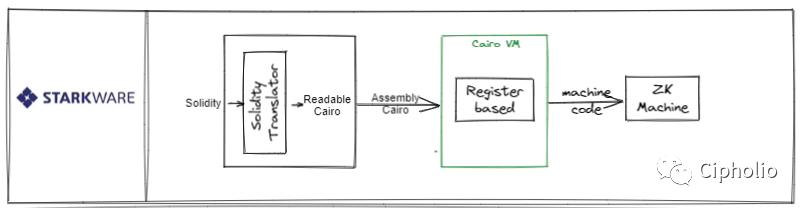
Starkware는 ZK 분야에서 일찍 시작하여 기술 축적이 충분하고 일정한 기술적 우위를 가지고 있습니다. 이는 ZK 중심주의 기술 아키텍처의 대표적인 예로, ZK를 중심으로 Cairo VM과 Cairo 언어를 구축했습니다. 그러나 폐쇄 소스 상태이기 때문에 일부 기술 세부 사항이 명확하지 않습니다. 단점은 Cairo의 학습 비용입니다. 공식적으로 Solidity를 Cairo로 변환하는 일부 프레임워크도 개발했지만, 그 저수준 핵심이 모두 CairoVM에 기반하고 있어 상당수의 Solidity-EVM 호환 특성이 손실됩니다.
Zksync
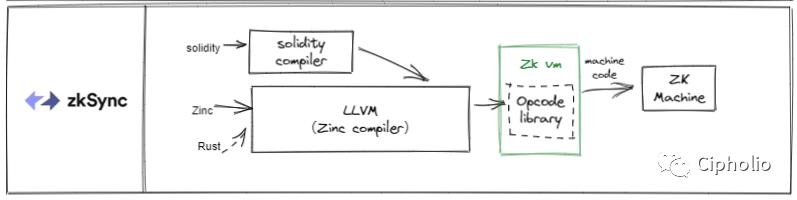
ZKsync의 프레임워크는 EVM과 ZK 두 가지 측면의 특징을 호환하여 Solidity와 자사 개발의 회로 언어 Zinc를 통합하였습니다. 컴파일러 내부에서 두 언어를 IR 수준에서 통합하였습니다. 장점은 컴파일러 커널인 LLVM이 여러 언어를 호환할 수 있다는 점입니다. Zksync도 폐쇄 소스 프레임워크입니다.
Hermez by Polygon
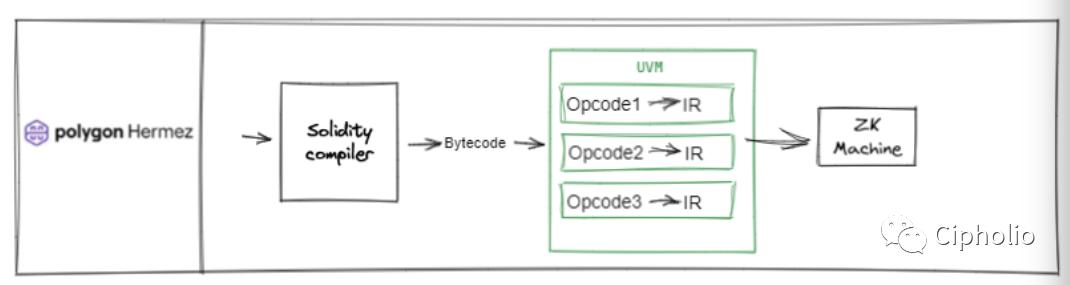
Scroll
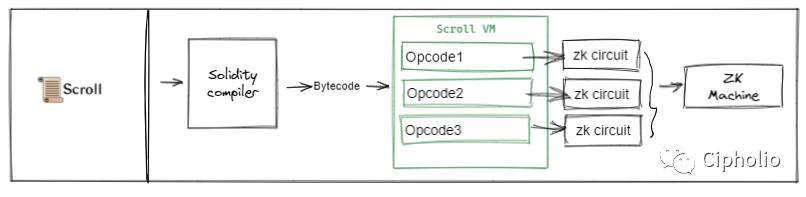
HermZ와 Scroll 두 기술 솔루션은 이더리움 생태계에 더 중점을 두고 있으며, 바이트코드에서 ETH 생태계와 통합되었습니다. EVM은 본질적으로 바이트코드와 해당 opcode를 지원하므로 이 두 가지는 ETH 생태계와 더 높은 통합성을 가지고 있습니다. Solidity는 이 두 Zkvm에서 EVM의 API를 충분히 호출할 수 있으며, EVM의 아키텍처 장점을 최대한 유지합니다. 두 솔루션의 차이는 Hermz가 내부에서 opcode를 통합한 후 증명하는 반면, Scroll은 Opcode를 회로로 분해하여 증명한 후 통합합니다.
왜 EVM과의 호환성을 선택해야 할까요? EVM에는 검증된 아키텍처가 있으며, 안전성과 호환성이 좋기 때문입니다. 예를 들어 Geth 모델과 RPC 아키텍처는 이러한 API가 EVM에 잘 캡슐화되어 있으며, 역사적으로 검증되었습니다.
종합적으로 보면,
- Starkware는 가장 저수준에서 WASM과 머신 코드 수준에서 통합하고, ZKsync는 IR 수준에서 가장 얕게 통합하며, Hermz와 Scroll은 바이트코드에서 중간 수준으로 통합합니다;
- Starkware는 기술 전환이 가장 철저하지만, 사용자 학습 장벽이 가장 높습니다; Zksync는 상대적으로 균형 잡혀 있으며, 일부 Solidity 특성을 유지하고 부분적으로 ZK 성능을 발휘합니다;
- Hermz와 Scroll은 상대적으로 가장 쉽게 적용되고 분해되며, 바이트코드를 완전히 통합하고 EVM을 통합합니다. 특히 Scroll은 ZK 증명을 개방하고 하드웨어 가속의 더 큰 공간을 제공합니다.
- 상대적으로 기술 주도든 생태계 통합 주도든 모두 미래에 각자의 발전 공간이 있으며, "무역공업기술"이든 "기술공업무역"이든 각자의 장면을 찾아 더 큰 가치를 발휘할 기회가 있습니다.
Windows 역사를 되돌아보면, 강력한 운영 체제가 등장하기 전에는 서로 다른 개발자들이 서로 다른 하드웨어에 대해 서로 다른 개발 도구를 마스터해야 했습니다. 어셈블리를 마스터하지 못하고 컴퓨터 저수준을 이해하지 못하는 개발자는 개발 과정에서 많은 좌절을 겪게 됩니다. 운영 체제는 하드웨어에서 최대 공약수를 찾아 CPU 외의 I/O 시스템을 통합된 인터페이스로 캡슐화합니다. 이러한 기술 축적은 소프트웨어 개발의 장벽을 크게 낮추었고, 대부분의 프로그래머는 고급 언어만 이해하면 되며, 어셈블리 및 저수준 코드 지식이 없어도 멋진 앱을 작성할 수 있게 되었습니다.
ZKVM 발전을 되돌아보면, 현재 ZKapp이 전통적인 프로그래머 + 어셈블리 + 암호학 지식이 필요하다면, 미래 ZKVM의 성숙에 따라 점점 더 많은 저수준 기술이 고급 언어에 통합되어 개발 장벽이 점차 낮아지고 생태계의 번영이 예상됩니다.
창립자에게는 두 가지 주의 사항이 있습니다:
ZK 기술은 체인 상의 합의를 체인 외 증명으로 전환하며, 현재 증명 기술은 상대적으로 성숙하지만, 증명 분해 및 데이터 저장의 안전성 문제는 여전히 많습니다. 관련 감사 기관과 테스트 도구는 공백 상태입니다.
ZK 기술의 사용 사례는 아직 발굴되지 않았습니다. 범용 ZKVM이 바쁘게 개발되고 있으며, ZK에 대응하는 고급 언어도 기술자들의 학습이 필요합니다. 기술이 성숙하여 문제를 해결하기까지는 시간이 필요합니다. ZK로 문제를 해결하고자 하는 창립자는 세분화된 장면이 있다면, 스스로 WASM을 구축해야 하는지, ZKVM이 성숙하면 자신의 기술 축적이 여전히 선발 우위를 가질 수 있는지, 다른 ZKapp 호출을 지원하는지에 대한 질문에 답해야 합니다.
전망 및 결론
ZK 기술은 프라이버시와 확장성 두 가지 주요 사용 사례를 가지고 있습니다. 프라이버시를 논할 때, 우리는 실제로 체인 외 데이터를 보호하여 외부에서 접근할 수 없도록 합니다. 반면, 확장성을 논할 때는 ZK를 이용해 체인 상의 계산 공간을 절약합니다.
- ZKVM 발전의 핵심은 기술과 개발자 간의 균형입니다. ZK 잠재력을 발휘하는 것은 CPU 레지스터의 하드웨어 가속, IR 언어와 어셈블리 언어의 재구성을 의미합니다. 반면, 개발자 자원을 활용하는 것은 Solidity를 바이트코드로 변환한 후, 바이트코드가 매핑된 opcode를 ZK 증명하는 문제를 의미합니다.
- 어셈블리 언어로 독립적으로 설계된 ZK 증명의 전용 ZKapp는 낮은 조합성과 분리 능력으로 인해 미래 발전 과정에서 큰 장애물에 직면할 것입니다. 이러한 솔루션은 다른 ZK 솔루션과 호환되지 않는 VM, 언어, 증명과의 불일치로 인해 호출의 어려움이 큽니다.
- 모듈화 블록체인 관점에 따르면, L1은 합의 문제를 해결하고, L2는 계산 및 실행 문제를 해결하며, DA 계층은 데이터 접근성과 무결성 문제를 해결합니다. ZK 유형의 데이터 보안성과 증명의 무결성은 실행의 신뢰성을 결정합니다. 여기에는 모순이 있습니다. 체인 외 노드를 신뢰하지 않고 데이터를 DA에 독립적으로 저장하고자 한다면 DA 체인에 대한 안전 요구가 필요합니다. 반면, 로컬에서 데이터를 변조하지 않도록 보장하려면 증명 노드가 악의적 행동을 하지 않아야 합니다. 이러한 요구는 MPC/FHE 솔루션에 대한 수요를 증가시킵니다.
- 현재 ZK 솔루션의 대부분이 폐쇄 소스 상태에서, 많은 합의는 여전히 체인 외 노드의 자율성에 기반하고 있으며, 체인 외 환경의 안전성을 보장하기 위한 일련의 필수 도구(테스트, 증명 등)가 부족합니다. 미래의 제약 설계와 대수적 증명은 두 가지 주요 감사 단계가 될 것입니다.
- ZK 생태계의 주요 위험. 전형적인 문제에는 제약 시스템이 불충분한 경우가 포함됩니다. 복잡한 교차 명제를 증명할 때 제약이 충분하지 않은 문제; 개인 데이터 유출, 개인 데이터를 공개 데이터로 처리; 체인 외 데이터에 대한 공격, 계약 계층의 "메타데이터 공격"; ZK 증명 노드의 악의적 행동 등이 있습니다.
- 다양한 회로의 지속적인 성숙에 따라 시퀀서/롤러/채굴자도 효율성과 분업을 맞이할 것이며, 우리는 ZK 증명의 하드웨어 가속 기회를 기대합니다.
 위험 경고
위험 경고 위험 경고
위험 경고











