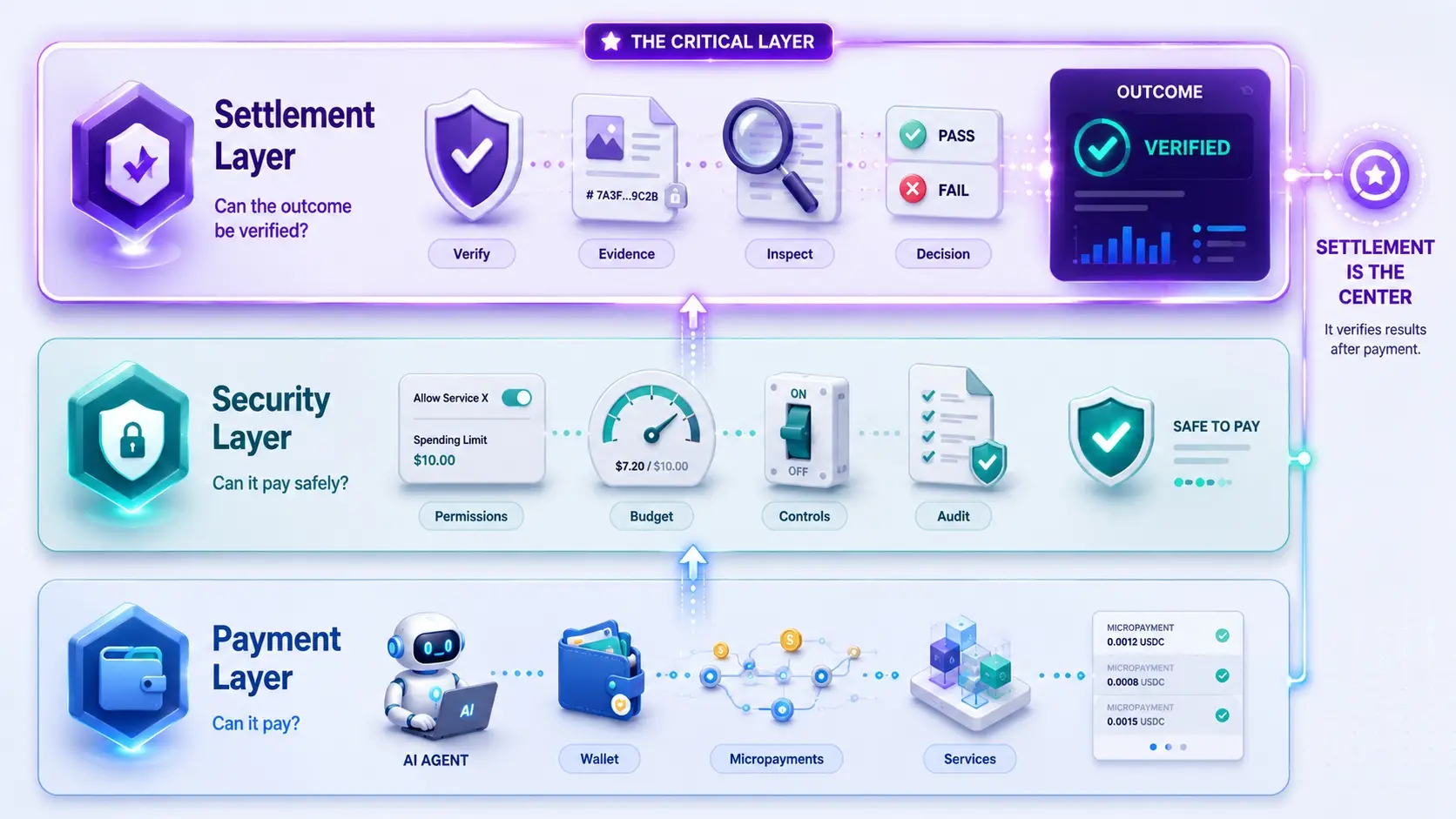
Talkie:剝離現代知識,重新審視 AI 的基礎能力

 副標題:一個只讀 1931 年前文本的模型,正在重新區分 AI 的知識記憶與基礎能力。
副標題:一個只讀 1931 年前文本的模型,正在重新區分 AI 的知識記憶與基礎能力。最近,一個名為 Talkie 的復古語言模型在 AI 圈引發了討論。它的核心特徵在於訓練數據的極度受限。這個擁有 13B 參數、基於 2600 億 token 訓練的模型,閱讀的主要是 1931 年之前的英文文本,包括舊書、報紙、期刊、科學論文、專利和百科全書。官方將其定義為 Vintage Language Model。

在追求更大上下文、更廣知識覆蓋和即時更新的時代,Talkie 的設定顯得反常。
現代大模型通常在現代互聯網語料中訓練。它們熟悉 Python 代碼,熟悉 GitHub issue,熟悉今天的社交媒體語境。而 Talkie 像是一個被關在 1930 年知識邊界裡的研究對象。它沒有見過二戰後的世界,也沒有真正接觸互聯網、加密貨幣或現代軟體工程。這種對現代知識的剝離,讓它成為一個觀察模型基礎能力的實驗樣本。
知識與基礎能力的拆解
通過 Talkie,研究者可以觀察到一個本質問題:如果一個模型沒見過現代世界,它還能從語言結構和上下文示例中學到多少能力?
在現代模型的評估中,邏輯推理往往與資料記憶混在一起。當一個模型答對 Python 代碼或現代政治題時,我們很難分清它是真的具備基礎能力,還是僅僅因為訓練數據裡剛好包含了相關的測試題。Talkie 將這兩者區分開了:
- 時代錯位(Anachronism): 如果它不知道"聯合國什麼時候成立",這並不代表其語言理解能力差,因為 1930 年之前並沒有聯合國的概念。這屬於知識缺失,而非能力缺失。
- 模式泛化: 研究者發現,儘管 Talkie 完全沒見過 Python,但通過幾個 few-shot 示例,它能通過語言結構推導出極簡單的代碼邏輯。這證明了 Transformer 架構本身具備基礎的泛化能力,而不僅是靠記憶。

"雙胞胎"對照實驗
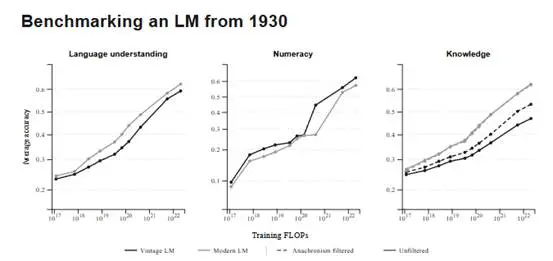
為了驗證數據分佈的影響,研究團隊造了一個架構完全相同的 Modern Twin ,區別僅在於後者讀的是現代網頁數據 FineWeb。
起初,Talkie 在標準測試中全面落後,但這對於一個缺乏 1930 年後知識的模型來說並不公平。有趣的是,當研究者過濾掉那些從 1930 年視角看屬於"未來"的問題後,Talkie 與現代模型之間的表現差距縮小了大約一半。
這表明,語言理解的基礎能力並不完全依賴現代互聯網。高質量的舊報紙、科學期刊和法律文書中,已經蘊含了人類積累的常識模式、邏輯因果和論證規則。模型從這些文本中學到的,是概念如何連接、證據如何支持判斷,這些底層邏輯在不同行業具有高度的穩定性。
對設計原則的啟發
對於關注可追溯性、驗證和推理路徑的 AI 系統,Talkie 指出了一個有用的設計原則:模型本體沒有必要把每一個新事實都壓進參數裡。
更穩健的路徑應該是:基礎模型專注於穩定的語言能力、推理結構和通用模式。這些能力可以從高質量、高密度的歷史文本中習得。而最新的事實、技術規範和即時信息,則交給檢索系統、知識庫和工具調用。
讓模型負責理解與拆解,讓外部系統負責更新與執行。這比單純追求更大的預訓練語料、讓模型成為一個依賴記憶的"背題家"要更接近生產環境的實際需求。
結語
Talkie 的價值在於它劃定了一個清晰的實驗邊界。它提醒行業:不要將"新資料"直接等同於"新能力",也不要將"知識覆蓋面"直接等同於"基礎能力"。
AI 的進化邏輯正在發生位移:比起無止境地堆砌網頁數據,那些能在精選語料中沉澱出邏輯框架,並擅長調用外部知識庫去解決實戰問題的系統,更貼近下一階段的競爭核心。
 風險提示
風險提示