

















The underlying internet will not be entirely built on blockchain, so where should Web3.0 applications run?

 In the era of Web 3.0, the blockchain infrastructure cannot rely solely on innovations in consensus mechanisms and cross-chain solutions; off-chain computing has now become a major trend in problem-solving.
In the era of Web 3.0, the blockchain infrastructure cannot rely solely on innovations in consensus mechanisms and cross-chain solutions; off-chain computing has now become a major trend in problem-solving.Original Title: "Where Should Web3.0 Programs Run?"
Authors: Song Jiajie, Ren Heyi
Abstract
In the Web3.0 era, the underlying internet will not be entirely built on blockchain, and data computation will not all run on the "single-log bridge" of public chains. Considering the efficiency of data computation and the different underlying programming language environments, the foundational layer of data computation in the Web3.0 era will be a complex and diverse environment. Therefore, how to solve the efficiency of data computation in the blockchain era becomes a key direction for the next generation of computing paradigms.
The blockchain infrastructure in the Web3.0 era relies not only on innovations in consensus mechanisms and cross-chain solutions but also increasingly on off-chain computation, which has become a major trend in solving problems. Due to the constraints of the impossible triangle, exploring off-chain computation using semi-centralized methods can achieve higher scalability. The key to this solution is how to achieve consistent consensus on off-chain computation results on-chain.
Technologies such as TEE and zero-knowledge proofs can be used to achieve consensus and security for off-chain data computation results returning to the main chain. This report analyzes off-chain computation models using cases like Oasis, Arweave, and Mina, exploring possible paradigms for data computation in the Web3.0 era and how to achieve collaborative data computation between on-chain and off-chain, as well as between different chains.
Regarding performance upgrades, the evolution of public chains has roughly gone through the following stages:
1) Exploration of consensus mechanisms. The consensus mechanism has evolved from POW to POS and then to various improved versions of POS, all aimed at solving the scalability issues of public chains, yet still constrained by the impossible triangle;
2) Cross-chain attempts to carry applications across multiple chains. Cross-chain solutions consider that a single public chain cannot be suitable for all scenarios, necessitating multiple public chains to solve data carrying and computation operations. Cross-chain still needs to balance the constraints of the impossible triangle in the industry;
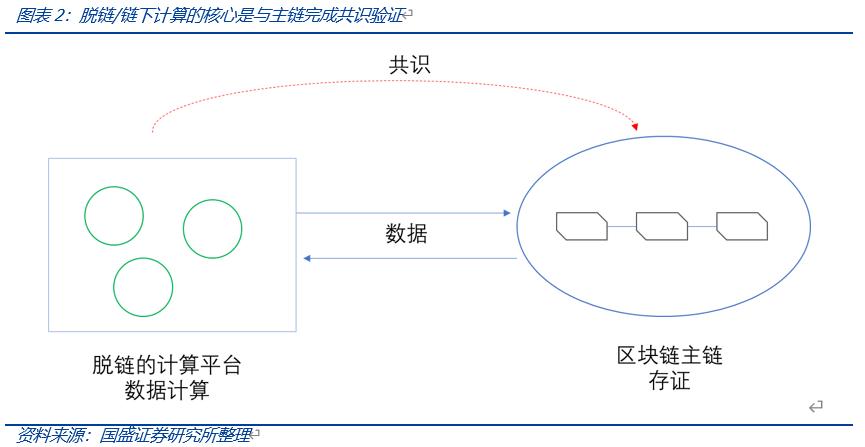
3) Off-chain computation is becoming a trend to relieve the burden on the main chain. From Ethereum 2.0's sharding to L2 networks, all efforts revolve around how to relieve the main chain's burden. The overall idea is off-chain computation, separating computation (resource consumption such as storage) from proof. The core issue of off-chain computation is the verification of data between on-chain and off-chain, or how to achieve consensus on off-chain data computation results on-chain, so that this method can be trusted by decentralized users.
This chapter introduces three typical off-chain computation project cases: the SCP model of Oasis, Arweave, and the Snapp of the MINA ecosystem. From these various implementation methods, we can glimpse the complex reality of data computation solutions in the Web3.0 world. The future Web3.0 world may not be an ideal public chain single-log bridge, but a flourishing and complex ecosystem.
In the Web2.5 era, how to share data between two ecosystems, how programs run across two ecosystems, and how the two ecosystems merge will be a pressing need of the times. Sharing data between the centralized and decentralized worlds will give rise to a huge demand for oracle-type applications.
Data and applications from the Web2.0 era will continue to exist on the road to the Web3.0 era and will continuously merge with Web3.0—data will be shared between the so-called new Web3.0 application ecosystem and the existing Web2.0 ecosystem, and applications will run across Web3.0 and Web2.0 systems (the Web2.5 era), with users belonging to both ecological worlds simultaneously.
Additionally, the vast data assets and computing methods of the Web2.0 era will continue to exist for a long time, inevitably forming a part of the Web3.0 era. How this part of data and computation integrates with the blockchain-dominated new ecosystem, and how to coordinate the invocation of internet infrastructure resources such as data storage, networking, and computing memory, are all significant challenges. These issues cannot be solved solely by cross-chain or oracle solutions.
Risk Warning: The blockchain business model may not materialize as expected; regulatory policy uncertainties.
1. Core Viewpoints
In the Web3.0 era, the underlying internet will not be entirely built on blockchain, and data computation will not all run on the "single-log bridge" of public chains. Considering the efficiency of data computation and the different underlying programming language environments, the foundational layer of data computation in the Web3.0 era will be a complex and diverse environment. Therefore, how to solve the efficiency of data computation in the blockchain era becomes a key direction for the next generation of computing paradigms.
For decentralized systems, relying solely on innovations in consensus mechanisms and cross-chain solutions is far from sufficient; off-chain computation has become a major trend in solving problems. Due to the constraints of the impossible triangle, exploring off-chain computation using semi-centralized methods can achieve higher scalability. The key to this solution is how to achieve consistent consensus on off-chain computation results on-chain.
Technologies such as TEE and zero-knowledge proofs can be used to achieve consensus and security for off-chain data computation results returning to the main chain. This report analyzes off-chain computation models using cases like Oasis, Arweave, and Mina, exploring possible paradigms for data computation in the Web3.0 era and how to achieve collaborative data computation between on-chain and off-chain, as well as between different chains.
2. Consensus in Web3.0: There is Much to Do Beyond the Public Chain's Single-Log Bridge
The limitations of basic performance in public chains represented by Ethereum mean that innovations in consensus mechanisms alone are insufficient, and cross-chain connections between multiple chains are also inadequate to carry the data and computation of Web3.0. Thus, various scaling solutions such as Ethereum 2.0's sharding, L2, and Polkadot's parachains have become practical solutions.
These solutions differ in detail, but they ultimately convey a market consensus: that Web3.0 data and computation will not all run on the public chain's single-log bridge, and a significant amount of data and computation processing will occur off-chain (which could be L2, parachains, or even other non-blockchain methods). In other words, off-chain computation has become an industry consensus, especially for large-scale data processing and computation, which will be completed outside the main chain.
This article temporarily refers to various methods outside the main public chain as off-chain computation. How to establish effective data and computation platforms outside the public chain to support various Web3.0 applications will become an important issue for the future.
2.1. The Path to Web3.0: Exploring Consensus Mechanisms, Cross-Chain Solutions, and Modular Public Chains
The basic performance of public chains is an ultimate issue that the industry cannot avoid. Regarding performance upgrades, the evolution of public chains has roughly gone through the following stages:
1) Exploration of consensus mechanisms. The consensus mechanism has evolved from POW to POS and then to various improved versions of POS, all aimed at solving the scalability issues of public chains. However, regardless of the consensus mechanism, achieving consistent consensus inevitably sacrifices the system's operational performance, which is an unbreakable impossible triangle;
2) Cross-chain attempts to carry applications across multiple chains. Cross-chain solutions consider that a single public chain cannot be suitable for all scenarios, necessitating multiple public chains to solve data carrying and computation operations. For example, Polkadot, as a scalable heterogeneous multi-chain system, can transfer any data (not limited to tokens) to all blockchains, achieving mutual circulation of assets and data between different chains.
This is crucial for the scalability and application diversity of blockchain networks, as the performance of a single blockchain is ultimately limited, and it is challenging to balance between specialized and general-purpose chains. At the same time, the impossible triangle that constrains the industry (i.e., scalability, security, and decentralization cannot be achieved simultaneously) must also be balanced accordingly.
3) Off-chain computation is becoming a trend to relieve the burden on the main chain. From Ethereum 2.0's sharding to L2 networks, all efforts revolve around how to relieve the main chain's burden.
In other words, heavy data computation is delegated to off-chain—potentially through sharding or L2, or even non-blockchain systems to carry out data computation, with the final results returned to the main chain for proof. The consensus on the main chain provides verification of data results, ensuring sufficient decentralization and security, while heavy data computation is handled by platforms outside the main chain.
Although these high-performance platforms sacrifice some decentralization or security during operation, they can achieve supervision and verification of off-chain platforms by the main chain through technologies like zero-knowledge proofs and TEE. The overall idea is off-chain computation, separating computation (resource consumption such as storage) from proof.
Recently, the industry has introduced a new concept: modular public chains. Similar to the layered internet protocol, future public chains will separate execution layers, settlement layers, and data availability layers. On Ethereum, the execution layer is the L2 running various Dapps, which then returns the packaged transaction data (Rollup) to the Ethereum main chain for verification and on-chain storage.
Currently, data is also stored on Ethereum (of course, after Rollup packaging), but with the ever-expanding raw data, there are considerations to establish a data availability layer to store data, further relieving the Ethereum main chain, allowing it to focus solely on verification and computation (consensus)—after all, the massive on-chain and off-chain data verification issues will further limit Ethereum's performance.
Of course, this ideal layered approach has yet to be validated, and even Vitalik has raised concerns about the security of the data availability layer. The core issue of off-chain computation is the verification of data between on-chain and off-chain, or how to achieve consensus on off-chain data computation results on-chain, so that this method can be trusted by decentralized users.

For sharding, L2, and off-chain computation, public chains are like strictly managed main roads for goods transportation (consensus), where not all data can run on the main road, but rather on branch roads.
By proving their rigorous and trustworthy work through zero-knowledge proofs and other means, complex goods on rural, fine roads can be packaged and transported on the main road. How to prove the trustworthiness of data results to the main chain relies on flexible technologies like zero-knowledge proofs and TEE to adapt to different operational scenarios.
Additionally, the vast data assets and computing methods of the Web2.0 era will continue to exist for a long time, inevitably forming a part of the Web3.0 era. How this part of data and computation integrates with the blockchain-dominated new ecosystem, and how to coordinate the invocation of internet infrastructure resources such as data storage, networking, and computing memory, are all significant challenges. These issues cannot be solved solely by cross-chain or oracle solutions.
3. Data Computation in Web3.0: Three Models of Off-Chain Computation
Although data computation has detached from the main chain, technologies like sharding and L2 still consider basic data computation relying on blockchain, balancing decentralization concerns. Due to the constraints of the impossible triangle, exploring off-chain computation using semi-centralized methods can achieve higher scalability. The key to this solution is how to achieve consistent consensus on off-chain computation results on-chain, using technologies like TEE and zero-knowledge proofs to achieve consensus and security for off-chain data computation results returning to the main chain.
The core issue of off-chain computation is how to achieve consensus for data computation detached from the main chain. In other words, how can users trust the computation outside the main chain?
This chapter introduces three typical cases. From these various implementation methods, we can glimpse the complex reality of data computation solutions in the Web3.0 world. The future Web3.0 world may not be an ideal public chain single-log bridge, but a flourishing and complex ecosystem.
3.1. Oasis: Modular Layered Design Separating Consensus Layer and Execution Layer (ParaTime)
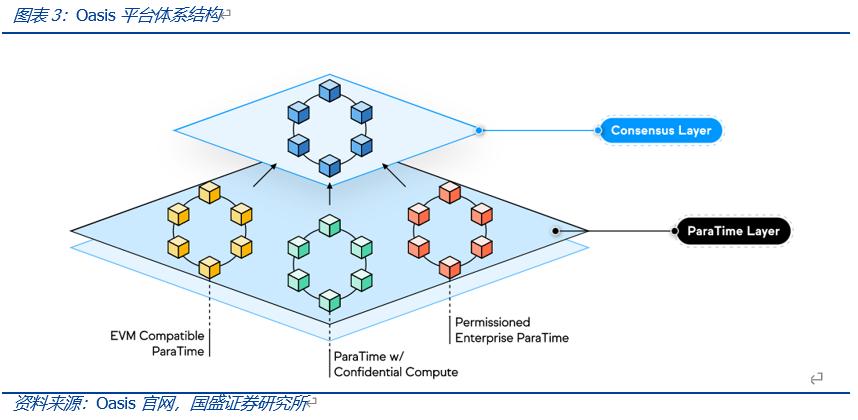
Oasis Network is a decentralized Layer 1 blockchain network utilizing Proof of Stake (POS), with a modular architecture that decouples the consensus layer and the smart contract execution layer (ParaTime), meaning data computation (contract execution) is detached from the L1 main chain (i.e., the consensus layer) and executed in the ParaTime layer, fully considering privacy computation.
In its design, the consensus layer is simplified as much as possible, handling only simple operations like token transfers, staking, and unbinding. This design is similar to Ethereum's Layer 2 projects that isolate smart contract execution from consensus operations, both of which help improve network security and efficiency.
In the design of the ParaTime layer, Oasis separates various ParaTime modules, allowing different ParaTime modules to optimize and adjust according to different needs, independently completing their operations.
During operation, different ParaTime build their own execution environments, verification mechanisms, and encryption mechanisms. After smart contracts are executed in the ParaTime layer, their result values are submitted to the consensus layer. The consensus layer accepts various parameter values from the ParaTime layer and writes these values into the next block while handling more basic operations.
If a particular ParaTime experiences overload or errors during operation, it will only affect the state updates submitted to the consensus layer from the erroneous ParaTime and will not impact the operation of other ParaTime. To prevent a single ParaTime layer from maliciously sending excessive junk information to the consensus layer, which could slow down its operation, each ParaTime layer must pay transaction fees to the consensus layer, thereby increasing the cost of load attacks.
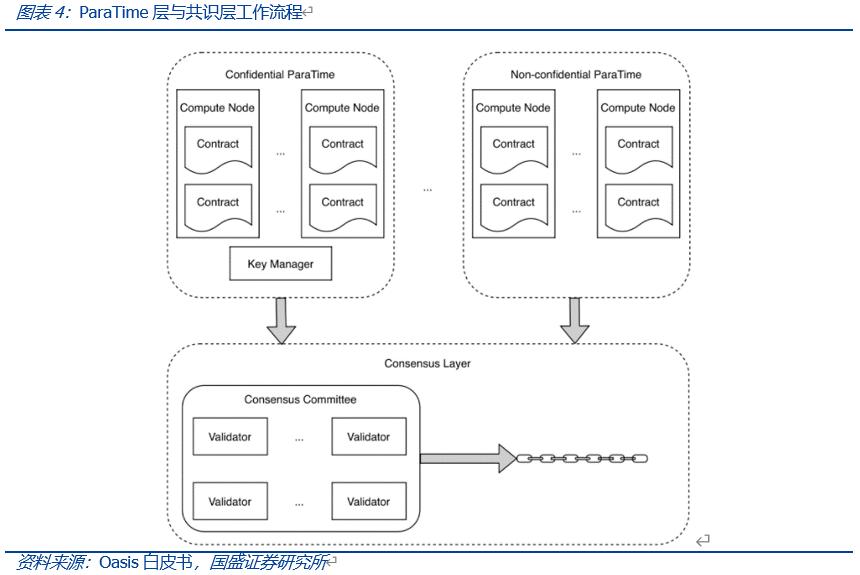
So how does the ParaTime layer interface with the L1 main chain and achieve consensus? In terms of verifying execution results, Oasis uses differential detection to validate the execution results of ParaTime. During differential detection, a random selection of computing nodes from the nodes forms a computing committee, and when all committee members agree on the results, the results are accepted.
If a discrepancy is detected, the differential resolution protocol is used to handle it. Differential detection is cheaper and faster to execute, while differential resolution often incurs higher costs. In the specific execution process, computing nodes first send the execution results to the differential detector via a Gossip protocol network. If the detection results are normal, they are submitted to the consensus layer for processing and block production by the verifier.
If there is a dispute, the differential resolution protocol will be initiated to determine the correct result, and nodes that generated the disputed results will be penalized, with the disputing nodes bearing the cost of differential resolution.
Different ParaTime can submit each result to the consensus layer in parallel or periodically submit a merged value of multiple results, thus decoupling the output of ParaTime results from the number of blocks produced by the consensus layer.
However, its drawback is that it cannot determine the relative order between different ParaTime. For example, if the results TA produced by ParaTime A and TB produced by ParaTime B are submitted to the same block simultaneously, it cannot determine the order of occurrence of TA and TB.
In addition, Oasis supports communication between different ParaTime through the IBC protocol (Inter-Blockchain Communication Protocol) and provides higher privacy and security for the platform through TEE (Trusted Execution Environment).
Privacy computation is a highlight of Oasis. The Oasis network supports smart contracts based on privacy computation, fully reflecting the characteristics of privacy computation. In encrypted ParaTime, nodes need to use TEE secure computing technology, which acts as a secure island for smart contract execution.
Data is completely encrypted for node operators or application developers. The computation layer runs smart contracts in a TEE environment, allowing the Oasis network to balance performance and privacy while supporting computation-intensive application scenarios, such as the recently popular machine learning and deep learning.
In summary, Oasis achieves the decoupling of node functions by separating the consensus layer from the computation layer, significantly reducing the operational pressure on various nodes in the network and improving the platform's operational speed. At the same time, TEE provides privacy and security solutions for data computation, offering rich imaginative space in the Web3.0 era.
3.2. Arweave: A Computation Paradigm Based on Storage Consensus
Arweave (AR) provides data storage services through a decentralized operation model and a Proof of Access (POA) consensus mechanism, rewarding miners who provide storage services with AR tokens. The foundation of POA is Arweave's unique Blockweaves structure, where each block is not only connected to the previous block but also to a recall block, with the generation of the recall block depending on the hash value of the previous block and the block height.
When determining the block-producing miner, miners must prove their ability to access the data in the recall block to gain block production rights and rewards. This requires miners to 1) replicate as many blocks as possible; 2) preserve blocks that are difficult to replicate; and 3) preserve blocks with fewer storage users to gain more advantages when mining new blocks.
Additionally, due to the inherent verifiable and traceable characteristics of blockchain data, the credibility of on-chain data can be greatly ensured, enabling trustworthy permanent storage.
Arweave adopts a "one-time payment, permanent storage" model. In the long run, the storage cost of AR is very low, even close to zero. Moreover, AR's storage efficiency is relatively fast, so AR is often likened to the tape of a Turing machine, storing user data at a low cost, just like a tape.
Therefore, utilizing AR's efficient and low-cost storage allows data computation to be conducted off-chain, with data sources coming from the AR chain, and computation results also being stored on-chain. The SCP (Storage-based Consensus Paradigm) realizes computation based on AR, with AR serving as the data source's Turing tape, providing data sources for off-chain applications, and computation results being uploaded to AR for proof. Its efficiency depends on the performance of off-chain applications and computers, naturally surpassing on-chain computation based on consensus mechanisms.
In traditional Layer 1 systems like Ethereum, functions such as computation, storage, and consensus are all handled by nodes, completing on-chain proof through consensus mechanisms like POW, which are constrained by the impossible triangle, limiting their efficiency.
SCP separates on-chain proof from computation functions. In simple terms, the public chain itself acts more like a computer hard drive, responsible only for data storage. While ensuring the credibility of on-chain stored data, the execution of smart contracts can occur on any device with computing capabilities off-chain.
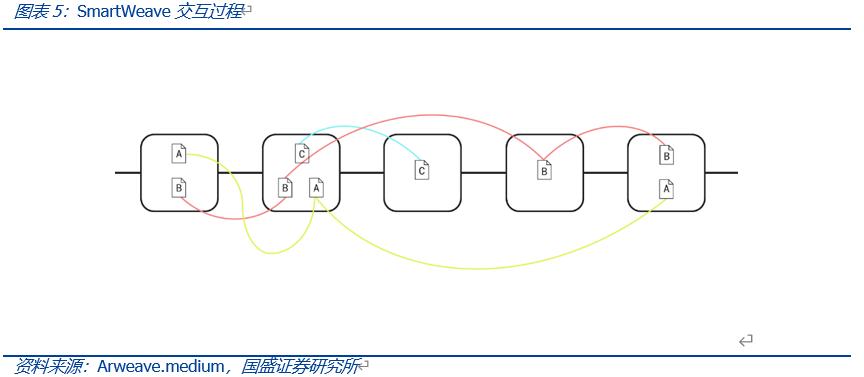
The concept of SCP originates from SmartWeave, a smart contract platform built on Arweave that shifts the burden of executing smart contracts to users through a lazy evaluation process. Unlike Ethereum, where each node must execute every transaction (which affects computational efficiency), SmartWeave employs a "lazy evaluation" system, delegating the computation of transaction verification to users.
When users interact with SmartWeave contracts, they evaluate each previous transaction on the dApp, confirming consistency with the latest state of on-chain stored data, and then write the transaction results to the Arweave network for proof, repeating this process. During operation, SmartWeave can be viewed as a virtual machine running off-chain.
It achieves separation of on-chain storage and off-chain computation by reading the application's code and input parameters on Arweave, executing transactions locally, and then synchronizing the output results with Arweave. The user's verification work resembles the chain structure of blocks, tracing and verifying transactions step by step, and all of this does not need to be completed on-chain, but rather by users off-chain, meaning this process can be free from the constraints of consensus mechanisms.
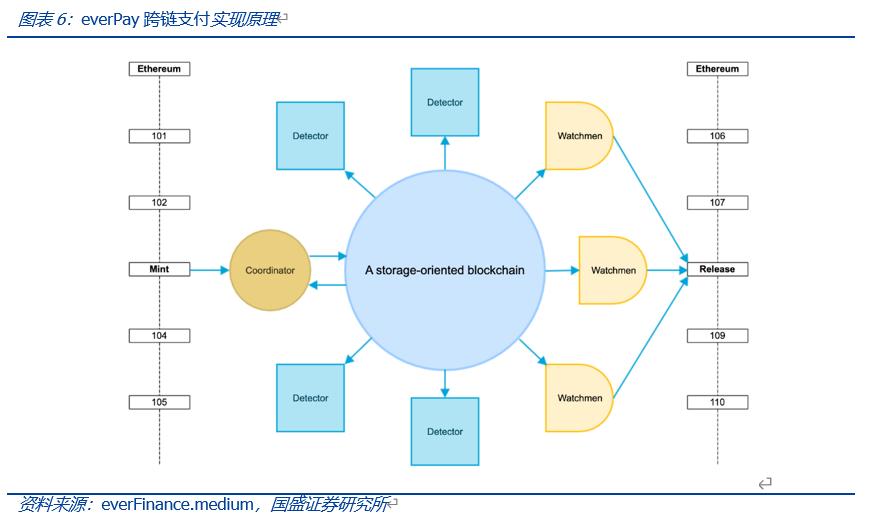
Another development example of SCP is everPay on Arweave. EverPay is a cross-chain token payment protocol that provides real-time token payment services between users and merchants. EverPay locks various assets from other public chains in a smart contract and maps them to corresponding assets.
For instance, when a user transfers assets from Ethereum to Arweave, the Coordinator first collects and verifies the transactions, placing each transaction into a serialized pending transaction pool. The pending transactions are then packaged in batches and uploaded to Arweave at intervals. Subsequently, the Detector verifies the global state on-chain and account balances, and any user can apply to become a Detector node.
Unprocessed transactions on Arweave are completed by Watchmen using multi-signatures or threshold signatures, returning the results to Ethereum. Therefore, contract execution occurs off-chain, with data stored on-chain, achieving separation of storage and computation.
In summary, the storage-based consensus paradigm establishes the prototype of Offchain-Dapp. On-chain storage, off-chain operation, fully leveraging the traceable and tamper-proof characteristics of on-chain storage.
Based on data credibility, it alleviates the load pressure brought by on-chain operations, distributing it to users, making more rational use of Web3.0 resources while improving the operational efficiency of Dapps.
Additionally, SCP development can be conducted in any programming language, and the efficiency of off-chain computation enhances usability and scalability, with low storage costs; simultaneously, off-chain deployed applications can integrate well with Web2.0 applications.
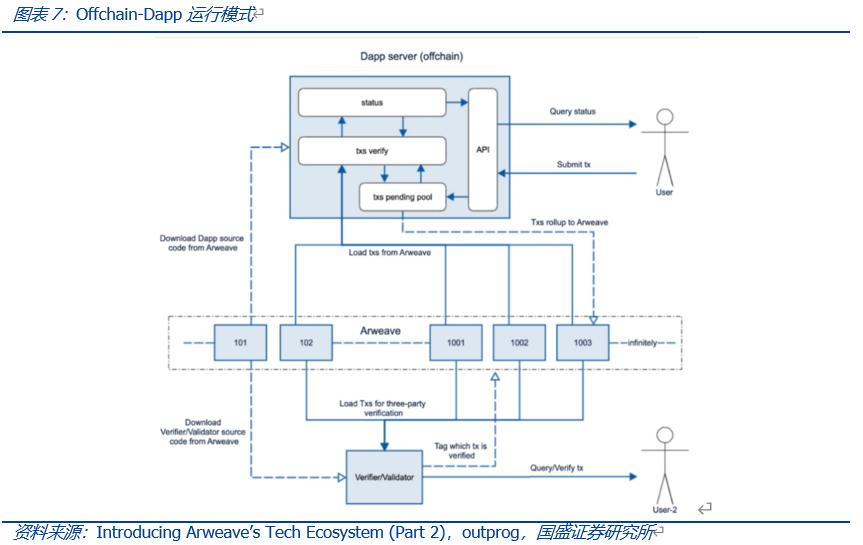
Furthermore, how to ensure the trustworthiness of computations executed by off-chain applications—how to achieve consensus for SCP? Data comes from the AR chain, and applications can also be open-sourced on-chain, thus ensuring that both the computation programs and data have on-chain proof. If users locally modify the application and data, it would effectively create a fork, and the consensus on the computation results of the original data and application would be lost.
This is similar to the open-source code of blockchain projects, where miner nodes run the same open-source client scripts, forming a consistent consensus. If modifications are made to the client code (or data source), it would create a fork. Therefore, although computations are executed off-chain, the data sources and open-source program codes from the chain ensure the trustworthiness of off-chain results.
3.3. Mina: Zero-Knowledge Smart Contracts Snapp
To achieve collaborative data computation between the main chain and external application environments, it is necessary to prove that the data used in each computation is consistent with the data in the blocks on the chain. For data stored in a series of historical blocks, how can we verify the validity of the data in a lightweight and decentralized manner between the main chain and external application environments?
Mina, currently the lightest public chain platform, replaces the blockchain with easily verifiable cryptographic proofs of constant block size through recursive zero-knowledge proofs, eliminating the need to exhaust all blocks, as verification can be achieved with just the latest block (around 21kb). This significantly reduces the amount of data each user needs to download, lowers the threshold for peer-to-peer connections, and enhances the degree of decentralization of the network.
Typically, the entire ledger data volume of public chain blockchains is very large (e.g., Bitcoin's ledger is nearly 400G), and it is dispersed across many blocks in chronological order, creating a significant burden for data verification. Mina uses recursive zk-SNARK (zero-knowledge proof) to achieve verification proof, requiring only a single verification proof for each transaction in each block, which is then stored in the block.
Moreover, it does not create a separate proof for each block; instead, each time a new block is created, it generates a proof that includes the proof of the previous block, storing it in the latest block. This can be simply understood as a nesting effect, where the latest block generates a proof that includes both the data within the current block and the verification proof data of the previous block.
Thus, each block only requires a single proof result, which can encompass the data proofs of all historical blocks. For example, a traveler can prove which attractions they have visited by taking a photo at each one, and when they visit the next attraction, they can hold the previous attraction's photo while taking a new one.
This recursive process means that each photo contains the check-in information of all previous attractions, and only the latest photo is needed to prove that the traveler has indeed visited all the attractions.
This achieves an effect where the blockchain stores only proofs of transaction correctness, rather than the transactions themselves. Because the aforementioned proofs occupy very little space, the size of the blocks can be compressed.
On this basis, Mina has developed more scalable and privacy-centric Dapps—Snapp. Snapp consists of two parts: smart contracts and UI interfaces. Since Snapp is built on zero-knowledge proofs (zk-SNARKs), developers need to construct proving functions and corresponding verification functions to generate and process zero-knowledge proofs.
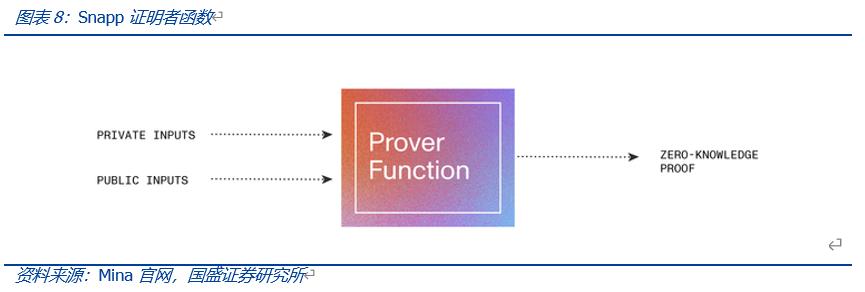
The proving function runs directly in the user's web browser as part of Snapp. When users interact with the Snapp UI, they need to submit private data inputs and public data inputs to the proving function to generate zero-knowledge proofs.
After generating the zero-knowledge proof, users no longer need to provide any private data inputs, thus protecting user privacy. The verification function is used to verify whether the zero-knowledge proof has passed all the constraint functions defined in the proving function (i.e., whether the data is valid), typically completed by the Mina network.
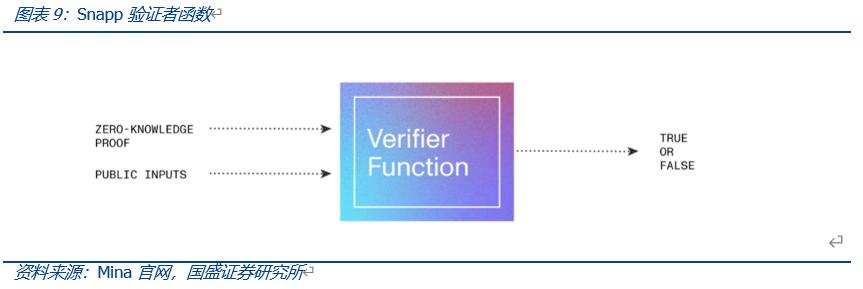
In terms of specific operation, the proving function is completed in the user's web browser, and the generated zero-knowledge proof (verification key) is stored on-chain in the given Snapp account, which is then sent to the Mina network for verification.
Therefore, the generation of transactions and data computation occurs off-chain, while this process generates zero-knowledge proofs that can be used to verify transactions, and the user's original private data remains fully protected. The chain is only responsible for verifying the proof, and upon verification, it is stored on-chain, updating the state of Snapp.
From the user's perspective, when interacting with Snapp, users engage with the smart contract's front-end UI, after which Snapp generates zero-knowledge proofs locally using the data input by the user. The data can be private (not transparently disclosed) or public (stored on-chain or off-chain).
Additionally, a list of Snapp state updates related to the transaction will be generated to change the state of Snapp. Users then submit the data to the Mina network, which verifies the transaction using the verification function provided by Snapp, updating Snapp's state upon successful verification.
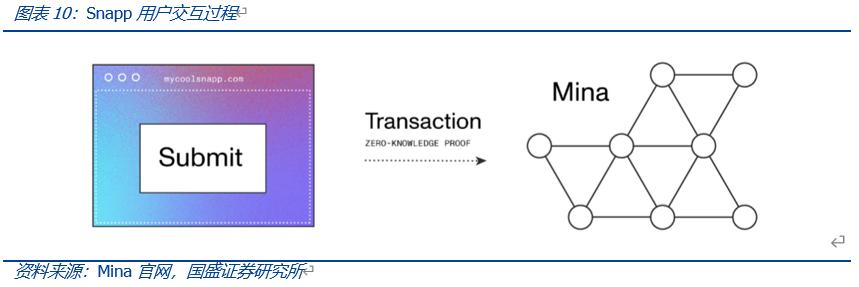
For example, users can generate proof of their credit data locally and submit it on-chain, obtaining flexible credit services from DeFi systems without disclosing their private data; whereas traditional DeFi lending services typically require over-collateralization of assets.
The significance of this application scenario lies in the rapid integration of data and applications from multiple ecosystems, which can be blockchain or off-chain ecosystems. Therefore, Snapp applications can conveniently serve as bridges across chains and between on-chain and off-chain.
3.4. Summary
From the three cases mentioned above, the Oasis platform considered modular layered design from the outset, thus achieving separation of computation and consensus in its initial design. Arweave and Mina similarly use layered solutions to actively separate functions such as computation and storage, with Arweave's SCP and Mina's Snapp emerging after a period of operation on public chains.
In summary, the former represents a design-based layering, while the latter two represent solution-based layering. Setting aside the overall performance of these two different paths, for existing public chains, the path of solution-based layering seems to enable quicker completion of the separation of consensus, computation, and storage, allowing for corresponding adjustments based on their characteristics. However, if layering and modularization become the future development direction, the design architecture of the former may better meet the demands of the times.
4. The Pressing Need in the Web2.5 Era: Oracles
While the true form of Web3.0 may be hard to predict, it is undoubtedly true that data and applications from the Web2.0 era will coexist on the path to the Web3.0 era, continuously merging with Web3.0—data will be shared between the so-called new Web3.0 application ecosystem and the existing Web2.0 ecosystem, applications will run across Web3.0 and Web2.0 systems, and users will belong to both ecological worlds simultaneously. We might refer to the transitional period from Web2.0 to Web3.0 as the Web2.5 era.
In the Web2.5 era, how to share data between two ecosystems, how programs run across two ecosystems, and how the two ecosystems merge will be a pressing need of the times. Sharing data between the centralized world and the decentralized world will give rise to a huge demand for oracle-type applications.
In the Web2.0 era, API interfaces became an important way for apps to obtain external data. An API (Application Programming Interface) is a set of predefined functions or HTTP interfaces that allow users or developers to directly call program routines without accessing the source code.
For apps, APIs serve as windows for obtaining external data and outputting their own data. However, for on-chain applications (Dapps), due to the deterministic and closed nature of blockchain, Dapps generally cannot directly access off-chain data (e.g., a Dapp obtaining real-time BTC prices from Coingecko).
Oracles are the mechanisms for writing external information into the blockchain, essentially providing third-party services that supply external information to smart contracts when they request off-chain data.
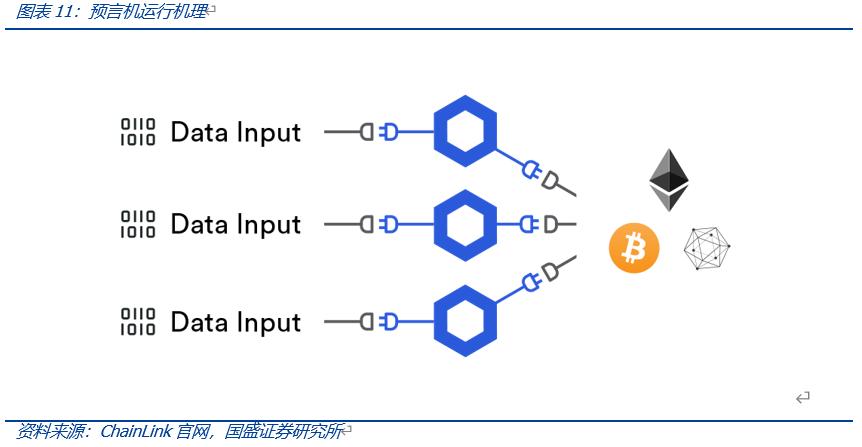
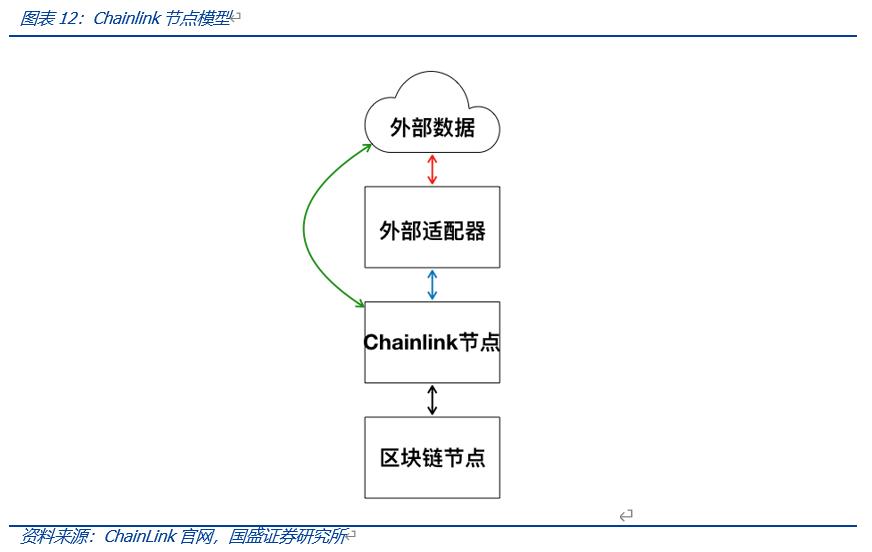
Currently, ChainLink is one of the most widely used oracle protocols on-chain, operating through third-party oracles. When an on-chain contract requests external data, the contract's request is sent to the oracle contract, which then sends relevant events to the third-party off-chain Chainlink network, where the ChainLink network completes the external data collection.
Subsequently, the data is returned to the requesting contract through the oracle contract. The advantage of this method is that the third-party oracle provided by Chainlink can ensure the security of data transmission by determining results through predetermined consensus rules. However, issues such as ineffective redundancy (third-party oracles do not provide external data as efficiently as direct API providers) and lack of transparency (third-party networks cannot ascertain the data source) present challenges for third-party oracles.
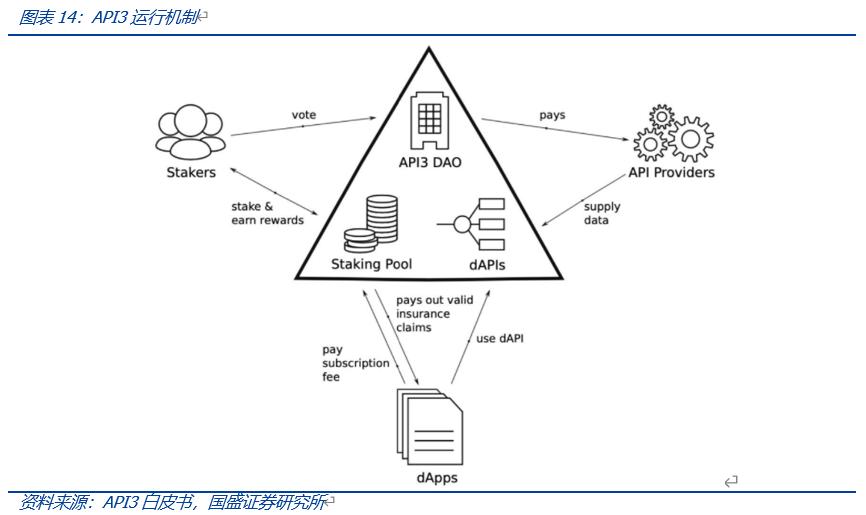
API3 aims to address the issues faced by third-party oracles by employing first-party oracles, directly entrusting the provision of APIs to oracles operated by data providers, forming dAPIs, and managing their data feeds through a DAO.
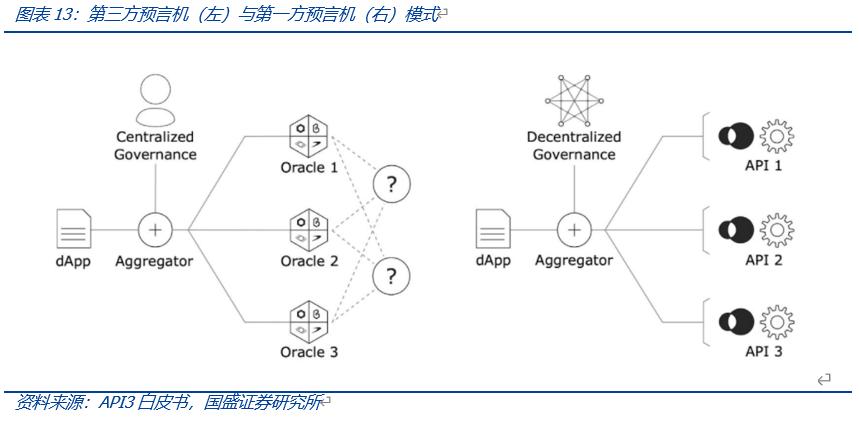
During operation, dApps subscribe to dAPIs services and pay corresponding subscription fees to obtain data or services. If the called data is erroneous, funds from the Staking Pool are used to compensate the subscription. API providers offer dAPIs, each running their own oracle services, with API3 DAO compensating them accordingly.
Stakers provide insurance for the staking pool by staking API3 Tokens and participate in the governance of API3 DAO, primarily selecting quality service providers to enter the aggregator dAPIs.
A crucial aspect of off-chain computation is ensuring the credibility of on-chain data. If we categorize on-chain data based on its source into on-chain generated and off-chain imported data, we need to ensure the credibility of both types of data. The existence of oracle protocols like API3 guarantees the credibility of off-chain imported data, but whether there is a more efficient way to directly assign data that originally needed to be imported off-chain to off-chain computation, thereby reducing the on-chain load, remains to be explored.
Risk Warning
The blockchain business model may not materialize as expected: Web3.0 is based on blockchain, cryptography, and other technologies, and related technologies and projects are still in their early stages, posing risks of business model realization falling short of expectations.
Regulatory policy uncertainties: The actual operation of Web3.0 involves multiple financial, internet, and other regulatory policies. Currently, regulatory policies in various countries are still in the research and exploration stage, with no mature regulatory model in place, thus the industry faces risks from regulatory policy uncertainties.
This article is excerpted from the report "Where Should Web3.0 Programs Run?" published by Guosheng Securities Research Institute on March 9, 2022. For specific content, please refer to the relevant report.
 Risk warning
Risk warning Risk warning
Risk warning



Popular articles








