

















AIGCの困局とWeb3の突破口

 全民AI作画の進行の中で、アーティストはまるで対立する立場にいるかのようだ。
全民AI作画の進行の中で、アーティストはまるで対立する立場にいるかのようだ。執筆:wheart.eth

画像出典:無界版図 AI ツールによって生成された
最近一年、AIGC(AI生成コンテンツ)技術の発展に伴い、ますます多くの人々がその恐ろしさを感じています。AIは創作のハードルを下げ、普通の人々にも自分の創造力を発揮し、専門的なレベルに劣らない作品を作る機会を与えました。しかし、国民全体がAIによる画像生成に取り組む中で、アーティストはその対立面に立っているようです。
Stable DiffusionやMidjourneyを代表とする業界の巨人たちは、しばしばアーティストたちの集団的な抵抗に直面しています!その理由は主に二つです。一つは、これらのモデルがアーティストの作品を無断で使用して訓練され、生成された画像がアーティストのスタイルに非常に似ているため、著作権侵害の疑いがあること。もう一つは、伝統的なアーティストの中には、AIは画像を単純に組み合わせただけであり、芸術とは言えないと考える人がいることです。その乱用は芸術市場に混乱をもたらし、「劣悪な作品が良い作品を駆逐する」現象を引き起こしています。
総じて、現在のAIGC市場は、爆弾を抱えた巨人のようです。外見は非常に強力ですが、内部には未解決の致命的な脅威があります。この脅威が解消されない限り、業界の発展は限られたものとなるでしょう。本稿では、このような状況が生じた背景とその結果について詳しく論じ、可能な解決策を提案します。
最近、ますます多くの画家が、Stable DiffusionなどのAIGCモデルが使用しているデータセットに自分の作品が含まれていることに気づいています。ここには、数十年の試行錯誤を経て形成された独自のスタイルの作品が含まれており、今や人々はAIを利用して数秒で同じスタイルのコンテンツを生成できるようになっています。これはアーティストにとって明らかに不公平です。

(左:AI生成画像、右:アーティストの原画)
これにより、アーティストたちは非常に深刻な懸念を抱くようになりました:彼ら自身の芸術が、将来的に彼らの生計に影響を与える可能性のあるコンピュータプログラムの訓練に使用されているのです。さらに緊急なのは、Stable DiffusionやDALL-Eなどのシステムを使用して画像を生成する人々が、生成された画像の著作権と所有権を持つことです(具体的な条項は異なる場合があります)。あるイラストレーターはこれについて次のように説明しました:人々はAIを使用して書籍の表紙や記事の挿絵などを生成し、これは彼らの生計を脅かすことになります。結局のところ、購入者の視点に立つと、1000枚の画像の中から無料で選び放題であれば、なぜ創作者に1000ドルを支払う必要があるのでしょうか?しかも、これらはすべてアーティストが知らないうちに行われています。
この問題に対して、Stability AIの創設者兼CEOであるEmad Mostaqueは、芸術はStable Diffusionの背後にあるLAION訓練データのほんの一部に過ぎず、芸術的な画像はデータセットの割合が0.1%未満であり、ユーザーが呼び出すことを選択した場合にのみ生成されると述べています。しかし、いくつかの検索ツールが収集したデータは、現存するアーティストの多くの作品がデータセットに含まれていることを示しています。数千枚の作品が存在することは珍しくありません。
技術は原罪?
この問題の出現は偶然ではなく必然であり、AIの発展が避けられない問題です。その理由を詳しく理解するために、AIGC技術の原理と発展の道筋を探ることができるかもしれません。
AIGCは人工知能技術を利用してコンテンツを生成します。2021年以前、AIGCが生成するのは主に文章(代筆)でしたが、新しい世代のモデルは、テキスト、音声、画像、動画、動作などの形式のコンテンツを処理できるようになりました。AIGCは、専門的に生成されたコンテンツ(PGC)やユーザー生成コンテンツ(UGC)に続く新しいコンテンツ創作の方法と見なされ、創造性、表現力、反復、伝播、個性化などの面で技術的な利点を十分に発揮します。2022年、AIGCの発展速度は驚異的で、年初には技術が未熟な段階にありましたが、数ヶ月後には専門的なレベルに達し、偽りのように見えるものを生成できるようになりました。
2014年に提案された「敵対的生成ネットワーク」GAN(Generative Adversarial Network)は、数年前に人気を博した深層学習モデルであり、AIGCの実用的なフレームワークとも言えます(昨年末には主流の研究内容でした)。
GANの基本原理は非常にシンプルです。ここでは画像生成の例を挙げて説明します。仮に、G(Generator)とD(Discriminator)の2つのネットワークがあるとします。名前が示すように、Gは画像を生成するネットワークで、ランダムなノイズzを受け取り、このノイズを通じて画像を生成します。これをG(z)と呼びます。Dは判別ネットワークで、画像が「本物」であるかどうかを判別します。Dの入力パラメータはxで、xは画像を表し、出力D(x)はxが本物の画像である確率を示します。もし1であれば100%本物の画像であり、0であれば本物の画像である可能性はありません。訓練過程において、生成ネットワークGの目標は、できるだけ本物の画像を生成して判別ネットワークDを欺くことです。一方、Dの目標は、Gが生成した画像と本物の画像をできるだけ区別することです。このように、GとDは動的な「ゲームプロセス」を構成します。最終的にゲームの結果はどうなるのでしょうか?理想的な状態では、Gは「偽りのように見える」画像G(z)を生成できます。Dにとっては、Gが生成した画像が本物かどうかを判定するのが難しくなるため、D(G(z)) = 0.5となります。
これにより、私たちの目的は達成されます:画像を生成するための生成モデルGを得ることができました。
しかし、GANには3つの欠点があります。一つは出力結果の制御力が弱く、ランダムな画像が生成されやすいこと。二つ目は生成された画像の解像度が低いこと。三つ目は、GANが判別器を使用して生成された画像が他の画像と同じカテゴリに属するかどうかを判断する必要があるため、生成された画像が既存の作品の模倣であり、革新ではないことです。したがって、GANモデルに依存して新しい画像を創作することは難しく、テキストのヒントから新しい画像を生成することもできません。
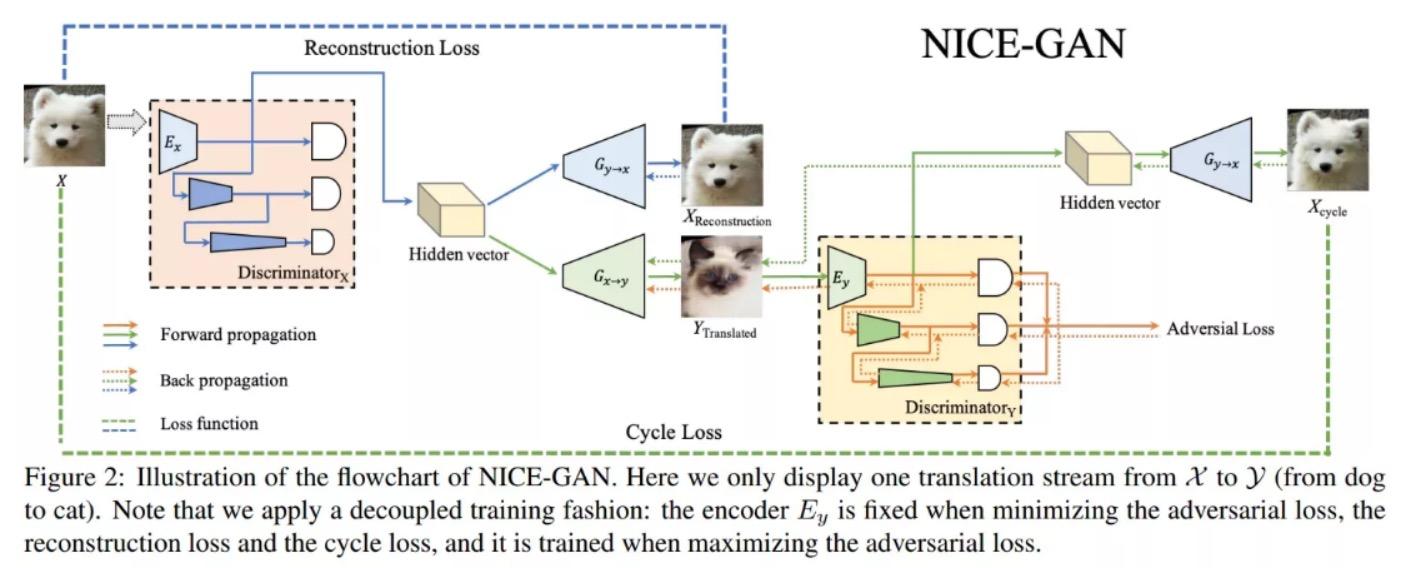
GAN技術原理
2021年、OpenAIチームはクロスモーダル深層学習モデルCLIP(Contrastive Language-Image Pre-Training)をオープンソース化しました。CLIPモデルは、テキストと画像を関連付けることができ、まず4億の未洗浄の画像とテキストのペアのデータセットを収集し、タスクを完了するために事前訓練を行います。対比学習目標を用いて訓練を行い、画像とテキストをそれぞれエンコード(テキストは一文全体)し、ペアごとにコサイン類似度を計算し、各画像の行またはテキストの列を分類して一致する正例を見つけます。各画像には32,768のテキスト候補があり、これはSimCLRの2倍であり、負例の数が増えることも効果が良い理由の一つです。予測時も非常にシンプルで、画像分類のデータセットを見つけ、ラベルを自然言語に変換します。例えば「犬」は「犬の写真」と変換できます。そして、事前訓練されたエンコーダーを使用してラベルと画像をエンコードし、類似度を計算します。
アルゴリズムの全体的なプロセスは次のように要約できます:入力画像を与え、32768のランダムにサンプリングされたテキスト片の中で、どれが実際にデータセットとペアになっているかを予測します。テキストの記述は具体的なカテゴリではないため、さまざまな画像分類タスクでゼロショットを行うことができます。ゼロショットは転移学習の一種で、例えば「シマウマ」を説明する際に「馬の輪郭+虎の毛皮+パンダの白黒」を用いて新しいカテゴリを生成します。通常の監視分類器は馬、虎、パンダの画像を正しく分類できますが、学習していないシマウマの写真には分類できません。しかし、シマウマは既に分類された画像と共通点があるため、この新しいカテゴリを推論することができます。
したがって、考え方は次のようになります:より細かい属性を設定し、テストセットとトレーニングセットの間の関連を確立します。例えば、馬の特徴ベクトルを意味空間に変換し、各次元がカテゴリの記述を表します。【尾がある1、馬の輪郭1、ストライプ0、白黒0】、パンダは【尾がない0、馬の輪郭0、ストライプ1、白黒1】、このようにシマウマのベクトルを定義し、入力画像のベクトルとシマウマのベクトル間の類似度を比較することで判別できます。
したがって、CLIPモデルには二つの利点があります。一つは自然言語理解とコンピュータビジョン分析を同時に行い、画像とテキストのマッチングを実現すること。もう一つは、十分な数のラベル付き「テキスト-画像」を訓練に利用するため、CLIPモデルはインターネット上の画像を広く利用し、これらの画像は一般的にさまざまなテキスト記述を伴い、CLIPの自然な訓練サンプルとなります。統計によると、CLIPモデルはネット上で40億以上の「テキスト-画像」訓練データを収集しており、これは後続のAIGC、特にテキスト入力から画像や動画を生成するアプリケーションの実現に基盤を築いています。
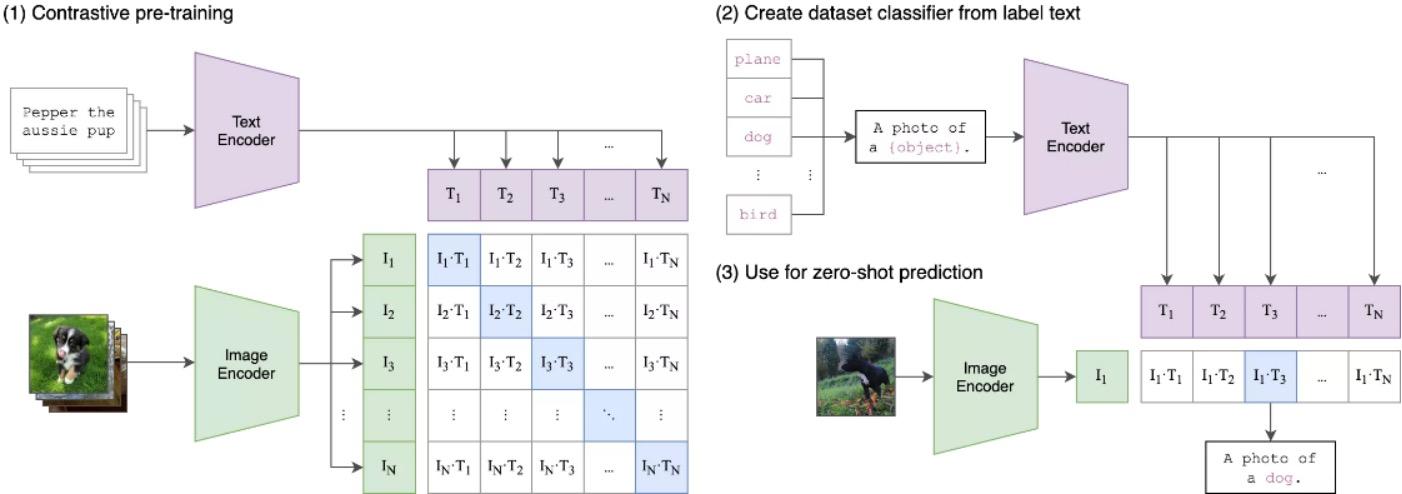
CLIP技術原理図
その後登場したDiffusion拡散モデルは、テキストから画像を生成するAIGCアプリケーションを一般に知らしめることになり、2022年下半期のStable Diffusionアプリケーションの重要な技術的核となりました。
拡散モデルのインスピレーションは非平衡熱力学から得られています。拡散ステップのマルコフ連鎖(現在の状態は前の状態にのみ依存)を定義し、徐々に本物のデータにランダムノイズを追加します(前向きプロセス)、その後、逆拡散プロセスを学習し、ノイズから必要なデータサンプルを構築します。
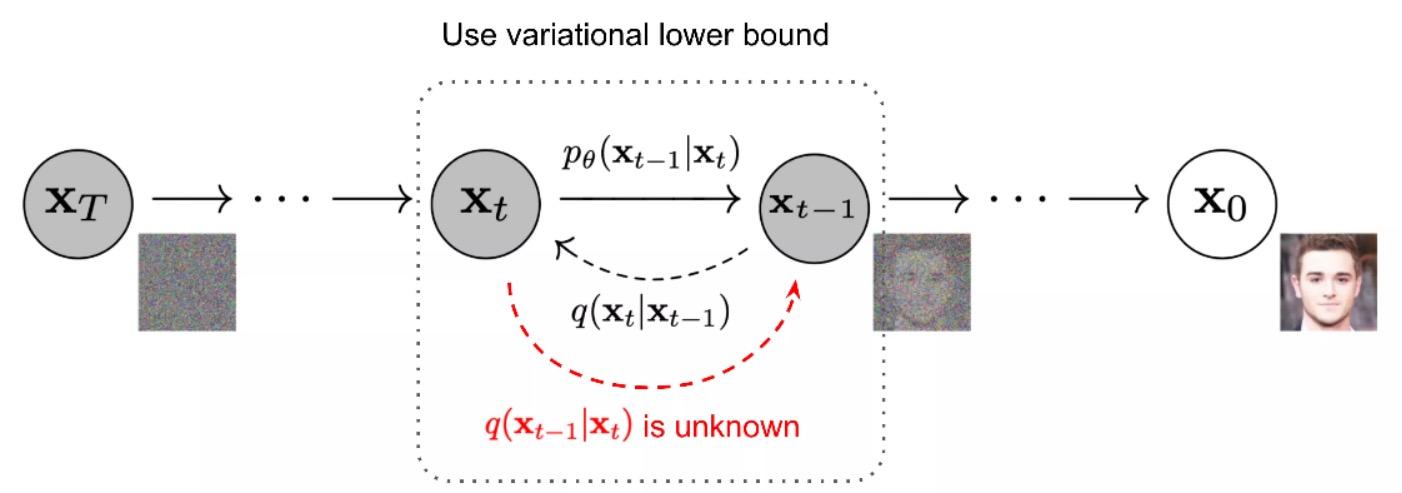
Diffusion Models技術原理図
前向きプロセスはノイズを加える過程であり、時間ステップが増えるにつれて追加されるノイズが増加します。マルコフ定理に基づき、ノイズを加えたこの時点は前の時点との関連性が最も高く、加えるべきノイズに関連しています(前の時点の影響が大きいか、加えるノイズの影響が大きいか、前向きの時点が進むにつれてノイズの影響の重みが増していきます。最初は少しノイズを加えるだけで効果がありますが、その後はノイズをますます多く加える必要があります)。
逆向きプロセスは、ランダムノイズから始まり、徐々にノイズのない元の画像に戻すことです------ノイズを除去し、リアルタイムでデータを生成します。ここでは、すべてのデータセットを知る必要があるため、条件付き確率を近似するための神経ネットワークモデル(現在の主流はU-net + attention構造)を学習する必要があります。
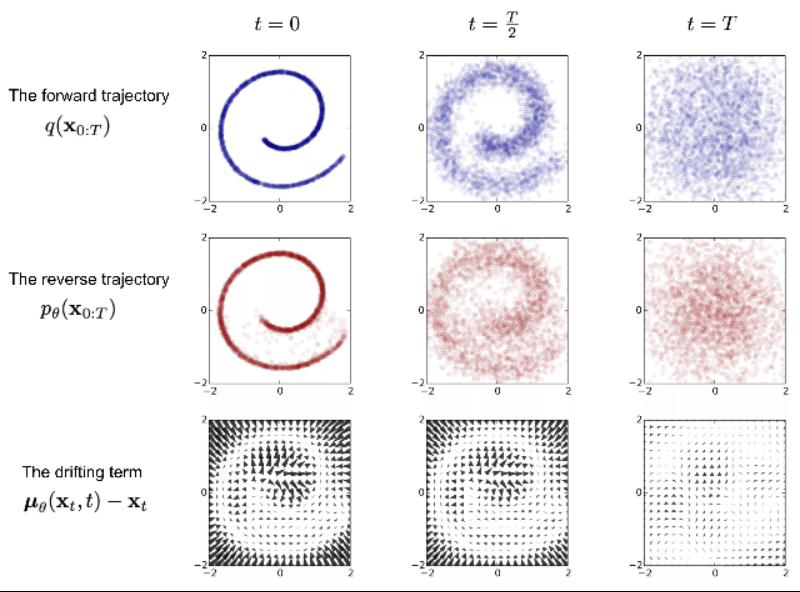
Diffusion Models逆向きプロセス
Diffusionモデルには二つの特徴があります。一つは、画像にガウスノイズを加え、訓練データを破壊することで学習し、その後、元の画像を復元するためにこのノイズプロセスを逆転させる方法を見つけることです。訓練を経て、このモデルはランダムな入力から新しいデータを合成することができます。もう一つは、Stable Diffusionがモデルの計算空間をピクセル空間から数学的変換を経て、可能性空間の低次元空間に圧縮することで、計算量と計算時間を大幅に削減し、モデルの訓練効率を大幅に向上させることです。このアルゴリズムの革新は、AIGC技術の突破的進展を直接推進しました。
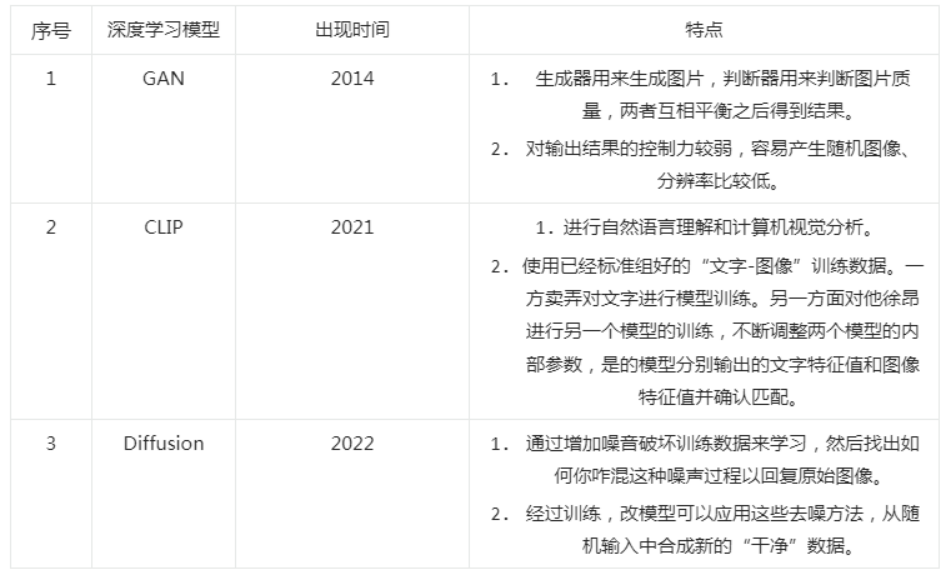
AIGC関連深層学習モデルのまとめ
脆弱性!
以上のアルゴリズムの概要からもわかるように、AIGCは本質的に機械学習であり、したがって、大量のデータセットを使用して訓練を実行することは避けられません。その中には、画像の著作権者の利益を損なうものが確かに存在します。
私たちはこの状況の存在を知っていますが、解決するのは依然として難しいです。
アーティストにとって、これらのプラットフォームが自分の権利を侵害していると考えていますが、現在、こうした侵害行為を規定する法律は整備されておらず、特定の法律条文の中では、この行為が合法である場合もあります。
一方で、AIGCは「著者」と呼ぶことが難しいです。著作権法は一般に、著者は自然人、法人、または非法人組織であると規定していますが、明らかにAIGCは法律上認められた権利主体ではないため、著作権の主体にはなれません。しかし、AIGCアプリケーションは生成された画像の著作権問題について異なる見解を持っており、画像はプラットフォームに属するのか、完全にオープンソースなのか、生成者に属するのか、現在は統一された意見が形成されていません。
もう一方で、AIGCが生成する「作品」には依然として議論があります。伝統的な意味での作品は、文学、芸術、科学の分野において独創性を持ち、何らかの有形の形で再現可能な知的成果を指します。AIGCの作品は、強いランダム性とアルゴリズム主導性を持ち、AIGC作品の著作権侵害を正確に証明する可能性は低いです。また、AIGCが独創性を持つかどうかは現時点では一概には言えず、個別のケースによって大きく異なります。
現在、自分の作品をデータセットから削除しても、自分のスタイルの作品が生成されるのを防ぐことはできません。まず、AIモデルはすでに訓練されており、対応するスタイルを習得しています。また、OpenAIのCLIPモデル(Stable Diffusionを訓練してテキストと画像の関連を理解するために使用される)により、ユーザーは特定の芸術スタイルを呼び出すことができます。
AIプロジェクト側にとって、データセットの各画像に対して許可を得ることは現実的ではありません。このような法案が通過すれば、AI業界の発展は大きな障害を受けるか、あるいは壊滅的な打撃を受けるでしょう。したがって、妥協案が必要です。
解決策?
まず、AIGCの創作の閉じたループを分析してみましょう:
創造的な構想の面では、AIGCは新しい創造的なプロセスを構築しました。従来の創作プロセスにおける消化、理解、反復作業はAIGCに任せることができ、最終的な創造プロセスは「創造-AI-創作」のモデルに変わるでしょう。
創造の実現の面では、創作者とAIGCの関係は、写真家とカメラの関係に似ています。写真家は撮影のアイデアを構築し、計画を立て、カメラのパラメータを設定しますが、カメラの動作メカニズムを理解する必要はありません。一方で、高品質のコンテンツを一発で生成できます。同様に、創作者はアイデアを構想し、計画を立て、AIモデルのパラメータを設定しますが、モデルの原理を理解する必要はなく、直接出力内容をクリックするだけで済みます。創造と実現は分離された状態を呈し、実現プロセスは再現可能な労働となり、AIGCによって完了され、コストはゼロに近づくことができます。
したがって、ここには二つの大きな主体があります:創作者とAIGC。創造は重要であり、創作も同様に重要です。AIが生成した画像は創作者の「創造的著作権」であり、AIGCまたはアーティストのスタイルを採用した「基盤的創造/創作著作権」です。両者は生成されたコンテンツに対して権利を持つべきであり、現在の状況はアーティストの利益が欠けているのです。
実際、アーティストはAIが彼らの作品を学ぶことを許可していないわけではなく、相応の利益を得たいと考えています。したがって、この設計がアーティストの承認を得れば、AIGCの脆弱性は修正されるでしょう。
創作者の成果はAIGCが学ぶ対象ですが、創作者の創造性こそが重要です。創造性自体がAIGCが生成した絵画よりも価値があるため、創作者の「創造性」をどのように定量化し、さらには価格を付けるかが、AIGCのビジネスモデルを構築するのに役立つでしょう。この中で「注意メカニズム」がAIGCの潜在的な定量化の手段となります。例えば、ある機関の専門家が提案したように、入力テキスト中のキーワードが影響を与える絵画の面積と強度を計算することで、各キーワードの貢献度を定量化できます。その後、生成コストとアーティストの貢献比率に基づいて、創作者の生成した価値を得ることができます。最後に、プラットフォームと按分して分け合うことで、創作者は理論的に創造性に基づく利益を得ることができます。
例えば、あるAIGCプラットフォームが1週間で数十万枚の作品を生成し、その中でこの創作者に関連するキーワードの作品が30000枚ある場合、平均的な貢献度が0.3で、AIGCの生成コストが0.5元、プラットフォームの分配が30%であれば、この創作者はその週にこのプラットフォームで得られる利益は:30000*0.3*0.5*(1-30%)=3150元となり、将来的にはAIデータセットの構築に参加することでアーティストの新たな収入源となる可能性があります。
しかし、上記の設計にも欠陥があります。AIは完璧ではなく、すべての画像に価値があるわけではないため、ここでの最適化案は、生成時にアーティストに支払わず、満足のいくコンテンツをダウンロードしたいときにのみ、相応の費用を支払うというものです。これは従来の芸術創作のプロセスとも似ており、甲方が注文し、乙方が満足のいく作品を提供したときに甲方が全額を支払います。
プロセスをより適法にし、完璧にするためには、まず世界中のアーティストにスタイルライブラリを公開し、各アーティストが自分の作品を訓練セットのギャラリーに追加するかどうかを選択できるようにします。もし追加すれば、他のユーザーが対応するスタイルを創作する際に相応の利益を得ることができます。これはアーティストに新たな収入源を求める一方で、現在の市場における「著作権侵害」が多い背景の中で、この「正規ライセンス」のギャラリーはアーティストコミュニティから支持を受けることになるでしょう。このモデルはより正の循環に似ており、より健全なモデルです。
Web3?
Web3は常に「クリエイター経済」を強調しており、これはAIGCが解決しようとしている問題と一致しています。ブロックチェーン技術を利用することで、AIGCを中心としたエコシステムネットワークを構築することができます。
クリエイターはAICGの力を借り、Web3モデルの経済モデルを加えることで、自分の創造性と影響力を指数関数的に拡大できます。また、より多くの人々が消費者から参加者、ユーザーから所有者への転換を実現できるようになります。同時に、アーティストは彼らが得た利益の分配を受け取り、ウィンウィンの状況を達成します。
実際、Web3+AIは新しいことではなく、生成的アートNFTのリーダーであるArt Blocksは成功したアプリケーションの一例です。(アルゴリズムは異なりますが、同様の効果があります。)
Art Blocksは、ランダムなアート作品を生成するプラットフォームです。2020年にErick Snowfroによって立ち上げられ、プログラム可能な生成コンテンツに特化したプラットフォームであり、生成されたコンテンツはイーサリアムブロックチェーン上で変更できません。「ランダムアート作品」はどのようにランダムなのでしょうか?このランダムプロセスは、一連の数字によって制御されており、この数字はイーサリアムチェーン上の非同質化トークン(NFT)に保存されています。その後、このトークンに保存された数字の列が、購入したアート作品の一連の属性を制御し、最終的にあなたのための唯一無二のアート作品が生成されます。
もしあなたがあるアーティストのスタイルを気に入っている買い手であれば、支払いを行った後に鋳造を開始し、アルゴリズムがランダムな同スタイルのアート作品をあなたのアカウントに送信します。この作品はトークンの形で存在し、最終的な作品は静的画像、3Dモデル、またはインタラクティブなアート作品である可能性があります。各出力は異なり、プラットフォーム上で作成されるコンテンツのタイプには無限の可能性がありますが、各プロジェクトで鋳造できるアート作品の数は一定です。つまり、一度鋳造が満了すると、そのプロジェクトでは新しい作品が生成されなくなります。
創作者にとっては、Art Blocks上で自分の生成アートスクリプトを事前に調整し、展開する必要があります。そして、その出力結果が入力のハッシュ値に関連していることを確認する必要があります。このスクリプトはArt Blocksを通じてイーサリアムチェーンに保存されます。
コレクターにとっては、コレクターが特定のシリーズの作品を鋳造する際(購入ボタンをクリックする際)、実質的にはランダムなハッシュ値を取得し、その後スクリプトが実行され、そのハッシュ値に対応する生成アート作品がその場で創作されます。
このモデルは、コレクターも生成アートの創作に参加することを可能にします。
この作品の内容は、実際には元のアーティストのスタイル、生成アルゴリズム、あなたの鋳造のタイミングの三者によって決まります。ツール、創作者、買い手が共同でこの作品を完成させることで、この新しいNFT創作モデルはこのアート作品により多くの記念価値を持たせ、最新の技術の痕跡を残します。
主流のNFTアバタープロジェクトを購入するのとは異なり、Art BlocksでNFTを購入することは、アーティストを直接支援することに近いです------これらのアーティストはしばしば実名であり、多くの歴史的作品を持ち、Art Blocksは彼らの作品に関する深いインタビューを行います。Art Blocksで初めて販売されるNFTでは、アーティストは90%の収入を得ることができ、残りの10%はArt Blocksに分配されます。
したがって、皆さんはArt BlocksがAIGCに「大きな道」を開いたことに気づくでしょう。この道は完全にコピー&ペーストできるわけではありませんが、詳細に関しては変更することでAIGC+Web3のビジネスの閉じたループになることができます!そして、現在もすでに類似のことを行っているプロジェクトがあります。
多くの先駆者が道を切り開いているため、AIGCがますます遠くへ進むことを信じる理由があります。現在の欠陥も徐々に修正され、改善されるでしょう。
 リスク警告
リスク警告 リスク警告
リスク警告











