

















Codatta の目的:AI の知識プロトコル層を構築する
 従来のデータアノテーションシーンに対して、CodattaはMTurkやScale AIなどのプラットフォームの高品質なバックエンドとして機能し、法定通貨やステーブルコインでの支払いをサポートすることで、従来のサービスが専門家ネットワークにアクセスし、高度な知識データを取得できるようにします。
従来のデータアノテーションシーンに対して、CodattaはMTurkやScale AIなどのプラットフォームの高品質なバックエンドとして機能し、法定通貨やステーブルコインでの支払いをサポートすることで、従来のサービスが専門家ネットワークにアクセスし、高度な知識データを取得できるようにします。AIのデータ基盤を理解する
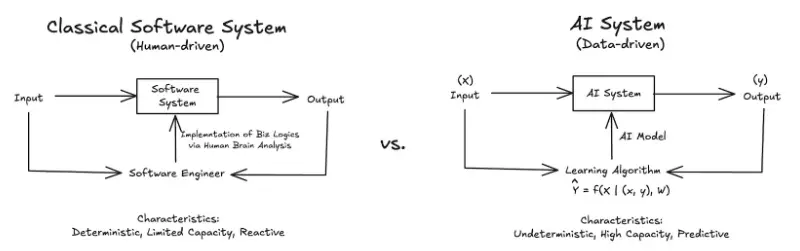
図1: 従来のソフトウェアシステム(人間主導)対AIシステム(データ主導)
AIモデルはデータを通じてパターンを学習し、推論を行い、新しい問題を解決します。明示的なルールに依存する従来のソフトウェアとは異なり、生成AI(大規模言語モデル)は膨大なデータセットと入力-出力サンプルによってAIシステムを駆動します。
産業界の実践経験に基づくと、約80%のAIエンジニアリング投資はデータプロセスに集中しており、パイプラインの構築、クリーニング、前処理などが含まれ、アルゴリズムの開発にはあまり集中していません。高品質で高知識密度のデータが重要です。大規模言語モデルの発展に伴い、専門的な知識と推論データの需要が著しく増加し、基礎的なアノテーションの需要は基礎モデルの能力向上に伴い減少しています。
生成AI時代:データの役割の進化

図2: AIモデル開発の段階: 基礎から垂直AIへ
生成AI時代において、データの役割は根本的に変化しています。従来のアノテーションデータの重要性は低下し、高品質で高知識密度のデータの需要は爆発的に増加しています。AIモデルのトレーニングは通常、3つの段階に分かれています。まず、インターネットデータに基づく事前トレーニングを行い、基礎的な認知能力を構築します。次に、人工的にアノテーションされた好みのデータを使用して微調整を行い、インタラクション体験を最適化します。最後に、強化学習を通じて合成データを生成し、モデルの一般化能力を向上させます。
しかし、『自然』誌などの研究は、合成データには明らかな限界があることを示しています。過度の使用は「モデル崩壊」を引き起こし、出力の質に深刻な影響を与えます。これは、実データの重要な価値を浮き彫りにしています。基礎的なAI能力が向上するにつれて、専門分野のアプリケーションはますます人間の専門家が提供する高品質な知識データに依存するようになります。これらの人工生成された高品質データは、モデルの微調整や効果評価などの重要なプロセスにおいて依然として不可欠です。
ロイヤリティインセンティブによるAIデータエコシステムの再構築
AI開発者(特にスタートアップ)は、高品質な専門知識データを取得する際に高額な初期コストに直面しています。従来の調達方法は多大な初期投資を必要とし、重要な人間の知能データの取得が困難になり、AIの革新プロセスを遅延させます。
分野の専門家はAIシステムに重要な知識を提供し、その専門的な洞察はAIが専門家自身の仕事を代替する可能性を持っています。しかし、彼らは通常、一度きりの報酬しか得られず、その金額はしばしば不十分です。このインセンティブの不一致は、専門家の意欲を削ぐだけでなく、AIの利益分配の公平性の問題を引き起こします。
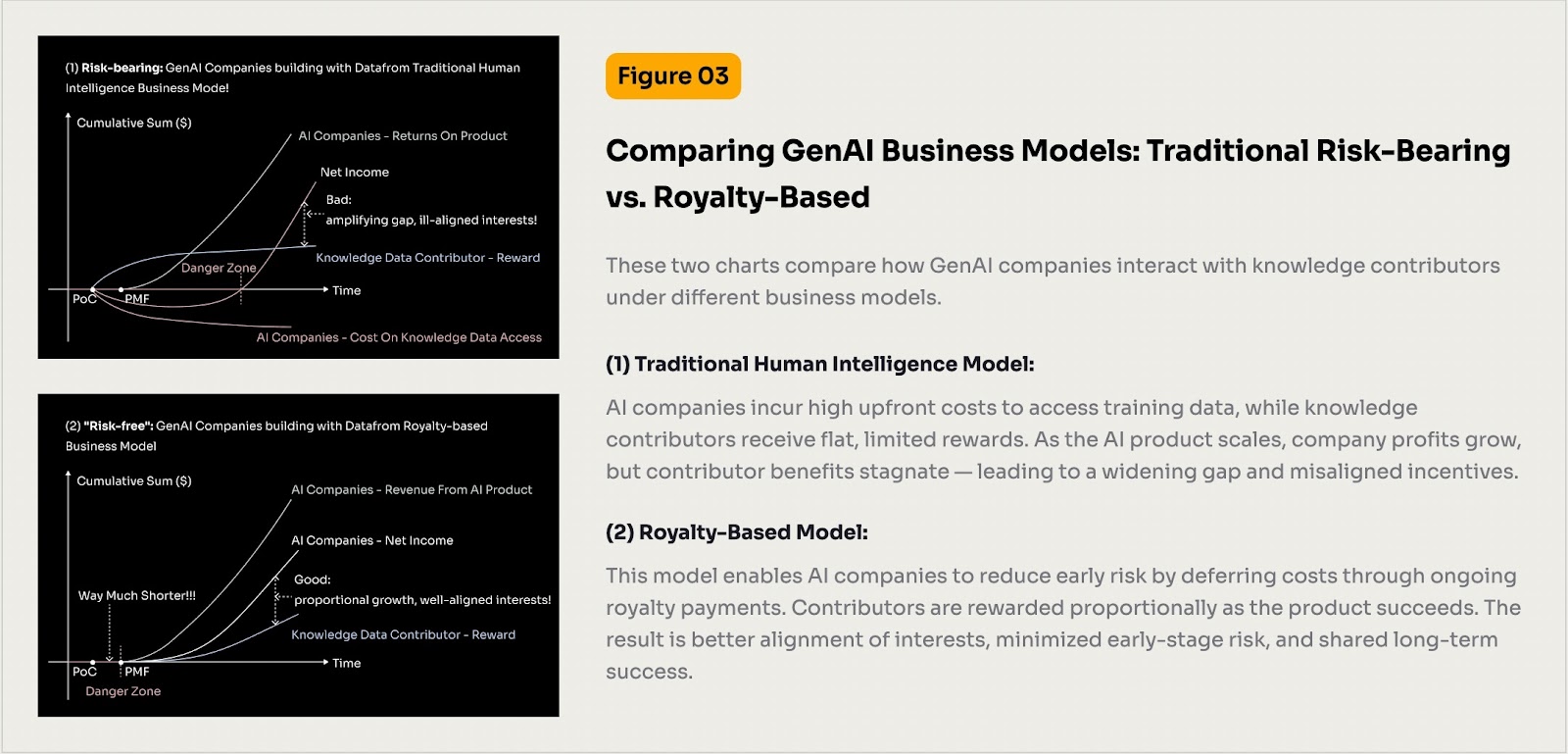
図3: GenAIビジネスモデルの比較
Codattaは、ブロックチェーンに基づくデータ資産化ロイヤリティ支払いモデルを通じてこの問題を解決します。このソリューションは、開発者が前払いの障壁を免除され、収益分配を通じて高品質なデータを取得できるようにします。報酬を長期的な収益に結びつけることで、Codattaは革新の障壁を低下させ、専門家に持続可能なインセンティブシステムを構築します。
データ提供者は共有所有権を得て、自身のデータを使用するAIアプリケーションから継続的にロイヤリティを得ることができます。このモデルは、AIスタートアップへの投資に似ています。このような資産の特性とその価値創造の潜在能力に基づき、関連する権利は取引を通じて流動性を実現し、収益化のニーズに柔軟に対応できます。この収益メカニズムは、データの影響力と同期して成長する長期的な収益メカニズムであり、専門知識の価値を真に反映し、従来の一回限りの買い取りモデルよりも公平性において優れています。
データから資産へ:チェーン上のロイヤリティ支払い実践

図4: Codattaのデータ資産化フレームワーク
この図は、Codattaのデータ資産化とロイヤリティ分配の核心メカニズムを示しています。左側には、データの貢献(X、Y、および知識点KP0、KP1、KP2、KVO、KV1)がコンテンツハッシュ値と共にチェーンに提出され、暗号化されたデータペイロードは混合ストレージソリューションに保存される様子が示されています。右側では、特定のAIモデルがこれらのデータを利用して顧客に推論を提供する様子が描かれています。重要な「データ帰属」モジュールは価値の貢献を追跡し、使用状況と影響に基づいてロイヤリティを公平に分配します。
データ資産化を実現するために、Codattaは3つの主要な柱を構築しました:インフラストラクチャ、コミュニティ、インセンティブメカニズムの設計:
- プライバシー保護の透明性:
私たちのシステムは、ブロックチェーンを通じてすべてのデータ貢献を記録し、出所、帰属、所有権に関する永続的な検証可能な記録を作成します。すべてのデータ資産は暗号化ストレージを使用し(分散型と集中型の混合アーキテクチャをサポート)、商業的価値を保障しつつ、公平な認識とロイヤリティ分配を確保します。Codattaはスマートコントラクトを通じて知識を追跡可能で収益を生むデジタル資産に変換します。
- 人間の貢献者と専門AIの協調ネットワーク:
私たちは透明で評判駆動のシステムの中で、人間の専門家とAIを同時に活用します。AIは初期タスクを処理し(速度/規模を追求)、人間は専門的な洞察を用いて出力を最適化します。この二層のアプローチは業界標準となりつつあります。Codattaはこのモデルをさらに拡張し、人間が知識提供者、検証者、または資金提供者として多重の役割を果たすことを可能にします。各役割は公開され、動的な評判システムに関連付けられ、質と責任感を促進します。
- プログラム可能なインセンティブモジュール:
データの相互作用(収集、検証、改善)とカスタマイズされた報酬が結びついています。スマートコントラクトはロイヤリティ、評判、またはステーキングのインセンティブを自動的に分配し、データの価値に基づく公平な報酬を確保します。これらのモジュールは評価と帰属アルゴリズムを使用し、トレーニングと推論の過程で知識の影響力を分析します。さまざまなデータタイプに適応し、長期的な公平な補償を最適化し、持続可能な知識経済の発展を促進します。
これらの3つの柱------暗号化ストレージのチェーン上の透明性、人間とAIの混合ネットワーク、プログラム可能な報酬メカニズム---は、Codattaのデータ資産化フレームワークを形成します。このシステムは知識の貢献を安全で追跡可能なデジタル資産に変換し、継続的にロイヤリティ収益を生み出すことで、人間の知能と拡張可能で持続可能なAIの発展の架け橋を築きます。
オープンデザイン:従来のAIと分散型知能をつなぐ
Codattaは、分散型AI(DeAI)と従来のWeb2/Web3人間知能サービスをつなぐ柔軟な知識ネットワークです。従来のデータアノテーションシーンに対して、CodattaはMTurk/Scale AIなどのプラットフォームの高品質なバックエンドとして機能し、法定通貨/ステーブルコインの支払いをサポートすることで、従来のサービスが専門家ネットワークにアクセスして高次の知識データを取得できるようにします。これにより、従来のプラットフォームはWeb3の複雑さに対処することなく、ブロックチェーンレベルの検証と品質保証を享受し、即座に利用可能になります。
DeAI技術スタックにおいて、Codattaはデータキュレーションに焦点を当てています------この重要な第一歩の段階です。私たちは、ブロックチェーンがDeAIにおける貢献者の身元認証、データ/モデルの検証、トレーサビリティ、使用監視に最も適していると考えています。私たちのデザインは、重い計算/ストレージタスクを集中型インフラにオフロードして効率を向上させる一方で、分散型システムを通じて透明性、責任追及可能性、公平な価値分配を確保します。このハイブリッドアプローチは、拡張性を保証しつつ、整合性を維持し、信頼できるAIデータサプライチェーンを構築します。
Codattaは、集中型と分散型エコシステムをつなぐことで、より公平で高性能なAIシステムの構築に取り組んでいます------ここでは、人間の貢献者が認識され、データの完全性が保護され、インセンティブメカニズムが長期的な価値創造と一致しています。
注:Codattaの旅は、Microscopeオープンソースプロジェクトの開始(Coinbase、Messari、GoPlusとの協力)から始まり、現在は生成AI向けの汎用人間知能プラットフォームに発展し、AI開発者の基盤支援を目指しています。そのフラッグシップ製品である暗号アカウントアノテーションシステム(CAA)は、35のブロックチェーンネットワークをカバーし、4,600万の高リスクアドレスをアノテーションし、5.6億回のアノテーションを完了(95のカテゴリをカバーし、10万人以上の貢献者が共同で構築)しています。現在のビジネスは評価、eコマース、医療健康、フィットネスなどの複数の分野に拡大しており、明確な発展ロードマップを策定しています。2024年には100以上の知識分野をカバーし、30万人以上の貢献者を集める予定です。2025年にはプロトコルの完全な分散化を実現し、2026年には完全なデータ資産化を達成し、すべての知識貢献が収益化可能な資産となることを目指しています。
 リスク警告
リスク警告 リスク警告
リスク警告












