Scrollの創設者、張烨:zkEVMの設計、最適化と応用

 Scrollは、非常に先進的な算術回路と証明システムを使用して、zkRollupのEthereum汎用スケーリングソリューションを構築しており、ハードウェアアクセラレーションを通じて高速な検証者と証明の再帰を構築しています。
Scrollは、非常に先進的な算術回路と証明システムを使用して、zkRollupのEthereum汎用スケーリングソリューションを構築しており、ハードウェアアクセラレーションを通じて高速な検証者と証明の再帰を構築しています。原文作者:Ye Zhang
原文来源:Scroll CN
编译:F.F
最新のZKP Moocコースでは、Scrollの共同創設者である張烨がzkEVMの設計、最適化、応用についての講演を行いました。Scrollは、イーサリアムと同等のZK-Rollupを構築しており、バイトコードレベルでの互換性を持ち、すべての既存ツールを直接サポートしています。
以下はビデオの文字起こしバージョンです。
講演は4つの部分に分かれており、第一部では張烨が開発の背景と、なぜまずzkEVMが必要なのか、そしてなぜ最近の2年間でこれほど人気が高まったのかを紹介しました。第二部では、完全なプロセスを通じて、ゼロからzkEVMを構築する方法を説明し、算術化と証明システムを含みます。第三部では、ScrollがzkEVMを構築する際に直面した問題について、いくつかの興味深い研究課題を紹介しました。最後に、zkEVMを使用した他のアプリケーションについて紹介しました。


背景と動機

従来のLayer 1ブロックチェーンでは、いくつかのノードがP2Pネットワークを通じて共同で維持されています。彼らはユーザーの取引を受け取ると、EVMの仮想マシン内で実行し、コントラクトを呼び出し、ストレージを読み取り、取引に従ってグローバルな状態ツリーを更新します。
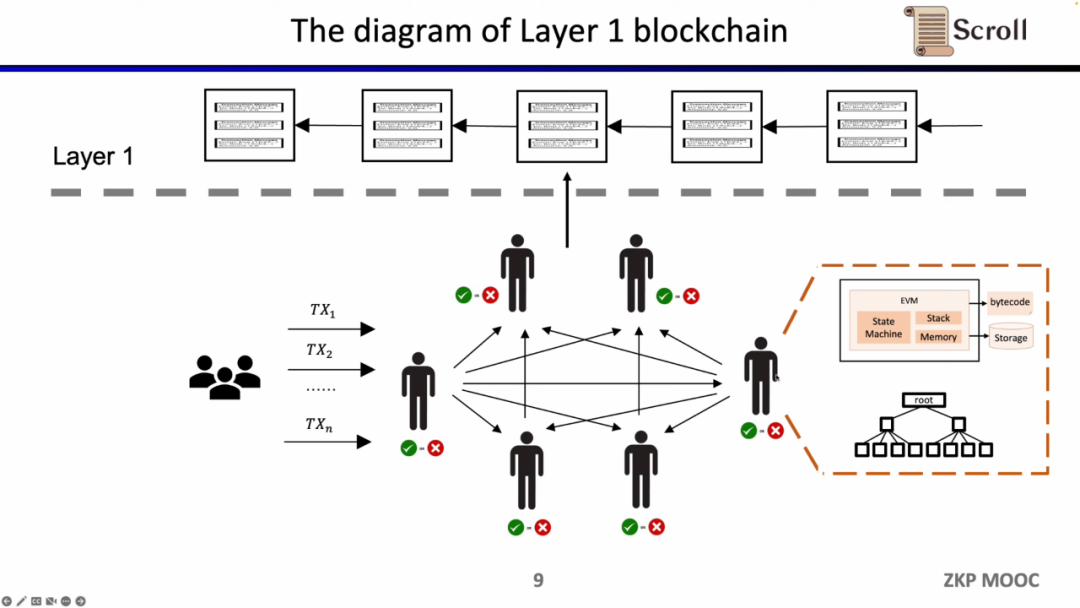
このようなアーキテクチャの利点は、分散化とセキュリティにありますが、欠点はL1上の取引手数料が高く、取引確認が遅いことです。
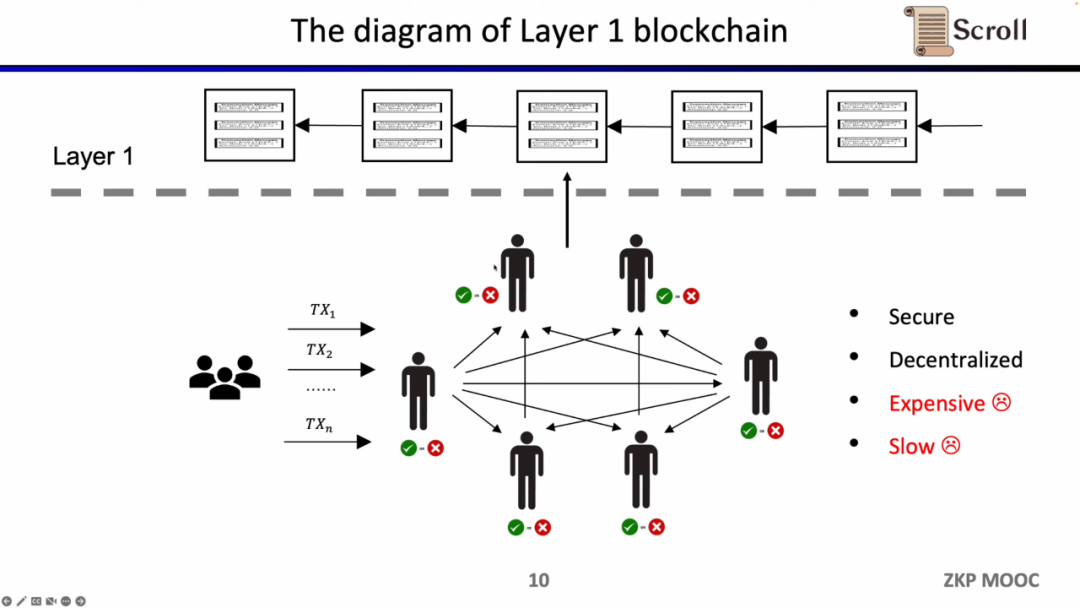
ZK-Rollupのアーキテクチャでは、L2ネットワークはデータとその正当性を証明する証明をL1にアップロードするだけで済み、その証明はゼロ知識証明回路によって計算されます。
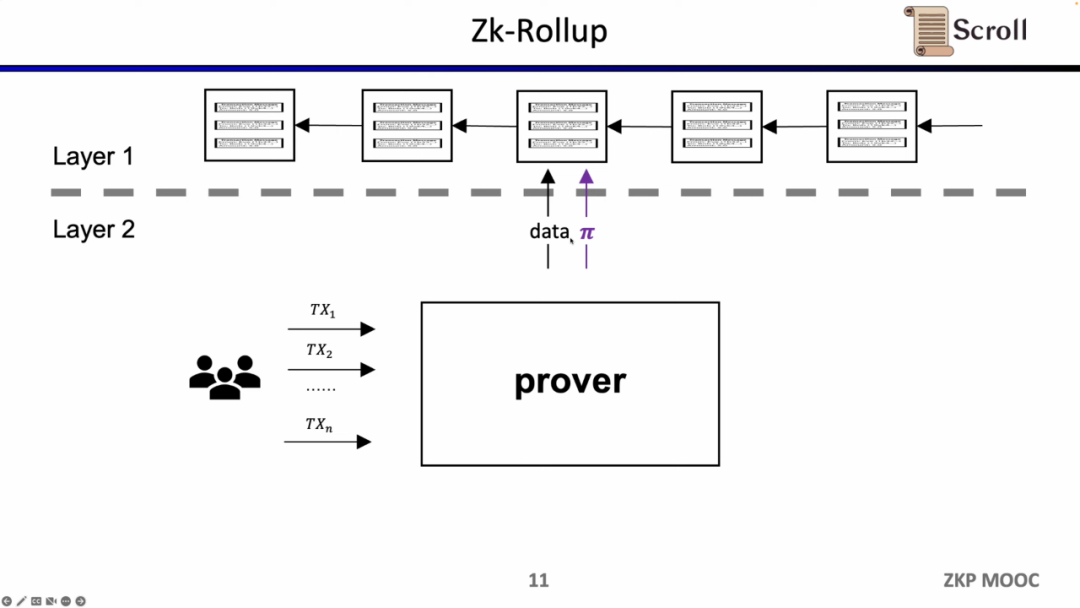
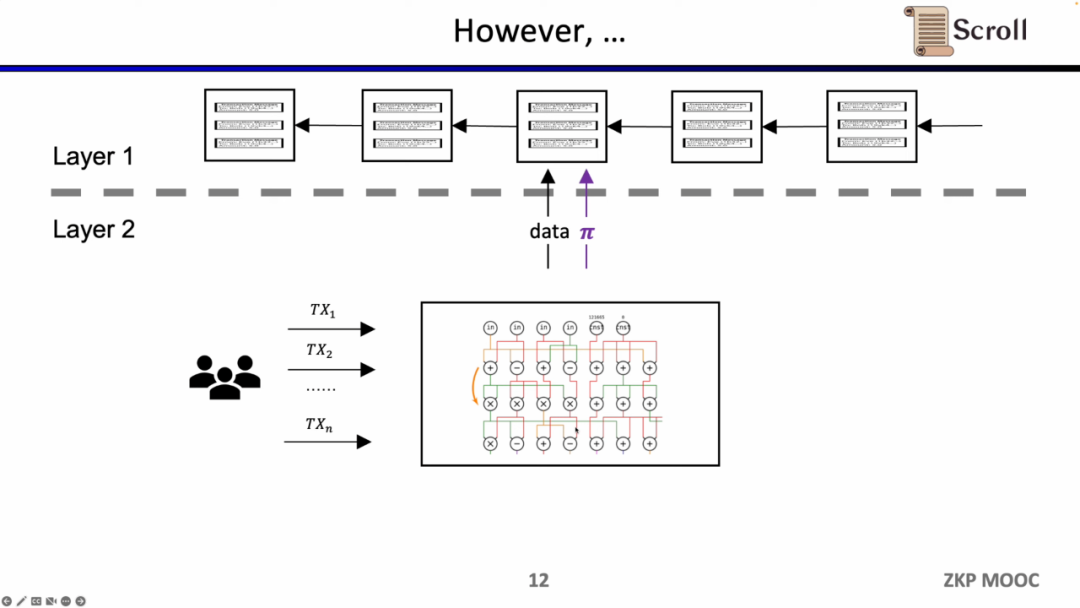
初期のZK-Rollupでは、回路は特定のアプリケーション向けに設計されており、ユーザーは異なる証明者に取引を送信する必要があり、異なるアプリケーションのZK-Rollupはそれぞれのデータと証明をL1に提出します。これにより、元のL1コントラクトの組み合わせ性が失われるという問題が生じます。
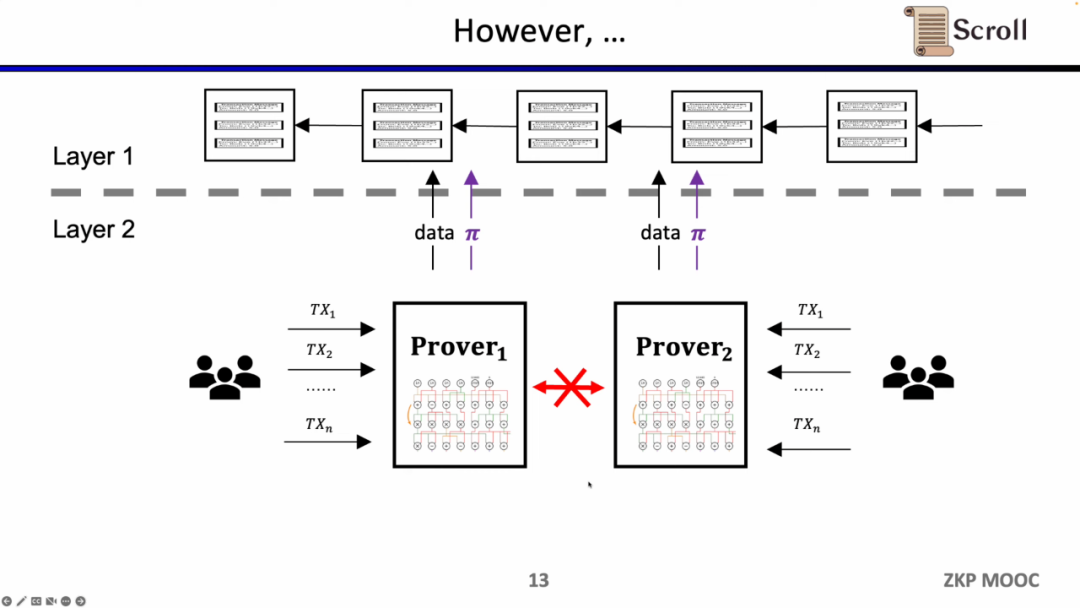
Scrollが目指しているのは、ネイティブなzkEVMソリューションであり、汎用のZK-Rollupです。これにより、ユーザーにとってより親しみやすく、開発者にとってもL1での開発体験を得ることができます。もちろん、これには非常に大きな開発の難しさが伴い、現在の証明生成のコストも非常に高いです。
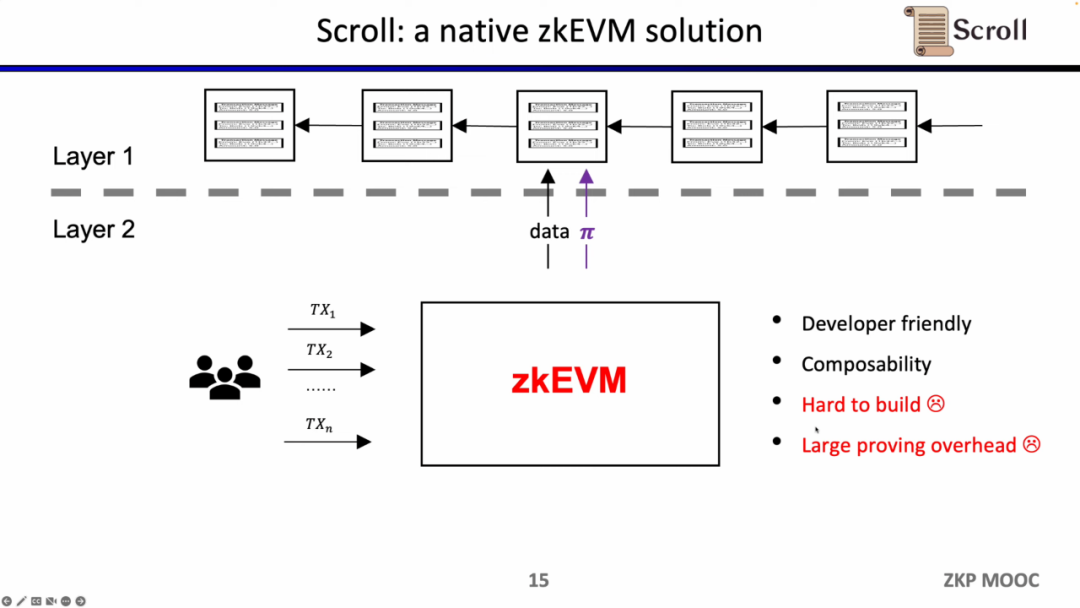
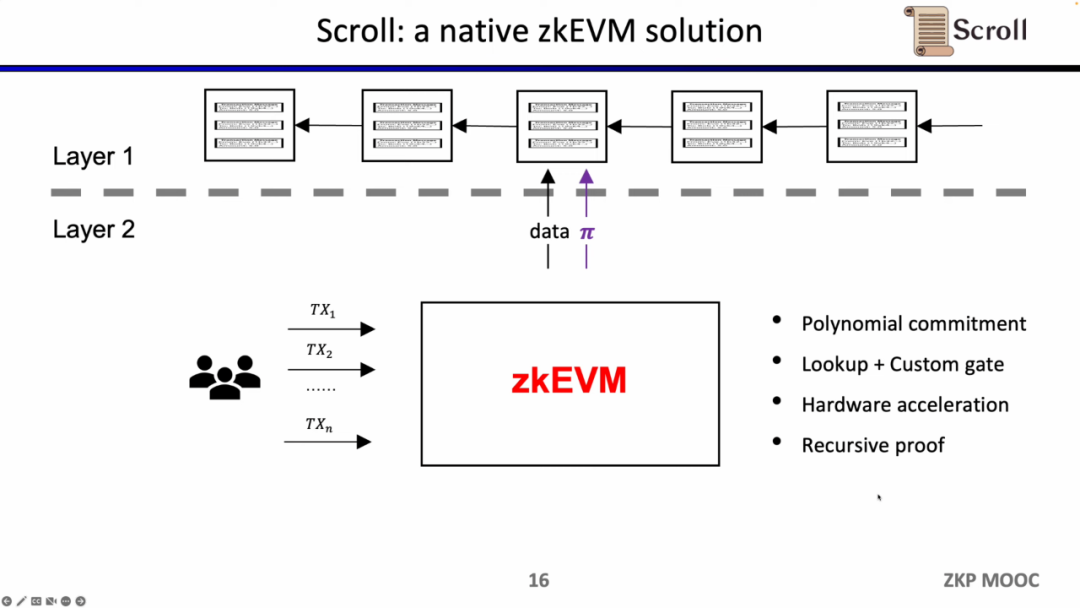
幸いなことに、ゼロ知識証明の効率は過去2年間で大幅に向上しており、これが最近の2年間でzkEVMがこれほど人気を博している理由です。少なくとも4つの理由がそれを実現可能にしています。第一は多項式コミットメントの出現で、従来のGroth16証明システムでは制約の規模が非常に大きかったのですが、多項式コミットメントはより高次の制約をサポートし、証明の規模を縮小できます。第二はルックアップテーブルとカスタムゲートの出現で、より柔軟な設計をサポートし、証明をより効率的にします。第三はハードウェアアクセラレーションの突破で、GPU、FPGA、ASICを使用することで証明時間を1〜2桁短縮できます。第四は再帰的証明により、複数の証明を1つの証明に圧縮でき、証明が小さく、検証が容易になります。これらの4つの要素を組み合わせることで、ゼロ知識証明の生成効率は2年前よりも3桁向上しており、これがScrollの起源です。
Justin Drakeの定義によれば、zkEVMは3つのカテゴリに分けられます。第一のカテゴリは言語レベルの互換性で、主な理由はEVMがZK向けに設計されていないため、ZKに不利なオペコードが多く、これが大量の追加コストを引き起こすからです。そのため、StarkwareやzkSyncはSolidityやYulをZKに優しいコンパイラにコンパイルすることを選択しています。
第二のカテゴリは、Scrollが行っているバイトコードレベルの互換性で、EVMのバイトコード処理が正しいかどうかを直接証明し、イーサリアムの実行環境を直接継承します。ここでの妥協点は、EVMとは異なる状態ルートを使用すること、たとえばZKに優しいデータ構造を使用することです。HermezとConsensysも同様のことを行っています。
第三のカテゴリはコンセンサスレベルの互換性で、ここでの妥協点はEVMを変更しないだけでなく、ストレージ構造なども含めてイーサリアムと完全に互換性を持たせる必要があり、その代償として証明時間が長くなることです。Scrollはイーサリアム財団のPSEチームと協力して、イーサリアムのZK化を実現するために取り組んでいます。

0から1までのzkEVMの構築

第二部では、張烨がゼロからZKVMを構築する方法を示しました。
完全なプロセス
まず、ZKPのフロントエンド部分では、計算を数学的に算術化する必要があります。最も一般的なのは線形のR1CS、Plonkish、AIRです。算術化によって制約を得た後、ZKPのバックエンドでは証明アルゴリズムを実行して計算の正当性を証明する必要があります。ここでは最も一般的な多項式対話的証明(Polynomial IOP)と多項式コミットメントスキーム(PCS)を挙げます。
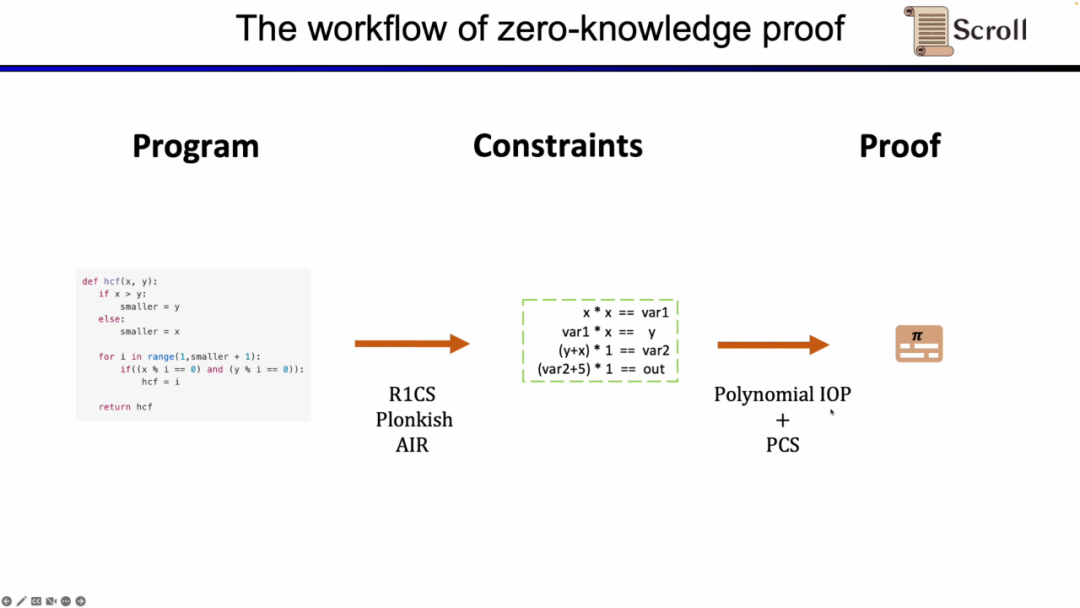
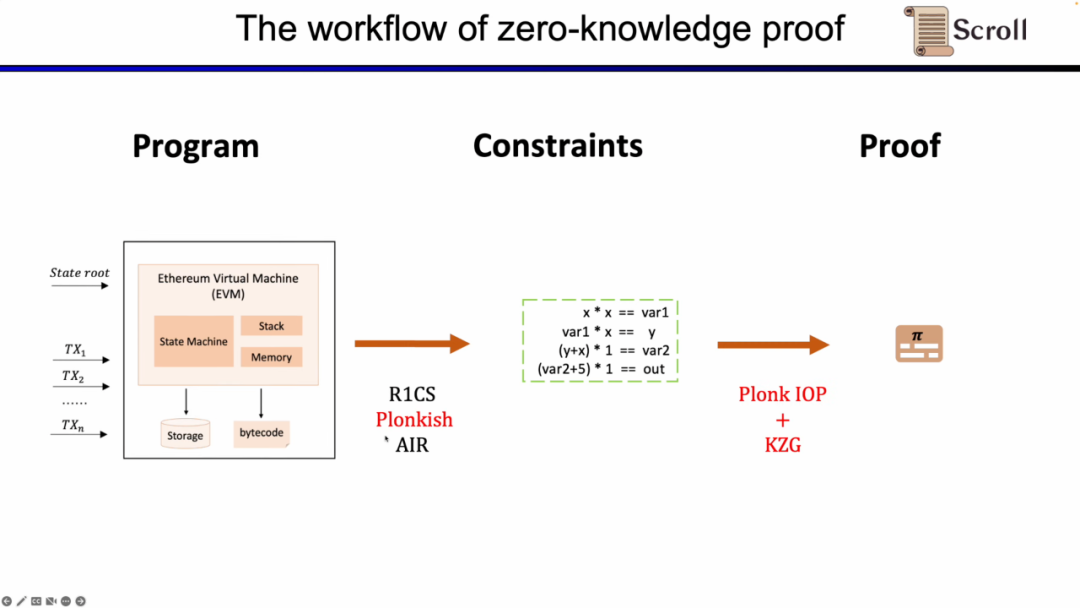
ここでzkEVMを証明する必要があります。Scrollが使用しているのはPlonkish、Plonk IOP、KZGの組み合わせです。
なぜこの3つのスキームを使用するのかを理解するために、最も単純なR1CSから始めます。R1CSの制約は、線形の組み合わせが線形の組み合わせに等しいというものです。任意の変数の線形の組み合わせを追加することができますが、各制約の次数は最大2です。したがって、高次の演算にはより多くの制約が必要です。

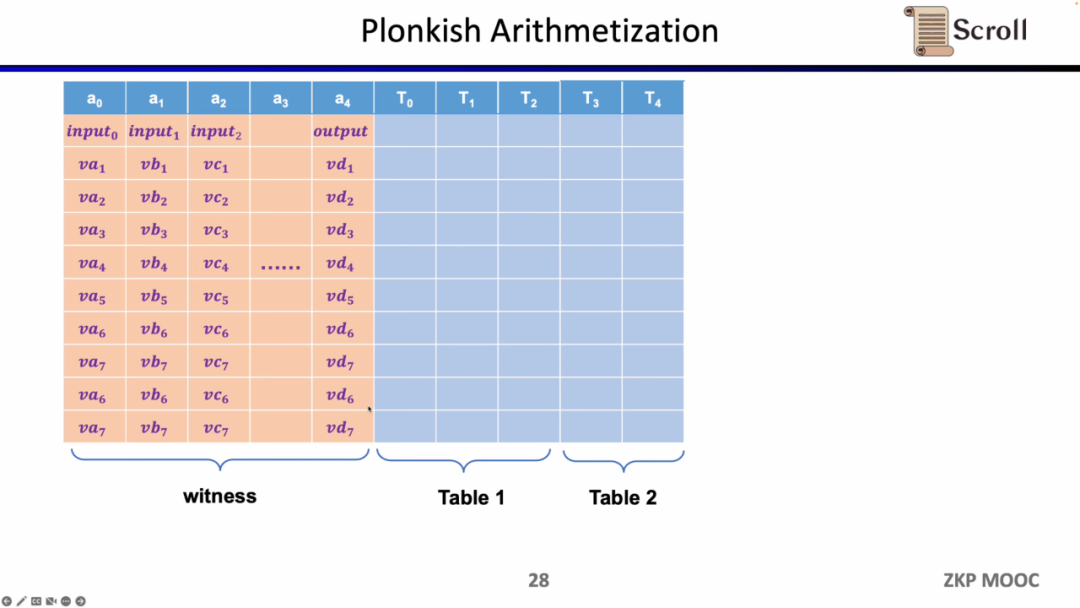
Plonkishでは、すべての変数をテーブルに入力する必要があります。入力、出力、中間変数の証明を含みます。その上で、異なる制約を定義できます。Plonkishでは、使用できる制約のタイプが3つあります。
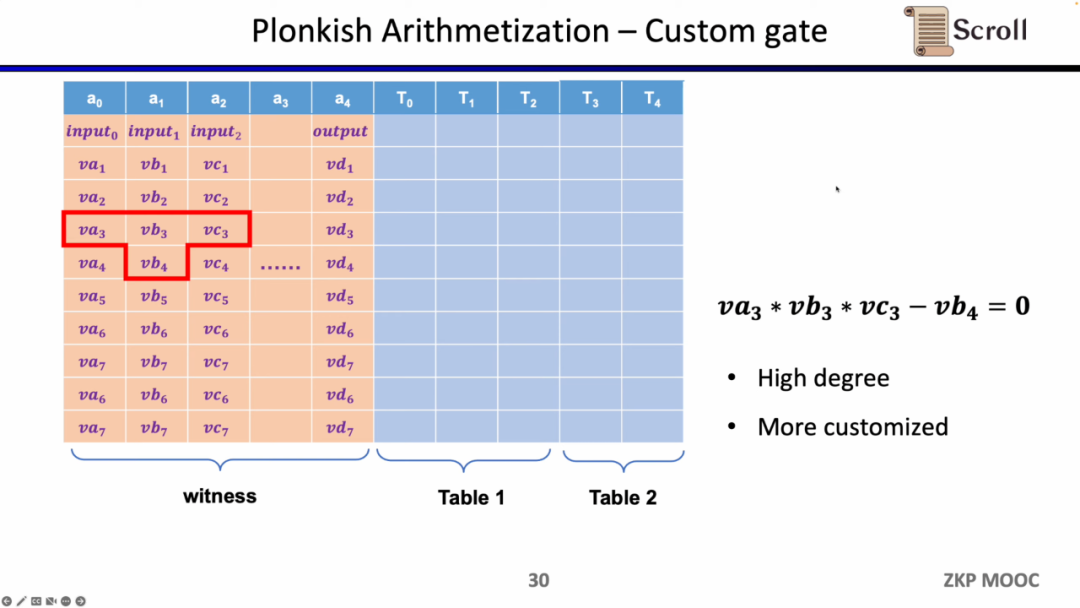
第一の制約はカスタムゲート(Custom Gate)で、異なるセル間の多項式制約関係を定義できます。たとえば、va3 * vb3 * vc3 - vb4 = 0です。R1CSと比較して、次数をより高くすることができ、任意の変数の制約を定義でき、非常に異なる制約を定義できます。
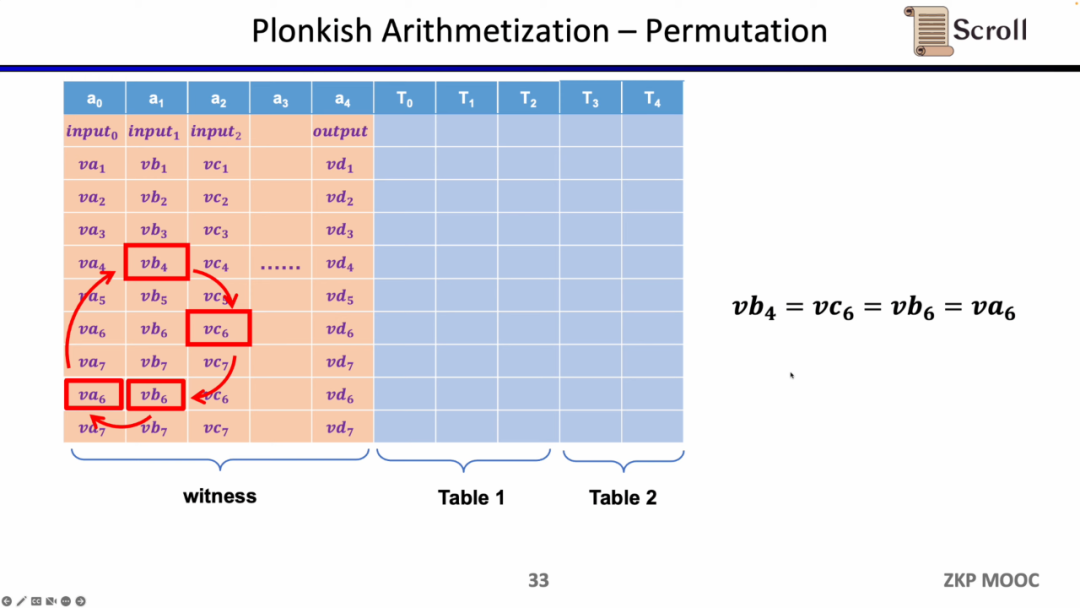
第二の制約はPermutation、すなわち等価性検証(equality checks)です。異なるセルの等価性をチェックするために使用され、関連回路の異なるゲートでよく使用されます。たとえば、前のゲートの出力が次のゲートの入力と等しいことを証明します。
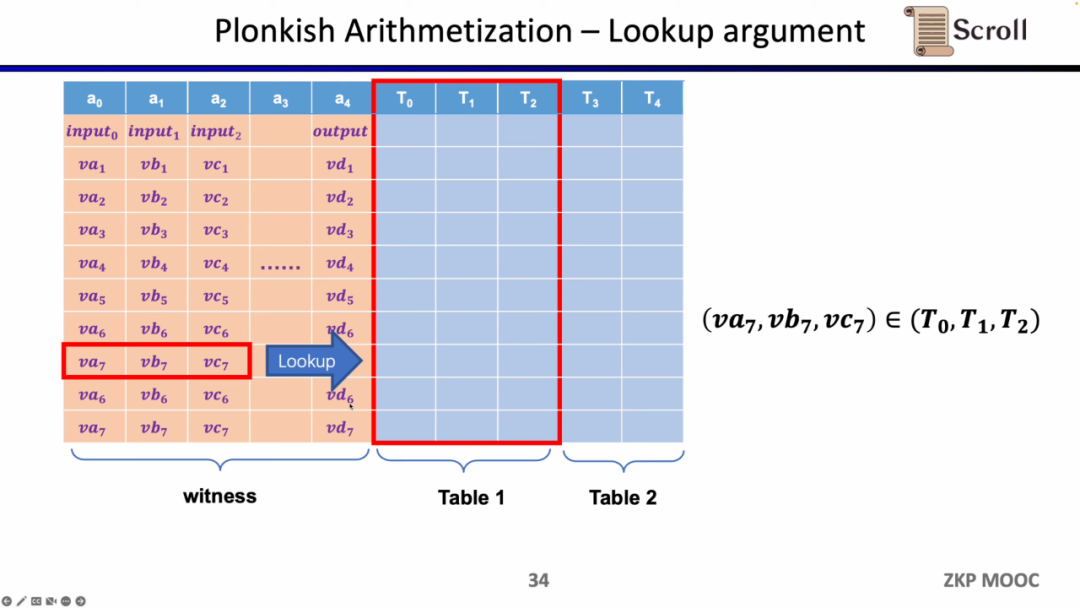
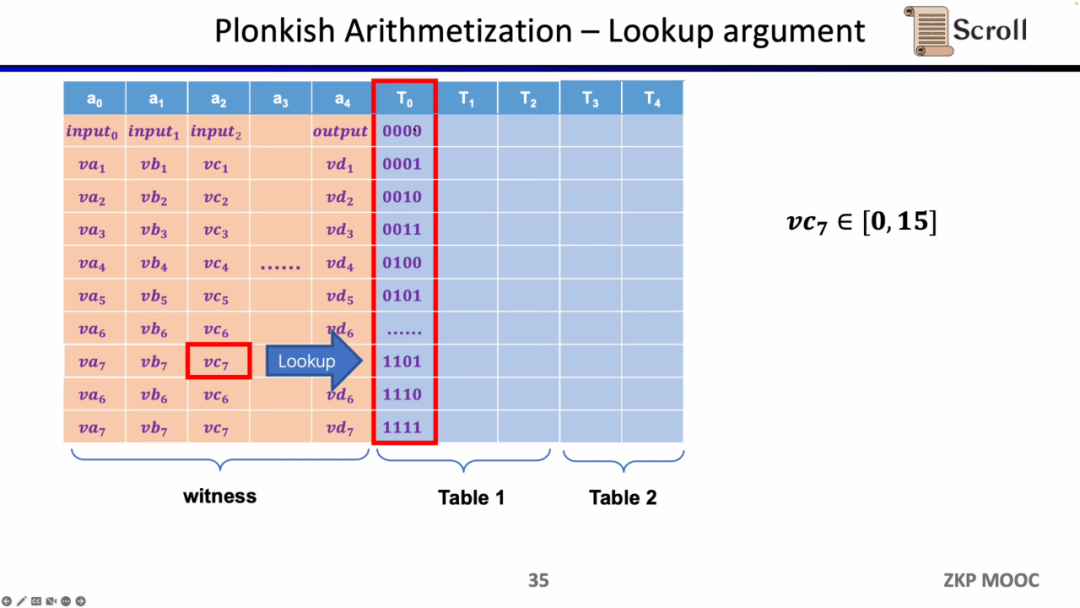
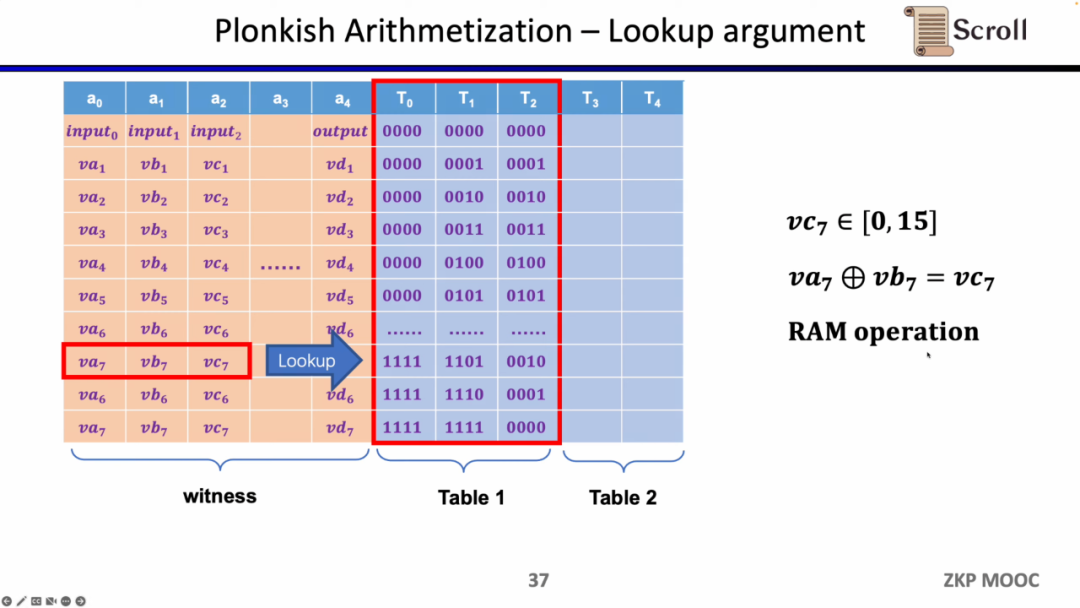
最後の制約はルックアップテーブル(Lookup Table)です。ルックアップテーブルは、変数間に関係が存在することを理解できます。その関係はテーブルとして表現できます。たとえば、vc7が0-15の範囲内にあることを証明したい場合、R1CSではまずこの数値を4ビットの二進数に分解し、各ビットが0-1の範囲内であることを証明する必要があります。これには4つの制約が必要です。しかし、Plonkishでは、すべての可能な範囲を同じ列に列挙し、vc7がその列に属することを証明するだけで済み、範囲証明に非常に効率的です。zkEVMでは、ルックアップテーブルはメモリの読み書きを証明するのに非常に役立ちます。
要約すると、Plonkishはカスタムゲート、等価性検証、ルックアップテーブルを同時にサポートし、さまざまな回路のニーズに非常に柔軟に対応できます。STARKと簡単に比較すると、STARKでは各行が1つの制約であり、制約は行と行の間の状態遷移を表す必要がありますが、Plonkishのカスタム制約の柔軟性は明らかに高いです。
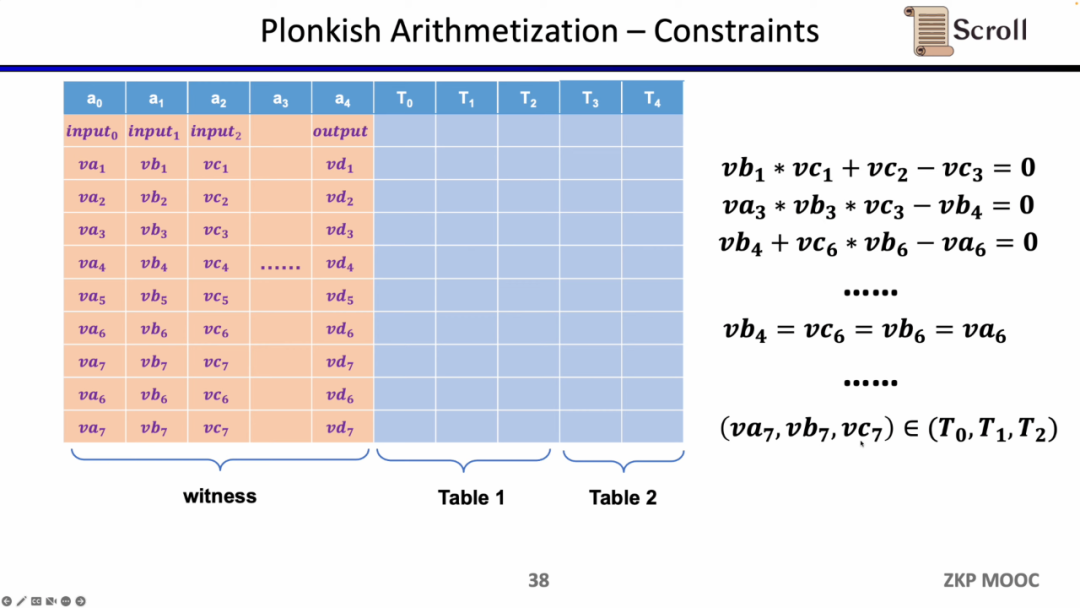
現在の問題は、zkEVMでフロントエンドをどのように選択するかです。zkEVMには主に4つの課題があります。第一の課題はEVMのフィールドが256ビットであるため、変数に対して効率的に範囲制約を行う必要があることです。第二の課題はEVMには多くのZKに不利なオペコードがあり、これらのオペコードを証明するために非常に大規模な制約が必要であることです。たとえば、Keccak-256です。第三の課題はメモリの読み書きの問題で、読み取ったものと以前に書き込んだものが一致することを証明するために、いくつかの有効なマッピングが必要です。第四の課題はEVMの実行トレースが動的に変化するため、異なる実行トレースに適応するためにカスタムゲートが必要であることです。これらの理由から、Plonkishを選択しました。
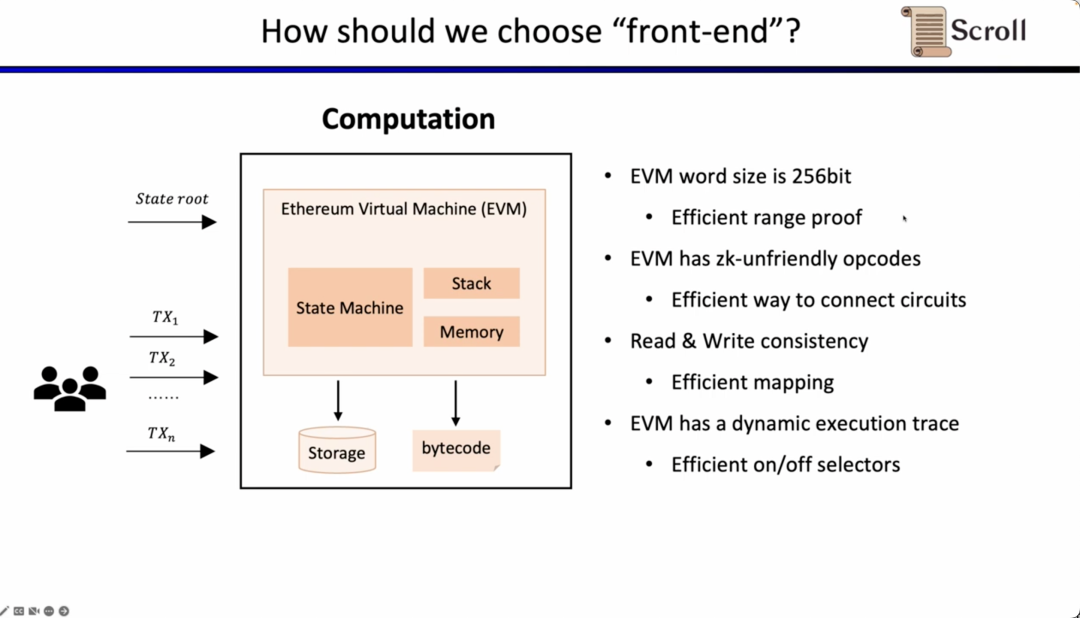
次に、zkEVMの完全なプロセスを見ていきます。初期のグローバル状態ツリーに基づいて、新しい取引が入ると、EVMはストレージと呼び出しコントラクトのバイトコードを読み取り、取引に基づいてPUSH、PUSH、STORE、CALLVALUEなどの実行トレースを生成し、グローバル状態を段階的に更新して取引後のグローバル状態ツリーを得ます。そして、zkEVMは初期のグローバル状態ツリー、取引自体、および取引後のグローバル状態ツリーを入力として、EVMの規範に従って実行トレースの実行の正当性を証明します。
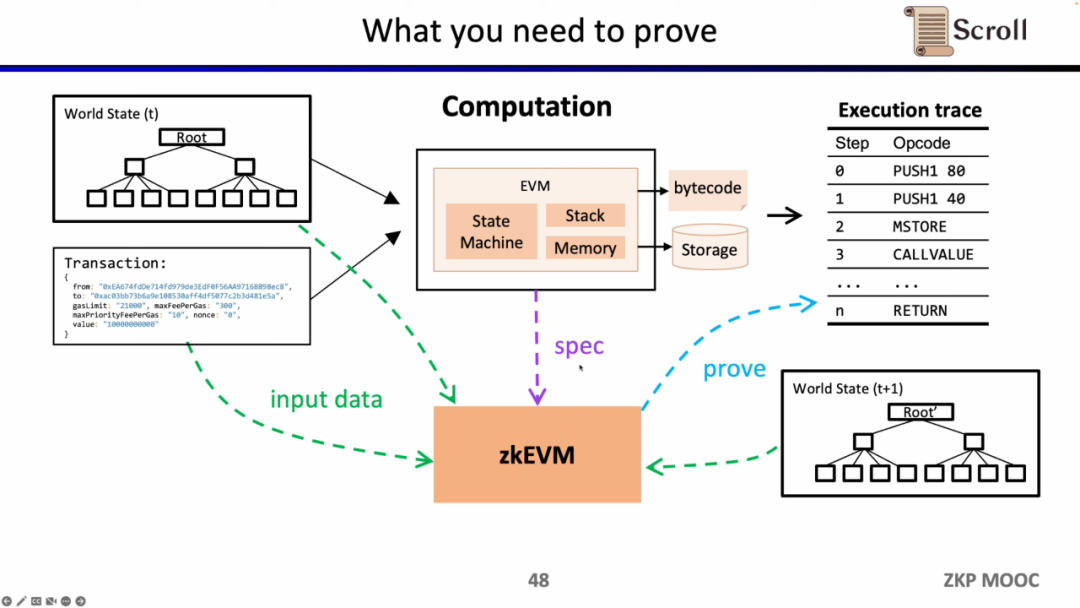
EVM回路の詳細に深く入り込むと、各実行トレースには対応する回路制約があります。具体的には、各ステップの回路制約にはStep Context、Case Switch、Opcode Specific Witnessが含まれます。Step Contextには実行トレースに対応するcodehash、残りのガス、カウンターが含まれます。Case Switchにはすべてのオペコード、すべてのエラーケース、およびそのステップの対応する操作が含まれます。Opcode Specific Witnessにはオペコードに必要な追加の証明が含まれます。たとえば、オペランドなどです。
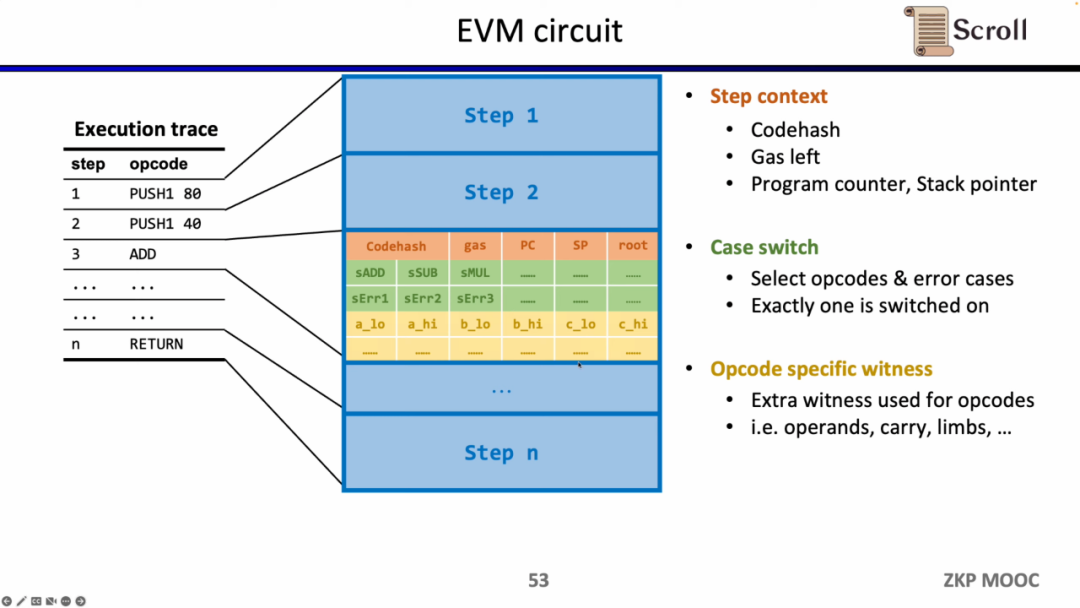
簡単な加算の例を挙げると、加算のオペコードの制御変数sADDが1に設定され、他のオペコードの制御変数はすべてゼロであることを確認する必要があります。Step Contextでは、gas' - gas - 3 = 0を設定することで消費されたガスが3であることを制約し、同様にカウンターを制約し、スタックポインタはこのステップの後に1加算されます。Case Switchでは、オペコードの制御変数の合計が1であることを制約して、このステップが加算操作であることを示します。Opcode Specific Witnessでは、オペランドの実際の加算を制約します。
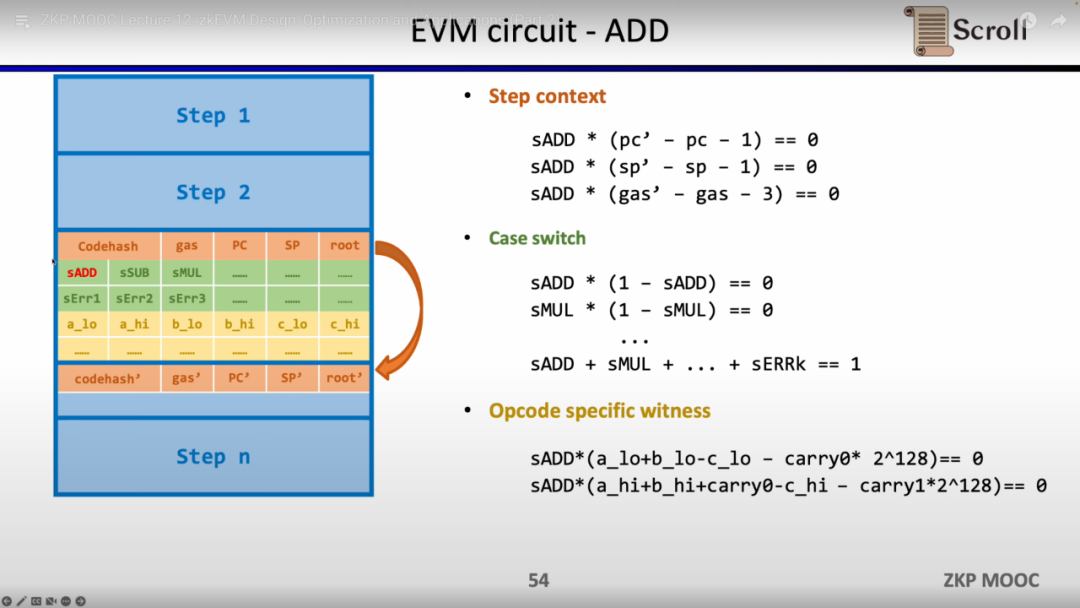
さらに、オペランドがメモリから正しく読み取られることを保証するために、追加の回路制約が必要です。ここでは、まずオペランドがメモリに属することを証明するためのルックアップテーブルを構築する必要があります。そして、メモリ回路(RAM Circuit)を使用してメモリテーブルの正当性を検証します。
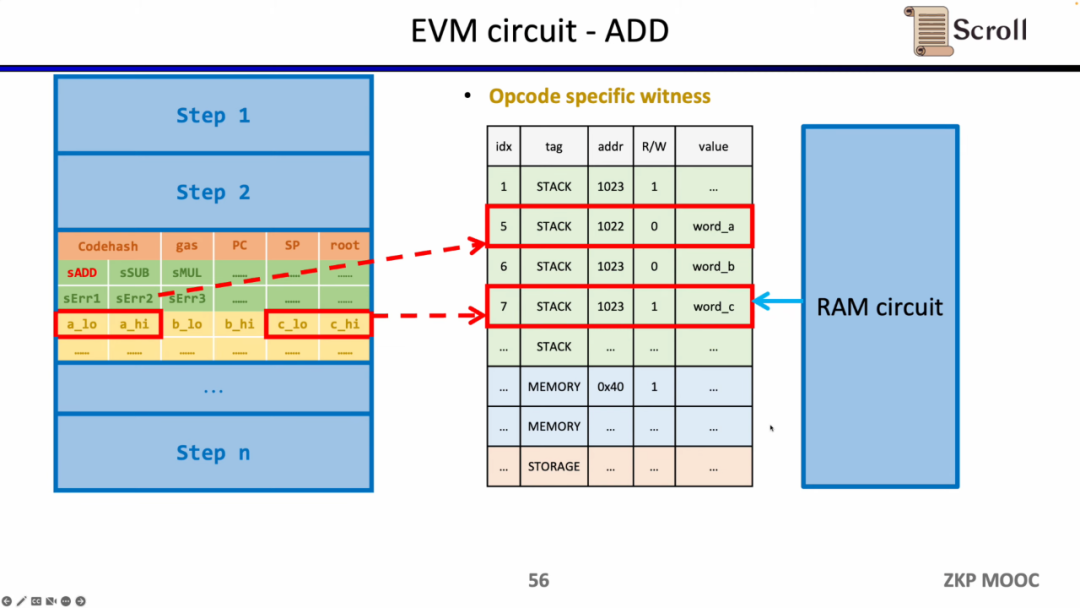
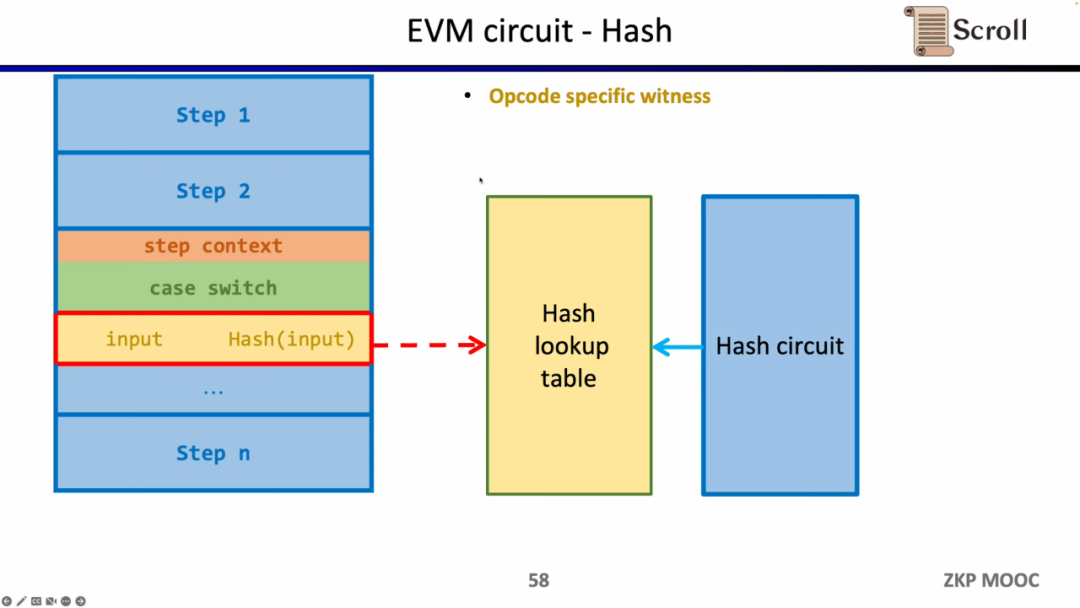
同様の方法はZKに不利なハッシュ関数にも適用でき、ハッシュ関数のルックアップテーブルを構築し、実行トレース内のハッシュ入力と出力をルックアップテーブルにマッピングし、追加のハッシュ回路(Hash Circuit)を利用してハッシュルックアップテーブルの正当性を検証します。
現在、zkEVMの回路アーキテクチャを見てみましょう。コアのEVM回路は、実行トレースの各ステップの正当性を制約するために使用されます。いくつかのEVM回路制約が難しい場所では、ルックアップテーブルを使用してマッピングします。これにはFixed Table、Keccak Table、RAM Table、Bytecode、Transaction、Block Contextが含まれ、これらのルックアップテーブルを制約するために個別の回路を利用します。たとえば、Keccak回路はKeccakテーブルを制約するために使用されます。
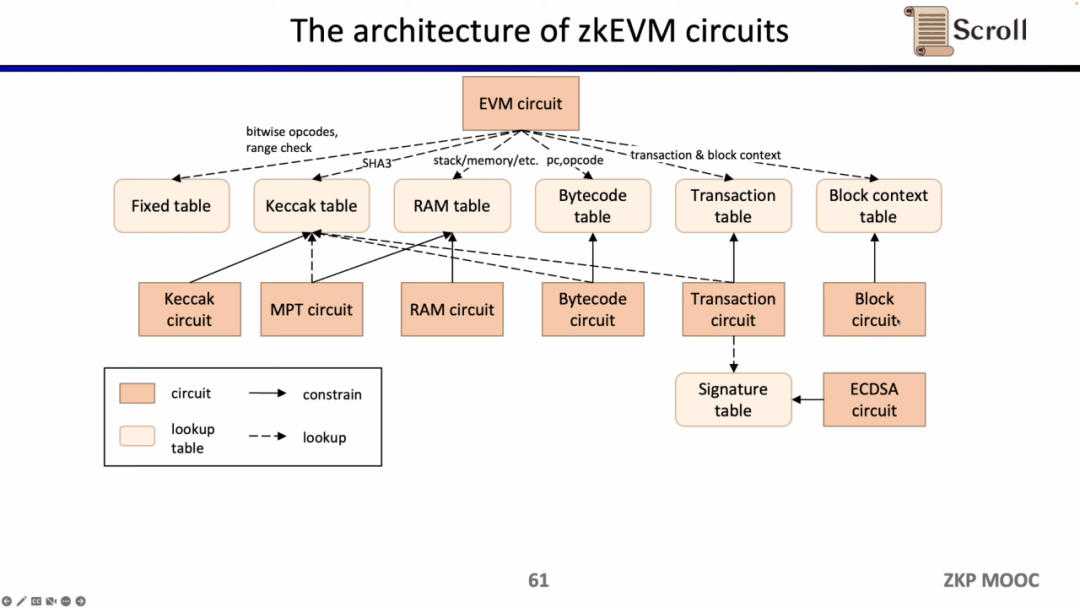
要約すると、zkEVMの完全なワークフローは以下の図のようになります。
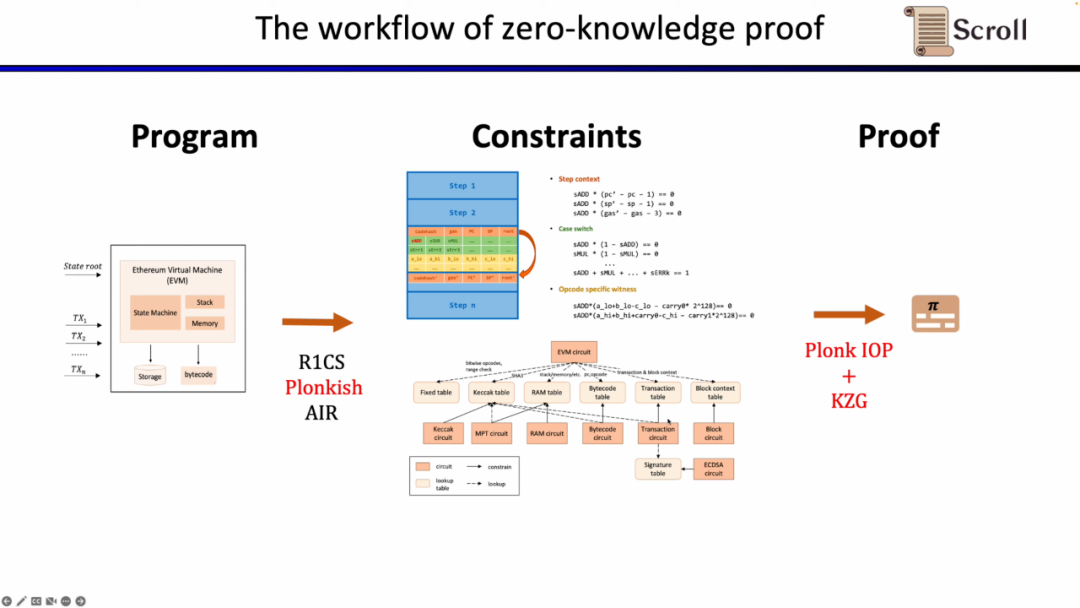
証明システム
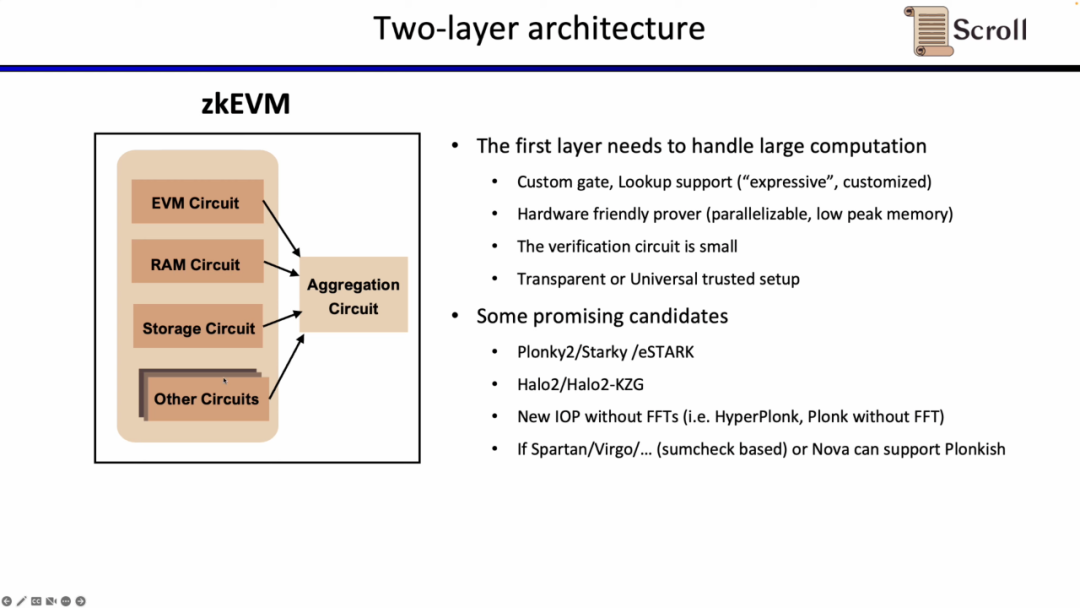
L1上で上記のEVM回路、メモリ回路、ストレージ回路などを直接検証することはコストが非常に高いため、Scrollの証明システムは二層アーキテクチャを採用しています。
第一層はEVM自体を直接証明する役割を担い、大量の計算を必要とします。したがって、第一層の証明システムはカスタムゲートとルックアップテーブルをサポートし、ハードウェアアクセラレーションに優れ、低ピークメモリで並行して計算を生成し、検証回路の規模が小さく、迅速に検証できる必要があります。有望な選択肢にはPlonky2、Starky、eSTARKがあり、これらのフロントエンドは基本的にPlonkを使用していますが、バックエンドではFRIを使用しており、上記の4つの特性を満たしています。もう一つの選択肢には、Zcashが開発したHalo2やKZGバージョンのHalo2があります。
最近、FFTを除去したHyperPlonkや、より小さな再帰的証明を実現できるNOVA証明システムなどの新しい証明システムも非常に有望です。しかし、これらは研究段階でR1CSのみをサポートしており、将来的にPlonkishをサポートし、実践に応用できれば非常に実用的で効率的です。
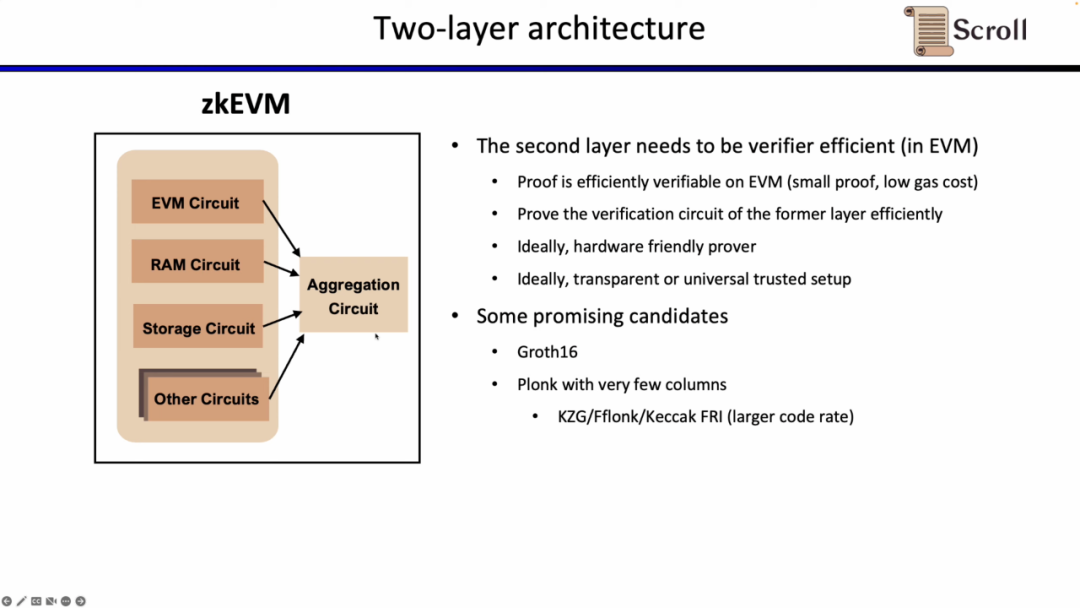
第二層の証明システムは、第一層の証明の正当性を証明するために使用され、EVM内で効率的に検証できる必要があります。理想的には、ハードウェアアクセラレーションに優れ、透明またはユニバーサルセットアップをサポートすることが望ましいです。有望な選択肢にはGroth16と列数が少ないPlonkish証明システムがあります。Groth16は現在の研究において証明効率が非常に高い代表的なものであり、Plonkish証明システムは列数が少ない場合でも高い証明効率を達成できます。
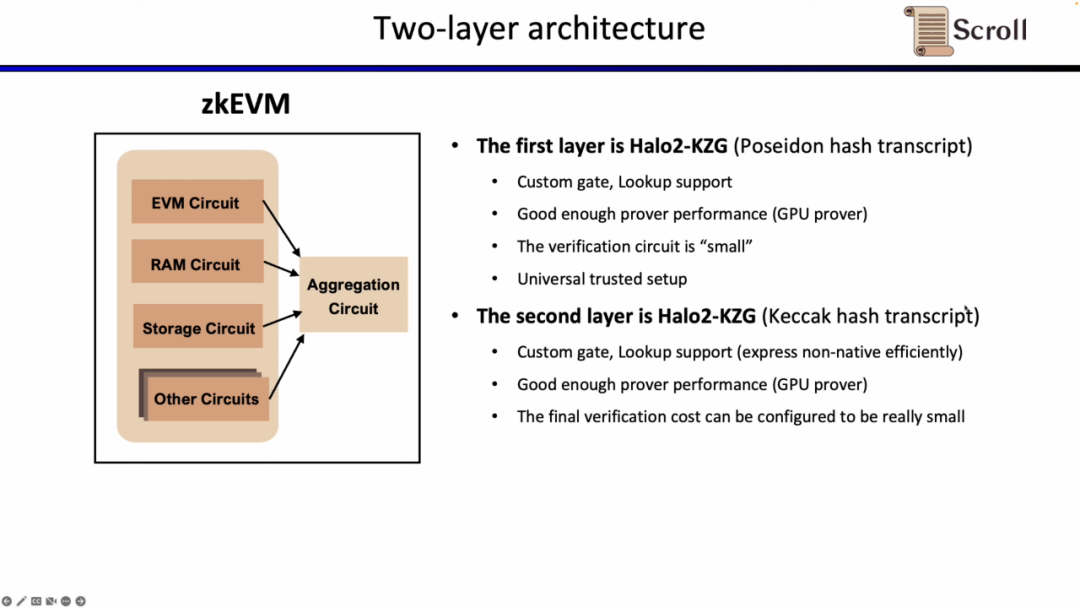
Scrollでは、二層の証明システムの両方にHalo2-KZG証明システムを採用しています。Halo2-KZGはカスタムゲートとルックアップテーブルをサポートし、GPUハードウェアアクセラレーション下で良好な性能を発揮し、検証回路の規模が小さく、迅速に検証できます。違いは、第一層の証明システムではPoseidonハッシュを使用して証明効率をさらに向上させ、第二層の証明システムではイーサリアム上で直接検証するため、依然としてKeccakハッシュを使用している点です。Scrollはまた、第二層の証明システムが生成する集約証明をさらに集約するための多層証明システムの可能性を探求しています。
現在の実装では、Scrollの第一層証明システムのEVM回路は116列、2496のカスタムゲート、50のルックアップテーブル、最大次数は9で、1Mガスで2^18行が必要です。一方、第二層の証明システムの集約回路はわずか23列、1つのカスタムゲート、7つのルックアップテーブル、最大次数は5で、EVM回路、メモリ回路、ストレージ回路を集約するためには2^25行が必要です。

ScrollはGPUハードウェアアクセラレーションに関しても多くの研究と最適化を行っており、EVM回路に対して最適化されたGPU証明者はわずか30秒で済み、CPU証明者と比較して9倍の効率向上を実現しました。また、集約回路に対して最適化されたGPU証明者は149秒で済み、CPUに対して15倍の効率向上を実現しました。現在の最適化条件下で、1Mガスの第一層証明システムは約2分、第二層証明システムは約3分を要します。

興味深い研究課題

第三部では、張烨がScrollがzkEVMを構築する過程で直面した興味深い研究課題について、フロントエンドの算術化回路から証明者の実装までを語りました。
回路
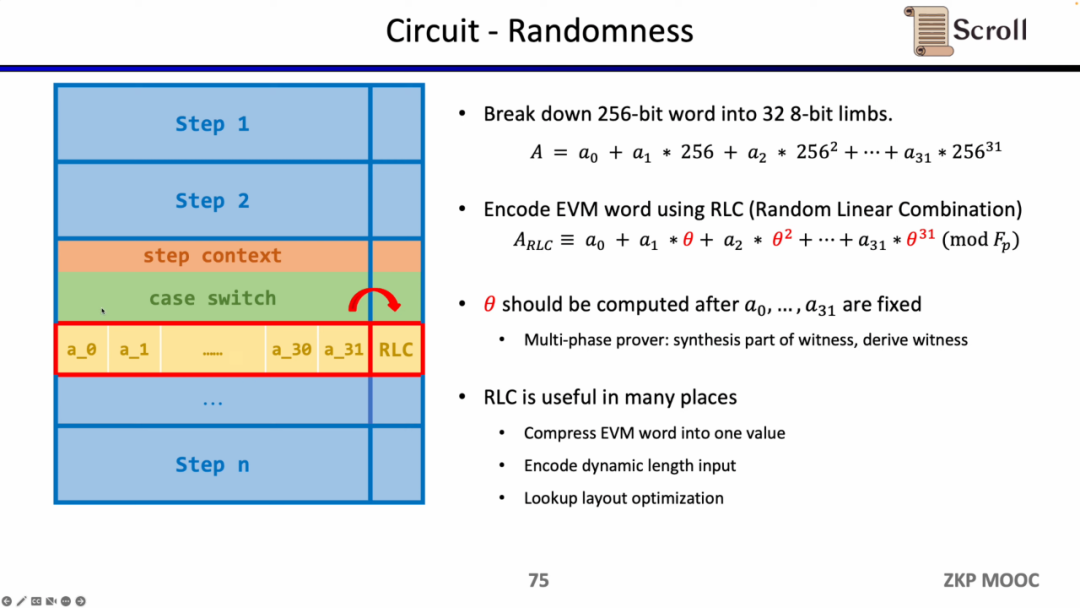
まず、回路内のランダム性についてです。EVMフィールドが256ビットであるため、これを32の8ビットフィールドに分割し、より効率的に範囲証明を行う必要があります。その後、ランダム線形組み合わせ(Random Linear Combination, RLC)法を使用して、32のフィールドを1つにエンコードし、そのフィールドを検証することで元の256ビットフィールドを検証できます。しかし、問題はランダム数の生成がフィールドを分割した後でなければならず、改ざんされないことを保証する必要があることです。
そのため、ScrollとPSEチームは多段階証明者のスキームを提案し、フィールドを分割した後にRLCを生成するためにランダム数を利用することを確保しました。このスキームはChallenge APIにカプセル化されています。RLCはzkEVM内で多くのアプリケーションシーンがあり、EVMフィールドを1つのフィールドに圧縮するだけでなく、可変長の入力を暗号化したり、ルックアップテーブルのレイアウトを最適化したりすることができますが、まだ解決すべき多くのオープンな問題があります。
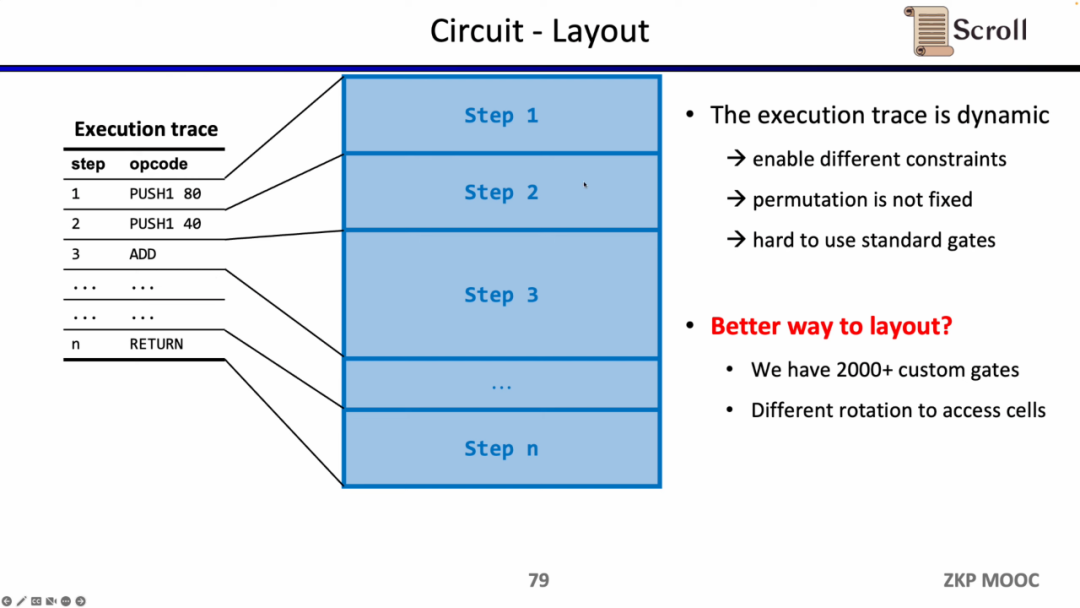
回路に関する第二の興味深い研究課題は回路レイアウトです。ScrollのフロントエンドがPlonkishを採用している理由は、EVMの実行トレースが動的に変化するため、異なる制約や変化する等価性検証をサポートする必要があるからです。一方、R1CSの標準化されたゲートは、より大きな回路規模を必要とします。
しかし、Scrollは現在2000以上のカスタムゲートを使用して動的に変化する実行トレースを満たしており、Opcodeをマイクロオペコードに分割したり、同じテーブル内のセルを再利用したりする方法をさらに最適化することを探求しています。
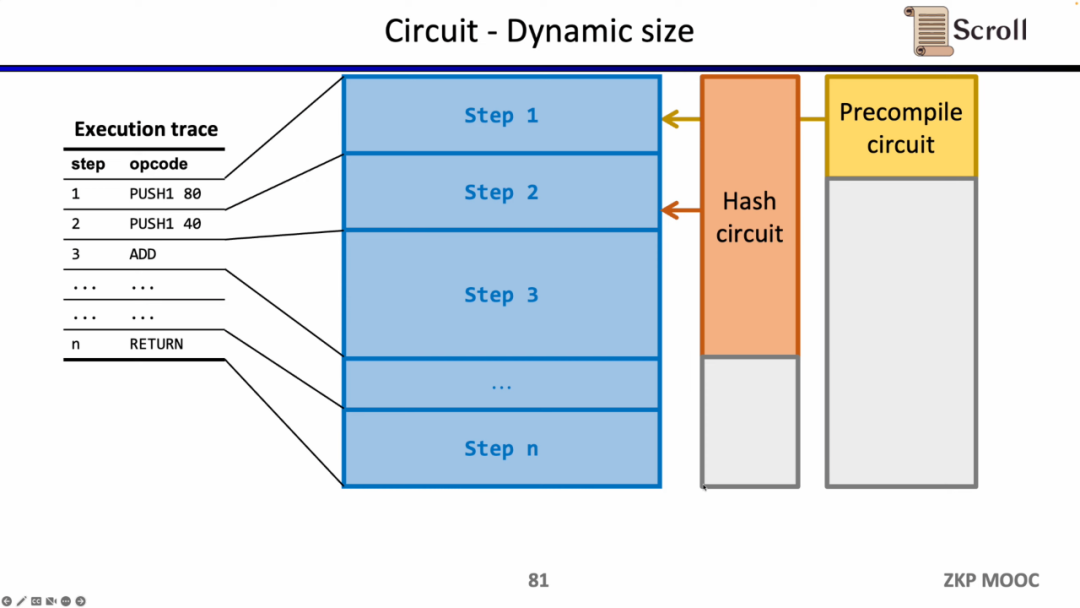
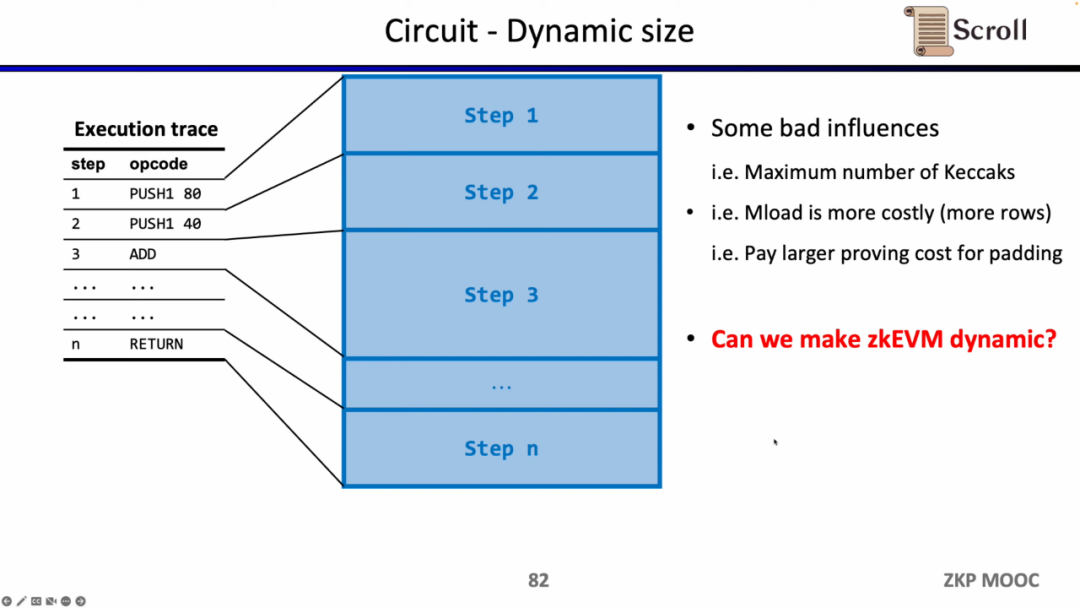
回路に関する第三の興味深い研究課題は動的規模です。異なるオペコードの回路規模は異なりますが、動的に変化する実行トレースを満たすために、各ステップのオペコードは最大の回路規模を満たす必要があります。たとえば、Keccakハッシュです。したがって、実際には追加のコストが発生しています。もしzkEVMが動的に変化する実行トレースに適応できるなら、不要なコストを節約できます。
証明者
証明者に関して、ScrollはGPUアクセラレーションにおいてMSMとNTTの最適化を多数行っていますが、現在のボトルネックは証明生成とデータのコピーに移っています。MSMとNTTが証明時間の80%を占めると仮定すると、ハードウェアアクセラレーションがこの部分の効率を数桁向上させても、元々証明時間の20%を占めていた証明生成とデータコピーが新たなボトルネックとなります。証明者のもう一つの問題は、大量のメモリが必要であるため、より安価で分散化されたハードウェアソリューションを探求する必要があります。
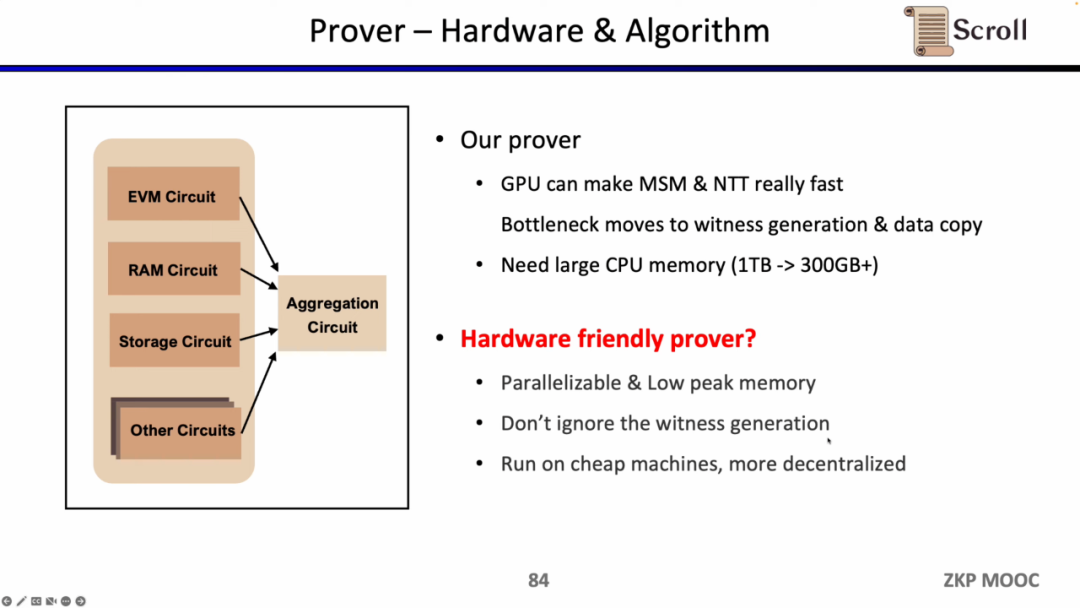
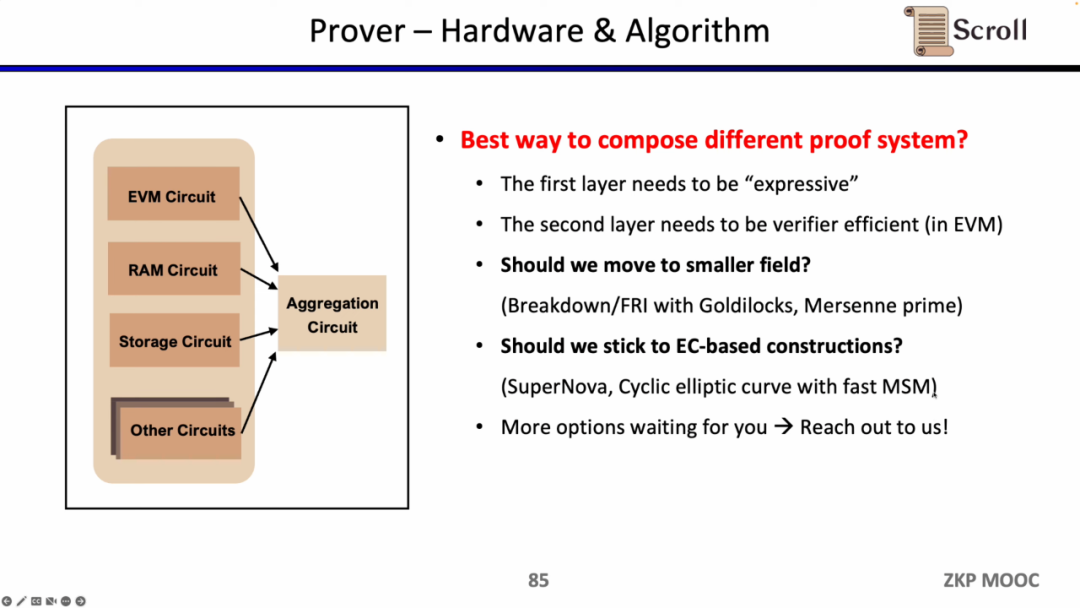
同時に、Scrollはハードウェアアクセラレーションと証明アルゴリズムの面でも、証明者の効率を向上させるための探求を行っています。現在、主に2つの大きな方向性があります。1つは、64ビットのGoldilocksフィールドや32ビットのメルセンヌ素数(Mersenne Prime)など、より小さなドメインに切り替えることです。もう1つは、楕円曲線(EC)に基づく新しい証明システム、たとえばSuperNovaを維持することです。もちろん、他にもいくつかの可能性のある道がありますので、アイデアのある方は直接Scrollにご連絡ください。
セキュリティ
zkEVMを構築する際、セキュリティは非常に重要です。PSEとScrollが共同で構築したzkEVMは約34,000行のコードを含んでおり、ソフトウェア工学の観点から、これらの複雑なコードベースには長い間脆弱性がないとは限りません。Scrollは現在、業界で最も優れた監査会社を含む多数の監査を通じて、zkEVMのコードベースを監査しています。


他のzkEVMを使用したアプリケーション

第四部では、他のいくつかのzkEVMを使用したアプリケーションについて探討しました。
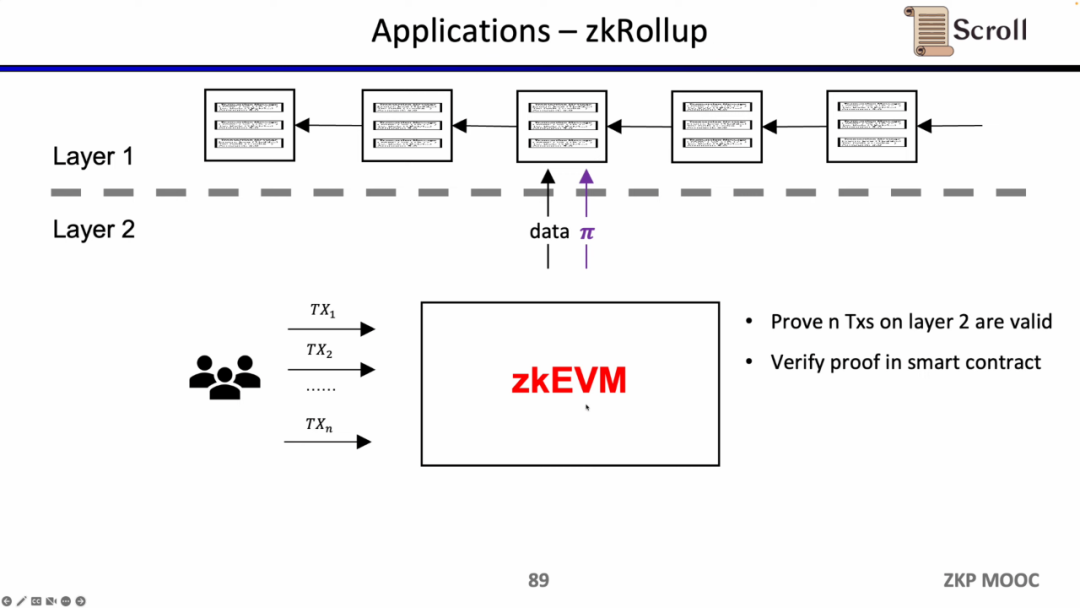
zkRollupのアーキテクチャでは、L1のスマートコントラクトを通じて、L2上のn件の取引が有効であることを検証します。
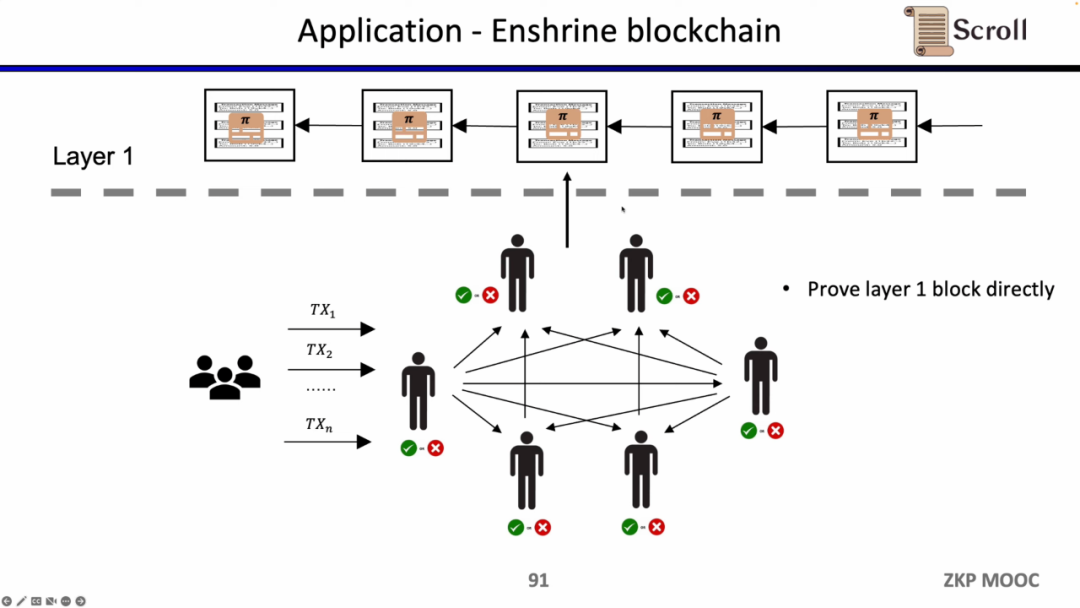
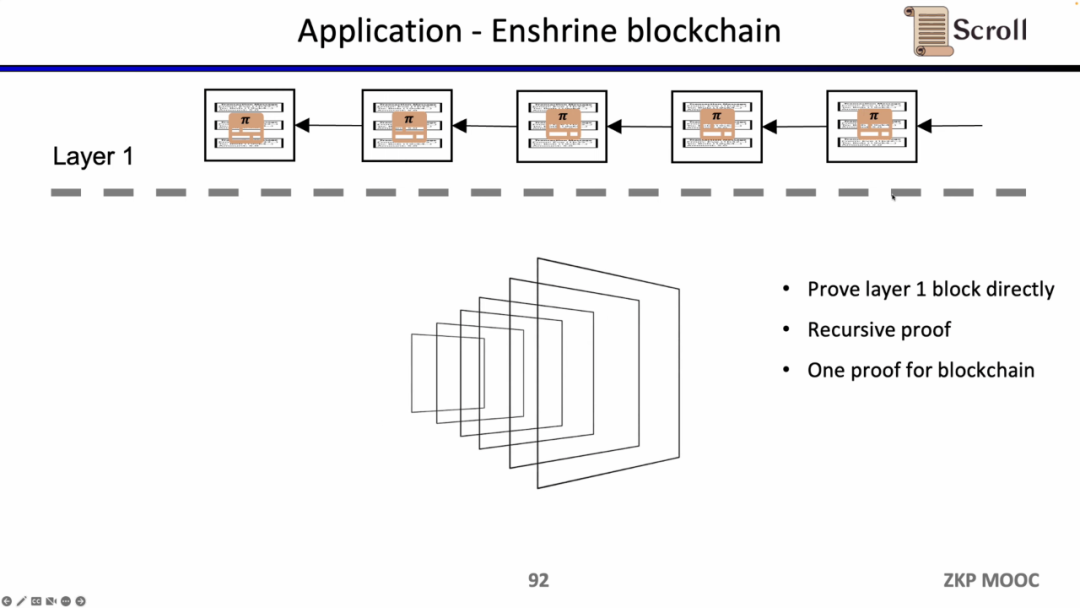
もしL1のブロックを直接検証するなら、L1のノードは取引を再実行する必要はなく、各ブロックの証明の有効性を検証するだけで済みます。このようなアーキテクチャのスキームをEnshrine Blockchainと呼びます。現在、イーサリアム上で直接実装することは非常に難しいです。なぜなら、イーサリアムの全ブロックを検証する必要があり、その中には大量の署名の検証が含まれ、結果としてより長い証明時間と低いセキュリティがもたらされるからです。もちろん、Minaのように再帰的証明を使用して、単一の証明でブロックチェーン全体を検証する他の公的ブロックチェーンもすでに存在します。
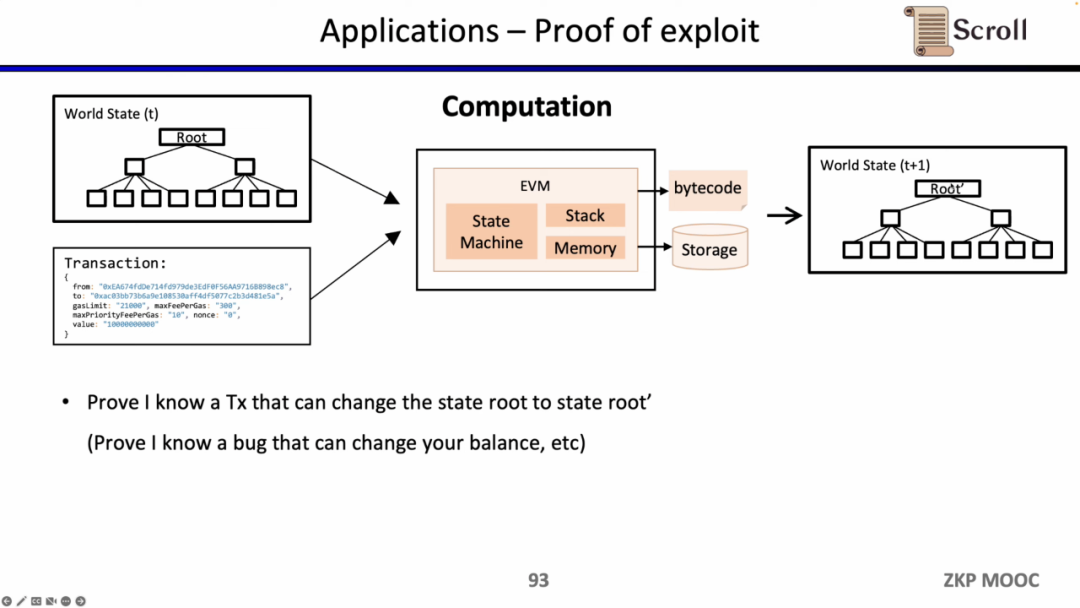
zkEVMは状態遷移を証明できるため、ホワイトハットによって利用され、特定のスマートコントラクトの脆弱性を知っていることを証明し、プロジェクト側に報酬を求めることができます。
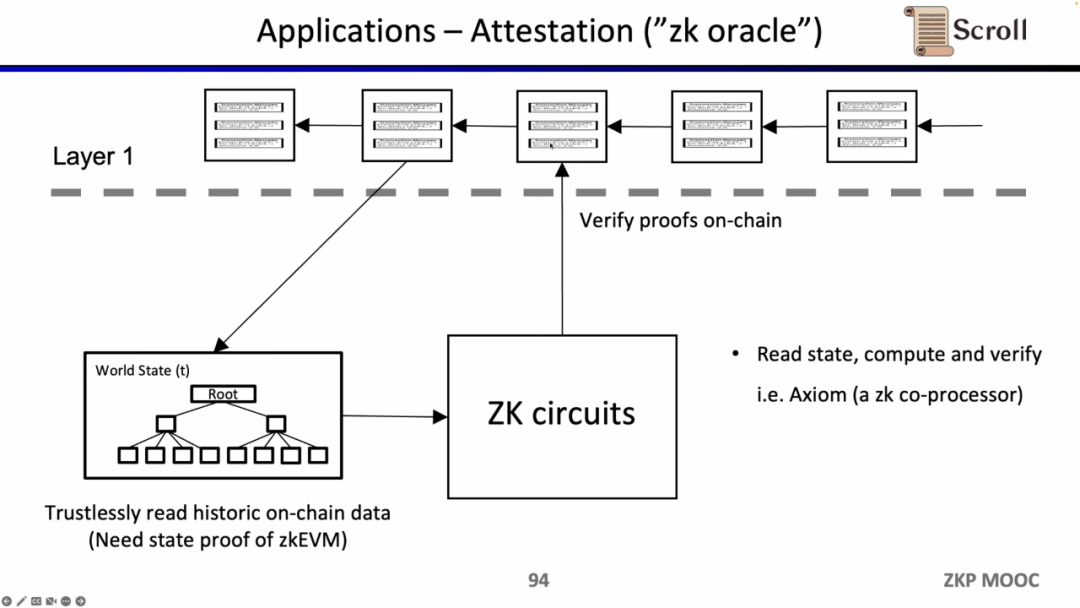
最後のユースケースは、ゼロ知識証明を通じて過去のデータに関する声明を証明し、オラクルとして使用することです。現在、Axiomがこの分野の製品を開発しています。最近のETHBeijingハッカソンでは、GasLockRチームがこの特性を利用して、過去のGasコストを証明しました。
最後に、ScrollはzkRollupのイーサリアム汎用スケーリングソリューションを構築しており、非常に先進的な算術化回路と証明システムを使用し、ハードウェアアクセラレーションを通じて迅速な検証者を構築し、証明の再帰を実現しています。現在、Alphaテストネットはすでにオンラインで、長期間安定して稼働しています。
もちろん、プロトコル設計やメカニズム設計、ゼロ知識エンジニアリングや実際の効率など、解決すべき興味深い問題がまだいくつかあります。皆さんもScrollに参加して、一緒に構築しましょう!

Scroll
Website: https://scroll.io/
Twitter: https://twitter.com/Scroll_ZKP
Discord:https://discord.com/invite/scroll
Github: https://github.com/scroll-tech
Youtube: https://www.youtube.com/@Scroll_ZKP
 リスク警告
リスク警告 リスク警告
リスク警告