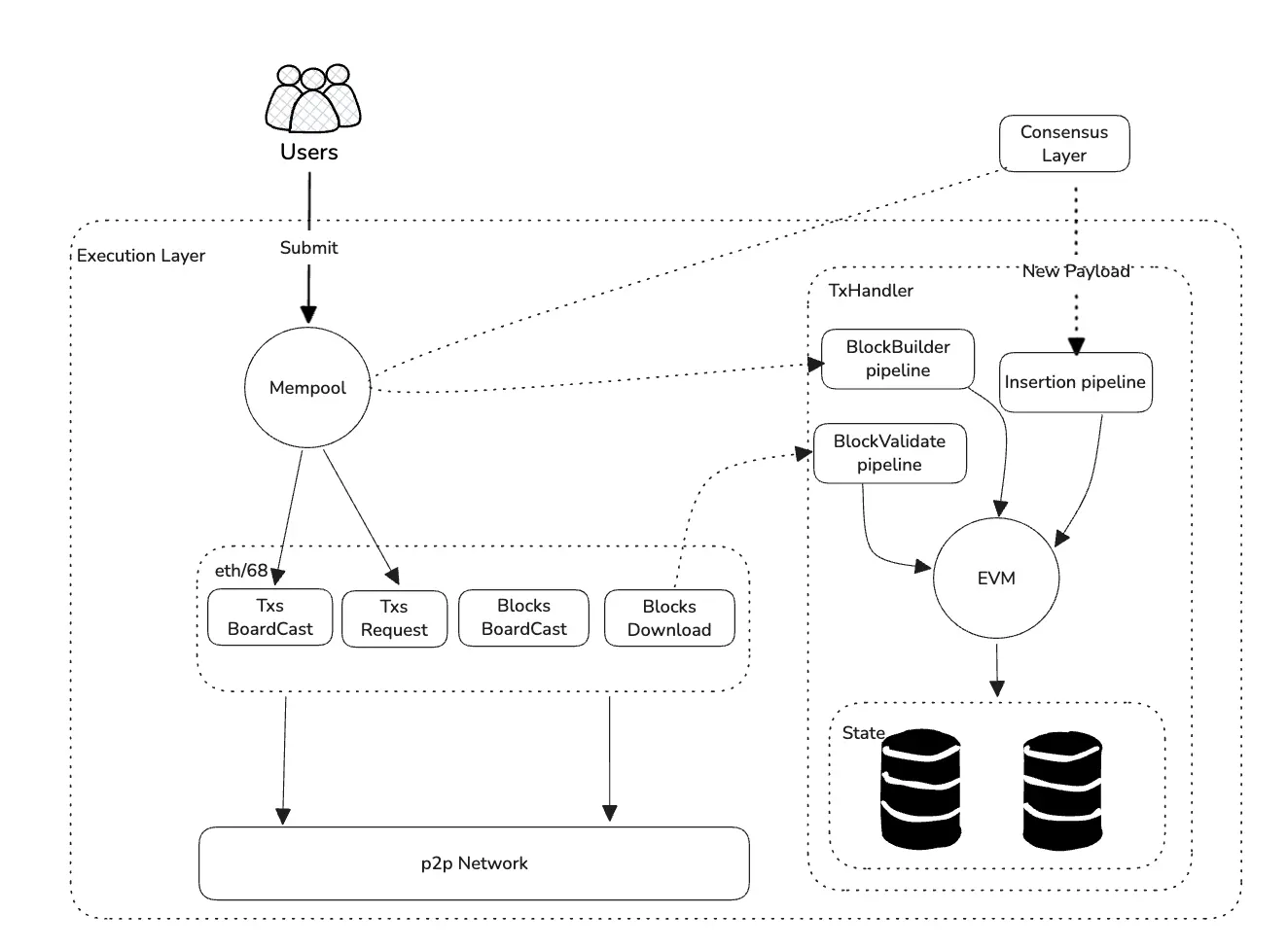
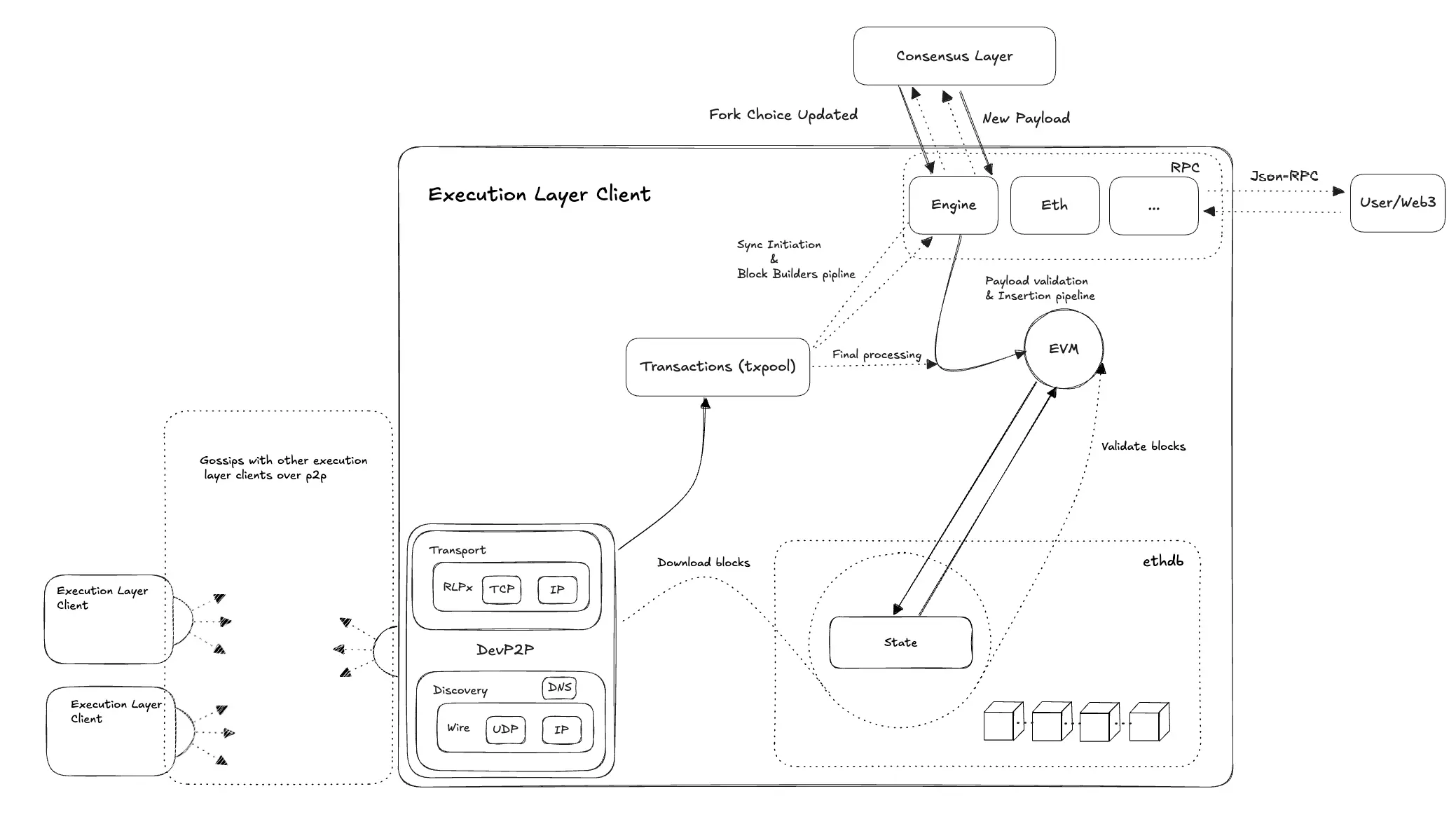
Geth ソースコードシリーズ:ストレージ設計と実装

 本シリーズは全部で六篇の記事があり、第二篇ではGethのストレージ構造設計と関連ソースコードについて体系的に解説し、そのデータベースの階層分けを紹介し、各階層における対応モジュールの核心機能を詳細に分析します。
本シリーズは全部で六篇の記事があり、第二篇ではGethのストレージ構造設計と関連ソースコードについて体系的に解説し、そのデータベースの階層分けを紹介し、各階層における対応モジュールの核心機能を詳細に分析します。?著者:po, LXDAO
イーサリアムは、世界最大のブロックチェーンプラットフォームとして、主流のクライアントである Geth(Go-Ethereum)が大部分のノードの運用と状態管理の責任を担っています。Geth の状態ストレージシステムは、イーサリアムの運用メカニズムを理解し、ノードのパフォーマンスを最適化し、将来のクライアントの革新を推進するための基盤です。
1. Geth の基盤データベースの概要
Geth v1.9.0 バージョン以降、Geth はデータベースを二つの部分に分けました:高速アクセスストレージ(最近のブロックと状態データ用の KV データベース)と フリーザーと呼ばれるストレージ(古いブロックとレシートデータ、つまり「古代データ」用)。
このように分ける目的は、高価で壊れやすい SSD への依存を減らし、アクセス頻度の低いデータをコストが低く、耐久性の高いディスクに移行することです。同時に、この分割は LevelDB/PebbleDB の負担を軽減し、整理と読み取り性能を向上させ、与えられたキャッシュサイズの下で、より多くの状態ツリーのノードがメモリに常駐できるようにし、全体的なシステム効率を向上させます。
高速アクセスストレージ: Geth ユーザーは、基盤データベースのオプションに慣れているかもしれません ------
--db.engineパラメータを使用して設定できます。現在のデフォルトオプションはpebbledbで、leveldbを選択することもできます。これらは Geth が依存する二つのサードパーティのキーバリューデータベースで、ストレージパスはdatadir/geth/chaindata(すべてのブロックと状態データ)とdatadir/geth/nodes(データベースメタデータファイル、非常に小さい)のファイルです。--history.state valueを使用して、高速アクセスに保存される最近の履歴状態ブロック数を設定できます。デフォルトは 90,000 ブロックです。フリーザー または 古代ストレージ(歴史データ) のディレクトリパスは通常
datadir/geth/chaindata/ancientsです。歴史データは基本的に静的であり、高性能な I/O を必要としないため、貴重な SSD スペースを節約し、より活発なデータの保存に使用できます。
この記事の焦点は状態データであり、これは KV データベースに保存されています。したがって、本文で言及される基盤データベースはデフォルトでこの KV ストレージを指し、フリーザーではありません。
Geth ストレージ構造:五つの論理データベース
Geth の基盤は LevelDB/PebbleDB を使用して、すべての RLP エンコードされたデータを保存していますが、論理的には異なる五つの用途の異なるデータベースに分けられています:
| 名称 | 説明 | |----------------|----------------| | 状態トライ | 世界の状態、アカウント、契約ストレージを含む | | 契約コード | 契約コード | | 状態スナップショット | 世界の状態スナップショット | | レシート | 取引レシート | | ヘッダー/ブロック | ブロックデータ |
各データはキーのプレフィックス(core/rawdb/schema.go)によって区別され、論理的に責任の分離が実現されています。geth db inspect を使用すると、Geth が保存しているすべてのイーサリアムデータ(ブロック高 22,347,000)を確認でき、ディスクスペースの占有が最も大きいのはブロック、レシート、状態データであることがわかります。
+-----------------------+-----------------------------+------------+------------+
| DATABASE | CATEGORY | SIZE | ITEMS |
+-----------------------+-----------------------------+------------+------------+
| Key-Value store | Headers | 576.00 B | 1 |
| Key-Value store | Bodies | 44.00 B | 1 |
| Key-Value store | Receipt lists | 42.00 B | 1 |
| Key-Value store | Difficulties (deprecated) | 0.00 B | 0 |
| Key-Value store | Block number->hash | 42.00 B | 1 |
| Key-Value store | Block hash->number | 873.78 MiB | 22347001 |
| Key-Value store | Transaction index | 13.48 GiB | 391277094 |
| Key-Value store | Log index filter-map rows | 12.98 GiB | 132798523 |
| Key-Value store | Log index last-block-of-map | 2.73 MiB | 59529 |
| Key-Value store | Log index block-lv | 45.05 MiB | 2362175 |
| Key-Value store | Log bloombits (deprecated) | 0.00 B | 0 |
| Key-Value store | Contract codes | 9.81 GiB | 1587159 |
| Key-Value store | Hash trie nodes | 0.00 B | 0 |
| Key-Value store | Path trie state lookups | 19.62 KiB | 490 |
| Key-Value store | Path trie account nodes | 45.88 GiB | 397626541 |
| Key-Value store | Path trie storage nodes | 176.23 GiB | 1753966511 |
| Key-Value store | Verkle trie nodes | 0.00 B | 0 |
| Key-Value store | Verkle trie state lookups | 0.00 B | 0 |
| Key-Value store | Trie preimages | 0.00 B | 0 |
| Key-Value store | Account snapshot | 13.34 GiB | 290797237 |
| Key-Value store | Storage snapshot | 93.42 GiB | 1295163402 |
| Key-Value store | Beacon sync headers | 622.00 B | 1 |
| Key-Value store | Clique snapshots | 0.00 B | 0 |
| Key-Value store | Singleton metadata | 1.36 MiB | 20 |
| Ancient store (Chain) | Hashes | 809.85 MiB | 22347001 |
| Ancient store (Chain) | Bodies | 639.98 GiB | 22347001 |
| Ancient store (Chain) | Receipts | 244.19 GiB | 22347001 |
| Ancient store (Chain) | Headers | 10.69 GiB | 22347001 |
| Ancient store (State) | History.Meta | 37.58 KiB | 487 |
| Ancient store (State) | Account.Index | 5.80 MiB | 487 |
| Ancient store (State) | Storage.Index | 7.47 MiB | 487 |
| Ancient store (State) | Account.Data | 6.46 MiB | 487 |
| Ancient store (State) | Storage.Data | 2.70 MiB | 487 |
+-----------------------+-----------------------------+------------+------------+
| TOTAL | 1.23 TIB | |
+-----------------------+-----------------------------+------------+------------+
2. ソースコードの視点からのストレージ層構造:6つのDB
全体的に、Geth には StateDB、state.Database、trie.Trie、TrieDB、rawdb、ethdb の6つのデータベースモジュールが含まれており、これらは「状態生命樹」の各レベルのようなものです。最上位の StateDB は EVM 実行段階の状態インターフェースで、アカウントとストレージの読み書きリクエストを処理し、これらのリクエストを階層的に下に伝え、最終的には最下層の物理的な永続化を担当する ethdb が物理データベースを読み書きします。
次に、これらの6つのデータベースモジュールの責任と相互関係を順に紹介します。

2.1 StateDB
Geth において、StateDB は EVM と基盤の状態ストレージ間の唯一の橋渡し であり、契約アカウント、残高、nonce、ストレージスロットなどの情報の読み書きを抽象化し管理します。他のすべてのデータベース(TrieDB、EthDB)に対する状態関連の読み書きは、StateDB 内の関連インターフェースによってトリガーされるため、StateDB はすべての状態データベースの脳 と言えます。これは、基盤の Trie や底層データベース(ethdb)を直接操作するのではなく、EVM が馴染みのあるアカウントモデルで相互作用できるように簡略化されたメモリビューを提供します。したがって、Geth に依存する多くのプロジェクトは、実際には基盤の EthDB や TrieDB がどのように実装されているかを気にしません ------ それらが正常に機能すれば十分であり、変更する必要はありません。Geth に基づくフォークプロジェクトのほとんどは、独自のビジネスロジックに適応するために StateDB 構造を変更します。たとえば、Arbitrum は StateDB を変更して彼らの Stylus プログラムを管理し、EVMOS は StateDB を変更してその状態を持つプリコンパイル契約(stateful precompile)の呼び出しを追跡します。
ソースコード内で、StateDB の主要な定義は core/state/statedb.go にあります。そのコア構造は、一連のメモリ状態オブジェクト(stateObject)を維持しており、各 stateObject はアカウント(契約ストレージを含む)に対応しています。また、ロールバックをサポートするための journal(トランザクションログ)や、状態変更を追跡するためのキャッシュメカニズムも含まれています。トランザクション処理とブロックパッキングの過程で、StateDB は一時的な状態変更の記録を提供し、最終確認後にのみ基盤データベースに書き込まれます。
StateDB のコア読み書きインターフェースは以下の通りで、基本的にアカウントモデル関連の API です:
// 読み取り関連
func (s *StateDB) GetBalance(addr common.Address) *uint256.Int
func (s *StateDB) GetStorageRoot(addr common.Address) common.Hash
// dirty 状態データの書き込み
func (s *StateDB) SetStorage(addr common.Address, storage map[common.Hash]common.Hash)
// EVM 実行中に発生した状態変更(dirty データ)をバックエンドデータベースにコミットする
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error)
ライフサイクル
StateDB のライフサイクルは一つのブロックに限られます。一つのブロックが処理されてコミットされると、この StateDB は廃棄され、もはや機能しません。
EVM があるアドレスを初めて読み取ると、
StateDBはTrie→TrieDB→EthDBデータベースからその値を読み込み、新しい状態オブジェクト(stateObject.originalStorage)にキャッシュします。この段階は「クリーンオブジェクト」と見なされます。トランザクションがそのアカウントと相互作用し、その状態を変更すると、オブジェクトは「ダーティ」(dirty)になります。
stateObjectはそのアカウントの元の状態とすべての変更されたデータを追跡し、ストレージスロットとそのクリーン/ダーティ状態を含みます。もしトランザクション全体が最終的にブロックにパッケージ化されると、
StateDB.Finalise()が呼び出されます。この関数は、selfdestructされた契約をクリーンアップし、ジャーナル(トランザクションログ)とガスリファンドカウンターをリセットします。すべてのトランザクションが完了した後、
StateDB.Commit()が呼び出されます。この前に、状態ツリーTrieは実際にはまだ変更されていません。このステップまで、StateDBはメモリ内の状態変更をストレージTrieに書き込み、各アカウントの最終ストレージルートを計算し、アカウントの最終状態を生成します。次に、すべての「ダーティ」状態オブジェクトがTrieに書き込まれ、その構造が更新され、新しいstateRootが計算されます。最後に、これらの更新されたノードは
TrieDBに渡され、異なるバックエンド(PathDB/HashDB)に応じてこれらのノードがキャッシュされ、最終的にディスク(LevelDB/PebbleDB)に永続化されます ------ 前提として、これらのデータがチェーンの再編成により失われていないことが必要です。
2.2 State.Database
state.Database は Geth において StateDB と基盤データベース(EthDB と TrieDB)を接続する重要な中間層であり、状態アクセスのための一連の簡潔なインターフェースと実用的なメソッドを提供します。インターフェースは比較的薄いですが、ソースコード内では、特に状態ツリーのアクセスと最適化において複数の重要な役割を果たしています。
Geth のソースコード内(core/state/database.go)で、state.Database インターフェースは state.cachingDB という具体的なデータ構造によって実装されています。その主な機能は以下の通りです:
- 統一された状態アクセスインターフェースの提供
state.Database は StateDB を構築するための必要な依存関係であり、アカウントトライとストレージトライを開くロジックをカプセル化しています。たとえば:
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error)
func (db *cachingDB) OpenStorageTrie(stateRoot common.Hash, address common.Address, root common.Hash, trie Trie) (Trie, error)
これらのメソッドは基盤の TrieDB の複雑さを隠蔽し、開発者は特定のブロックの状態を構築する際に、これらのメソッドを呼び出して正しいトライインスタンスを取得するだけで済み、ハッシュパス、トライエンコード、または基盤データベースを直接操作する必要はありません。
- 契約コードのキャッシュと再利用
契約コードへのアクセスコストは高く、しばしば複数のブロックで再利用されます。そのため、state.Database ではコードキャッシュロジックが実装されており、契約バイトコードをディスクから繰り返し読み込むことを避けています。この最適化はブロック実行効率を向上させるために重要です:
func (db *CachingDB) ContractCodeWithPrefix(address common.Address, codeHash common.Hash) []byte
このインターフェースは、アドレスとコードハッシュに基づいてキャッシュに迅速にヒットすることを可能にし、ヒットしなかった場合にのみ基盤データベースから読み込むことになります。
- 長いライフサイクル、複数のブロックでの再利用
StateDB のライフサイクルが単一のブロックに限られるのに対し、state.Database のライフサイクルは全体のチェーン(core.Blockchain)と一致します。ノードが起動する際に構築され、実行期間全体にわたって、StateDB の「忠実なパートナー」として、各ブロック処理時にサポートを提供します。
- 将来の Verkle Tree への移行の準備
現在の state.Database は「コードキャッシュ + トライアクセスのカプセル化」のように見えますが、Geth アーキテクチャにおける位置付けは非常に先見的です。将来的に状態構造が Verkle Trie に切り替わると、移行プロセスの中心コンポーネントとなり、新旧構造間のブリッジ状態を処理します。
2.3 Trie
Geth において、状態ツリー Trie(Merkle Patricia Trie)自体はデータを保存しませんが、トライは状態ルートハッシュの計算と変更ノードの収集という核心的な責任を担い、StateDB と基盤ストレージ間の橋渡しの役割を果たし、イーサリアム状態システムの中枢構造です。
EVM がトランザクションを実行したり契約を呼び出したりする際、基盤のデータベースを直接操作するのではなく、StateDB を介して間接的に Trie と相互作用します。Trie はアカウントアドレスとストレージスロットのクエリと更新リクエストを受け取り、メモリ内に状態変化のパスを構築します。これらのパスは最終的に再帰的なハッシュ計算を通じて、下から上に新しいルートハッシュ(state root)を生成します。このルートハッシュは現在の世界の状態の唯一の識別子であり、ブロックヘッダーに書き込まれ、状態の完全性と検証可能性を確保します。
一つのブロックが実行され、コミット段階(StateDB.Commit)に入ると、Trie はすべての変更されたノードを「圧縮」して必要なサブセットにし、TrieDB に渡し、さらにバックエンドのノードデータベース(HashDB または PathDB)に永続化されます。Trie ノードは構造化された形式でエンコードされているため、高効率の読み取りをサポートし、状態が異なるノード間で安全に同期および検証できるようにします。したがって、Trie は単なる状態コンテナではなく、上層の EVM と基盤ストレージエンジンを接続する結びつきであり、イーサリアムの状態に一貫性、安全性、モジュール化された拡張性を持たせています。
ソースコード内で、Trie は主に trie/trie.go に位置し、以下のコアインターフェースを提供します:
type Trie interface {
GetKey([]byte) []byte
GetAccount(address common.Address) (*types.StateAccount, error)
GetStorage(addr common.Address, key []byte) ([]byte, error)
UpdateAccount(address common.Address, account *types.StateAccount, codeLen int) error
UpdateStorage(addr common.Address, key, value []byte) error
DeleteAccount(address common.Address) error
DeleteStorage(addr common.Address, key []byte) error
UpdateContractCode(address common.Address, codeHash common.Hash, code []byte) error
Hash() common.Hash
Commit(collectLeaf bool) (common.Hash, *trienode.NodeSet)
Witness() map[string]struct{}
NodeIterator(startKey []byte) (trie.NodeIterator, error)
Prove(key []byte, proofDb ethdb.KeyValueWriter) error
IsVerkle() bool
}
ノードをクエリするための trie.get の例では、ノードタイプに応じてアカウントまたは契約ストレージに対応するノードを再帰的に検索し、検索の時間計算量は log(n) で、n はパスの深さです。
func (t *Trie) get(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if !bytes.HasPrefix(key[pos:], n.Key) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.get(n.Val, key, pos+len(n.Key))
if err == nil \&\& didResolve {
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.get(n.Children[key[pos]], key, pos+1)
if err == nil \&\& didResolve {
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveAndTrack(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.get(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
2.4 TrieDB
TrieDB は Trie とディスクストレージ間の中間層であり、トライノードのアクセスと永続化に特化しています。すべてのトライノード(アカウント情報や契約のストレージスロットを問わず)は最終的に TrieDB を介して読み書きされます。
プログラムが起動すると、TrieDB インスタンスが作成され、ノードがシャットダウンすると破棄されます。初期化時には EthDB インスタンスを渡す必要があり、EthDB インスタンスは具体的なデータ永続化操作を担当します。
現在、Geth は二つの TrieDB バックエンド実装をサポートしています:
HashDB:従来の方法で、ハッシュをキーとします。
PathDB:新たに導入された Path-based モデル(Geth 1.14.0 バージョン以降のデフォルト設定)で、パス情報をキーとし、更新とプルーニングの性能を最適化しています。
ソースコード内で、TrieDB は主に triedb/database.go に位置します。
Trie ノードの読み取りロジック
まず、ノードの読み取りプロセスを見てみましょう。これは比較的単純です。
すべての TrieDB バックエンドは、database.Reader インターフェースを実装する必要があります。その定義は以下の通りです:
type Reader interface {
Node(owner common.Hash, path []byte, hash common.Hash) ([]byte, error)
}
このインターフェースは基本的なノードクエリ機能を提供し、パス(path)とノードハッシュ(hash)に基づいてトライツリー内のノードを特定し、返します。注意すべきは、返されるのは原始的なバイト配列であり、TrieDB はノードの内容に関心を持たず、アカウントノード、リーフノード、またはブランチノードであるかどうかを知りません(これは上層の Trie が解析します)。
インターフェース内の owner パラメータは異なるトライを区別するために使用されます:
アカウントトライの場合、
ownerは空白のままにします。契約のストレージトライの場合、
ownerはその契約のアドレスであり、各契約には独自のストレージトライがあります。
言い換えれば、TrieDB は基盤ノードの読み書きバスであり、上層のトライに統一されたインターフェースを提供し、意味には関与せず、パスとハッシュのみに関心を持ちます。これにより、トライと物理ストレージシステム間の結合が解消され、異なるストレージモデルが柔軟に置き換え可能となり、上層ロジックに影響を与えません。
TrieDB の HashDB
TrieDB の歴史的に採用されているノード永続化方式は:
各トライノードのハッシュ(Keccak256)をキーとし、そのノードの RLP エンコードを値として、基盤のキーバリューストレージに書き込む というものです。この方式は現在 HashDB と呼ばれています。
この設計方式は非常に直接的ですが、いくつかの顕著な利点があります:
複数のトライの共存をサポート:根ハッシュを知っているだけで、全体のトライを復元できます。各アカウントのストレージ、アカウントトライ、異なる歴史状態の根ハッシュはそれぞれ管理できます。
サブツリーの重複排除(Subtrie Deduplication):同じサブツリーは同じ構造とノードハッシュを持つため、
HashDB内で自然に共有され、重複して保存する必要がありません。これはイーサリアムの大きな状態ツリーにとって特に重要です。なぜなら、大部分の状態はブロック間で変わらないからです。
注意すべきは、通常の Geth ノードは各ブロックの後にトライを完全にディスクに書き込むことはありません。この完全な永続化は「アーカイブモード」(--gcmode archive)でのみ発生し、大多数のメインネットノードはアーカイブモードを使用しません。
では、通常モードでは状態はどのようにディスクに書き込まれるのでしょうか?実際には、状態更新は最初にメモリにキャッシュされ、ディスクへの書き込みは遅延されます。このメカニズムは「遅延フラッシュ」(delayed flush)と呼ばれ、トリガー条件には以下が含まれます:
⏱️ 定期的なフラッシュ:デフォルトでは5分ごと(約5分間のブロック処理が完了した場合)に自動的に書き込まれます。
💾 キャッシュ容量が上限に達した場合:状態キャッシュが満杯になると、フラッシュしてメモリを解放する必要があります。
⛔ ノードがシャットダウンする場合:データの完全性を確保するため、すべてのキャッシュがフラッシュされます。
HashDB の構造設計は非常にシンプルですが、メモリ管理において非常に複雑です。特に 無効ノードのガーベジコレクションメカニズム に関して:ある契約が一つのブロックで作成され、次のブロックで破棄された場合 ------ この時、その契約に関連する状態ノード(契約アカウントとその独立したストレージトライを含む)はすでに無用となります。これをクリーンアップしなければ、無駄にメモリを占有することになります。したがって、HashDB は参照カウントとノード使用追跡メカニズムを設計し、どのノードがもはや使用されていないかを判断し、キャッシュから削除します。
TrieDB の PathDB
PathDB は TrieDB の新しいバックエンド実装です。これは、トライノードのディスク上の永続化とメモリ内の維持方法を変更しました。前述のように、HashDB はノードのハッシュを使用してインデックスストレージを行います。この方法では、状態中の使用されなくなった部分をクリーンアップ(prune)することが非常に困難です。この長期的な問題を解決するために、Geth は PathDB を導入しました。
PathDB は HashDB といくつかの顕著な違いがあります:
- トライノードはデータベース内でそのパス(path)をキーとして保存されます。特定のアカウントまたはストレージキーのノードのパスは、そのアカウントアドレスのハッシュまたはストレージキーがトライツリー上で他のノードと共有するプレフィックス部分です。契約のストレージトライ内のノードのパスプレフィックスには、そのアカウントアドレスのハッシュが含まれます。
account trie node key = Prefix(1byte) || COMPACTED(nodepath) storage trie node key = Prefix(1byte) || account hash(32byte) || COMPACTed(nodepath)
HashDBは定期的に各ブロックの完全な状態をフラッシュします。これは、あなたが気にしない古いブロックであっても、完全な状態が残ることを意味します。一方、PathDBは常にディスク上に一つのトライを維持します。各ブロックは同じトライを更新するだけです。パスをキーとして使用するため、ノードの変更は古いノードを上書きするだけで済み、削除されたノードも安全に削除できます。なぜなら、他のトライがそれらを参照していないからです。永続化されたこのトライは、チェーンの最新のヘッダーではなく、少なくとも 128 ブロック 遅れています。最近の 128 ブロックのトライ変更はメモリ内にそれぞれ存在し、短いチェーンの再編成(reorg)に対応します。
より大きな再編成が発生した場合、
PathDBはフリーザーに保存された各ブロックの状態差分(state diff)を利用して逆適用(rollback)し、ディスク状態を分岐点まで戻します。
2.5 RawDB
Geth において、rawdb は基盤データベースの読み書きモジュールであり、状態、ブロックチェーンデータ、トライノードなどのコアデータへのアクセスロジックを直接カプセル化しており、全体のストレージシステムの基盤インターフェース層 です。これは EVM やビジネスロジック層に直接公開されることはなく、内部ツールとして TrieDB、StateDB、BlockChain などのモジュールの永続化操作にサービスを提供します。rawdb と trie はどちらもデータ自体を直接保存するわけではなく、基盤データベースの抽象化されたカプセル化層 であり、アクセスルールを定義する役割を担い、最終的なデータの書き込みや読み取りを実行するわけではありません。rawdb を Geth の「ハードドライブ」と考えることができ、すべてのコアチェーンデータのキーと値のフォーマットおよびアクセスインターフェースを定義し、異なるモジュールが統一的かつ信頼性のある方法でデータを読み書きできるようにします。直接開発の中で使用されることはほとんどありませんが、全体の Geth ストレージ層で最も基礎的で重要な部分です。
コア機能
ソースコード内で、rawdb は主に core/rawdb/accessors_trie.go に位置します。rawdb は多くの ReadXxx や WriteXxx などの読み書きメソッドを提供し、異なるタイプのデータに標準化されたアクセスを行います。たとえば:
ブロックデータ(
core/rawdb/accessors_chain.go):ReadBlock,WriteBlock,ReadHeaderなど状態データ(
core/rawdb/accessors_trie.go):WriteLegacyTrieNode,ReadTrieNodeなど全体のメタデータ:総難易度、最新ヘッダーブロックハッシュ、創世情報など
これらのメソッドは通常、約定されたキーのプレフィックス(例:h はヘッダー、b はブロック、a は AccountTrieNode を示す)を使用して、基盤データベース内のデータを整理します(LevelDB または PebbleDB)。
TrieDB との関係
TrieDB 自体は直接ハードディスクを操作せず、具体的な読み書きを rawdb に委託します。そして rawdb はさらに基盤の ethdb.KeyValueStore インターフェースを呼び出します。これには LevelDB、PebbleDB、またはメモリデータベースが含まれる可能性があります。たとえば、Trie に関連するデータ(アカウント、ストレージスロットなど)を書き込む際:
HashDBベースのトライノードは、rawdb.WriteLegacyTrieNodeなどのメソッドを使用して(hash, rlp-encoded node)の形式でデータベースに書き込まれます。PathDBベースのトライノードは、WriteAccountTrieNode,WriteStorageTrieNodeなどのメソッドを使用して(path, rlp-encoded node)の形式でデータベースに書き込まれます。
2.6 EthDB
Geth において、ethdb は全体のストレージシステムのコア抽象であり、「生命の樹」の役割を果たします ------ 磁盤に深く根ざし、EVM と実行層の各コンポーネントにサポートを提供します。その主な目的は、基盤データベースの実装の違いを隠蔽し、全体の Geth に統一されたキーと値の読み書きインターフェースを提供することです。このため、Geth はどこでも具体的なデータベース(LevelDB、PebbleDB、MemoryDB など)を直接使用せず、ethdb が提供するインターフェースを介してデータにアクセスします。
インターフェースの抽象化と責任の分担
ソースコード内で、ethdb は主に ethdb/database.go に位置します。ethdb の最もコアなインターフェースは KeyValueStore() であり、一般的なキーと値の操作メソッドを定義しています:
type KeyValueStore interface {
Has(key []byte) (bool, error)
Get(key []byte) ([]byte, error)
Put(key []byte, value []byte) error
Delete(key []byte) error
}
このインターフェースは非常にシンプルで、基本的な読み書き操作をカバーしています。拡張インターフェース ethdb.Database は、この基盤の上に フリーザーの冷ストレージの読み書きサポート(AncientStore) を追加し、主にチェーンデータ(歴史的なブロック、トランザクションレシート)の管理に使用されます:新しいブロックは KV ストレージに保存され、古いものはフリーザーに移行されます。
さらに、ethdb はさまざまな具体的な実装バージョンを提供しています:
LevelDB:最初のデフォルト実装で、安定して成熟しています。PebbleDB:現在推奨されるデフォルト実装で、より高速でリソース効率が高いです。RemoteDB:リモート状態アクセスシナリオに使用され、軽量ノード、バリデーター、またはモジュール化された実行環境で特に重要です。MemoryDB:完全なメモリ実装で、通常は dev モードや単体テストに使用されます。
これにより、Geth は異なるシナリオ間でストレージバックエンドを柔軟に切り替えることができ、たとえば開発デバッグには MemoryDB を使用し、メインネットの稼働には PebbleDB を使用します。
ライフサイクルとモジュールの貫通
各 Geth ノードが起動すると、ユニークな ethdb インスタンスが作成され、このオブジェクトはプログラム全体を通じて存在し、ノードがシャットダウンするまで続きます。構造設計上、これは core.Blockchain に注入され、さらに StateDB、TrieDB などのモジュールに渡され、グローバルに共有されるデータアクセスの入り口となります。
ethdb が基盤データベースの詳細を抽象化しているため、Geth の他のコンポーネントはそれぞれのビジネスロジックに集中できます。たとえば:
StateDBはアカウントとストレージスロットにのみ関心を持ちます。TrieDBはトライノードの保存と検索方法にのみ関心を持ちます。rawdbはチェーンデータのキーと値のレイアウトを整理する方法にのみ関心を持ちます。
これらの上層コンポーネントは、データがどの具体的なデータベースエンジンに保存されているかを認識する必要はありません。
3. 六つの DB の作成順序と呼び出しチェーン
このセクションでは、Geth ノードの起動から始まり、これら 6 つの DB の起動プロセスと呼び出し関係を整理します。
3.1 作成順序:
全体の作成順序は ethdb → rawdb/TrieDB → state.Database → stateDB → trie であり、ソースコード内の具体的な呼び出しチェーンは以下の通りです:
【ノード初期化段階】
MakeChain
└── MakeChainDatabase
└── node.OpenDatabaseWithFreezer
└── node.openDatabase
└── node.openKeyValueDatabase
└── newPebbleDBDatabase / remotedb
↓
ethdb.Database
↓
rawdb.Database (ethdb をカプセル化)
└── rawdb.NewDatabaseWithFreezer(ethdb)
↓
trie.Database (TrieDB)
└── trie.NewDatabase(ethdb)
└── backend: pathdb.New(ethdb) / hashdb.New(ethdb)
↓
state.Database (cachingDB)
└── state.NewDatabase(trieDB)
↓
【ブロック処理段階】
chain.InsertChain
└── bc.insertChain
└── state.New(root, state.Database)
↓
state.StateDB
└── stateDB.OpenTrie()
└── stateDB.OpenStorageTrie()
↓
trie.Trie / SecureTrie
3.2 ライフサイクルの概要
| DBモジュール | 作成時期 | ライフサイクル | 主な責任 |
|--------------------|------------------------|------------|------------------------------------------|
| ethdb.Database | ノード初期化 | プログラム全体 | 基盤ストレージを抽象化し、統一インターフェース(LevelDB / PebbleDB / Memory) |
| rawdb | ethdb 呼び出しをカプセル化 | データ自体を保存しない | ブロック/レシート/総難易度などのチェーンデータの読み書きインターフェースを提供 |
| TrieDB | core.NewBlockChain() | プログラム全体 | PathDB/HashDB ノードのキャッシュと永続化 |
| state.Database | core.NewBlockChain() | プログラム全体 | TrieDB をカプセル化し、契約コードをキャッシュし、将来的に Verkle 移行をサポート |
| state.StateDB | 各ブロック実行前に一度作成 | ブロック実行期間 | 状態の読み書きを管理し、状態ルートを計算し、状態変更を記録 |
| trie.Trie | 各アカウントまたはスロットアクセス時に作成 | 一時的で、データを保存しない | Trie 構造の変更とルートハッシュの計算 |
4. HashDB と PathDB の状態コミットと読み取りメカニズムの詳細比較
ブロックの実行が完了すると、StateDB は func (s ***StateDB**) **Commit**(block uint64, deleteEmptyObjects bool, noStorageWiping bool) を呼び出し、次のストレージ状態更新をトリガーします:
ret, err := s.**commit**(deleteEmptyObjects, noStorageWiping)を通じて、トライ状態ツリーに関わるすべての更新を収集します。
func (s *StateDB) commit(deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
…
newroot, set := s.trie.Commit(true)
root = newroot
…
}
その中で呼び出される
trie.Commitメソッドは、すべてのノード(ショートノードまたはフルノードを問わず)を ハッシュノードに圧縮t.root = **newCommitter**(nodes, t.tracer, collectLeaf).**Commit**(t.root, t.uncommitted > 100)し、すべてのダーティノードを StateDB に返します。StateDB は収集されたすべてのダーティノードを使用して TrieDB キャッシュ層を更新します:
HashDBはメモリ内にdirties map[**common**.**Hash**]***cachedNode**というオブジェクトを維持し、これらの更新をキャッシュし、関連するトライノードの参照を更新します。キャッシュにはサイズ制限があります。PathDBはメモリ内にtree ***layerTree**というオブジェクトを維持し、これらの更新をキャッシュするために最大 128 層の diff を追加します。
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
…
// トライデータベースが有効な場合、状態更新を新しいレイヤーとしてコミットします
if db := s.db.TrieDB(); db != nil {
start := time.Now()
if err := db.Update(ret.root, ret.originRoot, block, ret.nodes, ret.stateSet()); err != nil {
return nil, err
}
s.TrieDBCommits += time.Since(start)
}
…
HashDBまたはPathDBのキャッシュが上限を超えた場合、フラッシュがトリガーされ、rawdbが提供する関連インターフェースを通じてキャッシュがethdbの実際の永続層に書き込まれます:フルノード
HashDBモードでは、キーがハッシュであるため、同じアカウントが変更された場合、基盤データベースはキーを通じて同じアカウントであることを感知できず、そのキーと対応する値を簡単に削除することはできません。そうしないと、他のアカウントの状態に影響を与える可能性があります。したがって、新しく変更された KV のみが DB に書き込まれ、古い状態を削除することはできません。たとえば、異なる契約アドレス A と B が実際に同じ契約コードを保存している場合、HashDBでは(キーがハッシュ、値が契約コード)というストレージを共有します。EVM の実行後に契約 A が破棄されると、契約 B のコードと契約 A のコードはデータベース内で同じキーを持つため、データベース内のハッシュがキーの値を削除することはできません。そうしないと、契約 B が後でその契約コードを読み取れなくなります。フルノード
PathDBモードでは、キーがパスであるため、同じアカウントが基盤 DB に対応するキーが同じであり、同じアカウントに対応する状態を上書きすることができます。したがって、フルノードの状態をトリミングするのが容易です。したがって、現在 Geth のフルノードはデフォルトでPathDBモードを採用しています。アーカイブ(archive)ノードは、各ブロックに対応する状態を保存する必要があるため、この場合
HashDBの方が優位です。なぜなら、異なるブロックで多くのアカウントのデータは実際には変更されていないため、ハッシュをキーとして使用することは自動的にトリミングの特性を持つからです。一方、PathDBは各ブロックでのすべてのアカウントの状態を保存する必要があるため、状態が非常に大きくなります。したがって、Geth のアーカイブノードはHashDBモードのみをサポートします。
インスタンス:フルノード下の HashDB と PathDB の実際のディスク書き込みの比較
左側のトライは MPT の初期状態であり、赤色の部分は変更されるノードです。右側は MPT の新しい状態であり、緑色は以前の 4 つの赤色ノードが変更されたことを示しています。

HashDB モードでは、C/D/E ノードが変更された後、ハッシュが必ず変化するため、C/D/E ノードに対応する 3 つのアカウントがすでにディスクに書き込まれていても、これらの新しいノード C'/D'/E' は書き込む必要があり、永続化された後はこれらの古いノードを削除することは非常に困難です。ディスクの更新前(左図)と後(右図)の状態は以下の通りです。

PathDB モードでは、C/D/E ノードに対応する値が変更されても、基盤ストレージのキー(パス)が変わらないため、永続化時にこれらの 3 つのノードに対応する値を C'/D'/E' に直接置き換えることができます。ディスクデータには過剰な冗長性が生じません(同じ契約が異なるパスで保存されることがあるため、影響は小さいですが)。ディスクの更新前(左図)と後(右図)の状態は以下の通りです。

インスタンス:HashDB と PathDB のアカウント読み取りの比較
core/rawdb/accessors_trie.go に以下のデバッグコードを追加し、stateDB が 0xB3329fcd12C175A236a02eC352044CE44d (アカウントハッシュ:0x**aea7c67d**a6a9bdb230dd07d0e96626e5e57c9cba04dc8039c923baefe55eacd1)を読み取る際に関与するトライノードデータベースの読み取りをテストします:
func ReadAccountTrieNode(db ethdb.KeyValueReader, path []byte) []byte {
fmt.Println("PathDB read:", hexutil.Encode(accountTrieNodeKey(path)))
data, _ := db.Get(accountTrieNodeKey(path))
return data
}
func ReadLegacyTrieNode(db ethdb.KeyValueReader, hash common.Hash) []byte {
fmt.Println("HashDB read:", hash)
data, err := db.Get(hash.Bytes())
if err != nil {
return nil
}
return data
}
PathDB で読み取ったトライノードは以下の通りで、アカウントアドレスハッシュの前 8 ビットに対応するパスのノードを読み取っていることがわかります:
0x41はプレフィックスであり、追加の0はnibbles(半バイト)の整列に必要です
PathDB read: 0x410a
PathDB read: 0x410a0e
PathDB read: 0x410a0e0a
PathDB read: 0x410a0e0a07
PathDB read: 0x410a0e0a070c
PathDB read: 0x410a0e0a070c06
PathDB read: 0x410a0e0a070c0607
PathDB read: 0x410a0e0a070c06070d
HashDB で読み取ったトライノードは以下の通りで、ハッシュをキーとするノードを読み取っていることがわかります:
HashDB read: 0xb01e32b0c38555bb27f1a924b8408824f97dd8d70f096b218d397906a9095385
HashDB read: 0x99d38ce254e6c35a49504345a30e94b4ea08338279385bae33feaaa11c3a0a00
HashDB read: 0xfcc42d902aa9107b83ee7839a8bc61b370cc5eac9ee60db1af7165daf6c3f76b
HashDB read: 0x3232bc99a88337d2aea2e8c237eb5b4ebb9366ff5bdd94b965ac6f918bd6303f
HashDB read: 0x04ae6f0462f6c0c7e5827dc46fcd69329483d829c39f624744f7b55c09c2cc96
HashDB read: 0x22a16c466cc420e8ed97fd484cecc8f73160ee74a56cfc87ff941d1b56ff46f8
HashDB read: 0xae26238e219065458f314e456265cd9c935e829ba82aebe6d38bacdbb14582f3
HashDB read: 0xe9ce7770c224e563b0c407618b7b7d8614da3d5da89f3960a3bec97e78fc0ae0
HashDB read: 0x2c7d134997a5c3e0bf47ff347479ee9318826f1c58689b3d9caeac77287c3af8
全体として、PathDB と HashDB は状態データを保存するためにトライデータ構造を保持していますが、PathDB はトライノードの path をキーとして使用し、HashDB はトライノード値に対応するハッシュをキーとして使用します。両者ともに保存される値は同じで、トライノードの値です。
5. DB 関連の読み書き操作プロセスの追跡
1. トランザクション実行段階
すべてのアカウントとストレージ値は
StateDB.GetStateなどのメソッドを通じてTrie→TrieDB(pathdb/hashdb)→RawDB→Level/PebbleDBから StateDB メモリに読み込まれます。次に、EVM は状態変更(
Statedb.SetBalance()を呼び出すなど)を行い、これも StateDB のメモリに保持されます。これには:残高変更、nonce 更新、ストレージ変更が含まれます。
2. 単一のブロック実行完了後のキャッシュ更新
StateDB.Commit()を呼び出し → ダーティノードを収集して変更されたトライノードのグループに変換し、新しい StateRoot を計算します。内部で
Trie.Commit()を呼び出し →TrieDB.Update()を呼び出して変更を TrieDB キャッシュ層に保存します。PathDB は最大 128 ブロックの diff キャッシュ層制限があります。
HashDB のキャッシュ層にもサイズ制限があります。
上記の制限を超えると、さらに
TrieDB.Commitがトリガーされ、実際に基盤データベースに書き込まれます。
3. 単一のブロック実行完了後のヘッダー / レシートのコミット:
- 状態以外に、ブロックヘッダー、ボディ、トランザクションレシートなどのデータは
RawDB.Write*(ethdb)などのインターフェースを通じてethdb層に書き込まれます。
4. 複数のブロック実行後にキャッシュが上限を超えた場合、実際のディスク書き込みがトリガーされます。TrieDB.Commit → batch → DB
- ノードがアーカイブノードであるか、フラッシュインターバルを超えた場合、または TrieDB のキャッシュ制限を超えた場合、またはノードがシャットダウンする前に、コミットがトリガーされ、最終的にディスクに書き込まれます。以下は
PathDBモードでのディスク書き込みのコアコードです:
func (db *Database) commit(hash common.Hash, batch ethdb.Batch, uncacher *cleaner) error {
…
rawdb.WriteLegacyTrieNode(batch, hash, node.node) // 複数の変更されたトライノードをバッチに追加(未書き込み)
if batch.ValueSize() >= ethdb.IdealBatchSize { // IdealBatchSize に達した後、書き込みをトリガー
batch.Write() // 書き込み
batch.Replay(uncacher) // uncacher にメモリをクリーンアップするよう通知
batch.Reset() // バッチをリセット
}
…
6. まとめ
Geth のこの 6 つのデータベースモジュールは、それぞれ異なるレベルの責任を担い、底から上へのデータアクセスチェーンを形成しています。多層の抽象化と多段階のキャッシュを通じて、上層モジュールは基盤の具体的な実装を気にする必要がなくなり、底層ストレージエンジンのプラグイン性と高い I/O パフォーマンスを実現しています。
最下層の ethdb は物理ストレージを抽象化し、具体的なデータベースタイプを隠蔽し、LevelDB、Pebble、RemoteDB などのさまざまなバックエンドをサポートします。その上の層は rawdb で、ブロック、ブロックヘッダー、トランザクションなどのコアチェーンデータ構造のエンコード、デコード、カプセル化を担当し、チェーンデータの読み書き操作を簡素化します。TrieDB は状態ツリーのノードのキャッシュと永続化を管理し、hashdb と pathdb の二つのバックエンドをサポートし、異なる状態トリミング戦略とストレージ方式を実現します。
さらに上には、trie.Trie が状態変化の実行コンテナとルートハッシュの計算コアを担い、実際の状態構築と遍歴操作を行います。state.Database はアカウントと契約ストレージトライへの統一アクセスをカプセル化し、契約コードのキャッシュを提供します。そして最上層の state.StateDB はブロック実行中に EVM と接続するインターフェースであり、アカウントとストレージの読み取りキャッシュと書き込みサポートを提供し、EVM が基盤のトライの複雑な構造を気にする必要がないようにします。
これらのモジュールは責任の分離とインターフェースの隔離を通じて、柔軟で効率的な状態管理システムを構築し、Geth が複雑なチェーン状態とトランザクション実行の中で良好なパフォーマンスとメンテナンス性を維持できるようにしています。
参考文献
[2]5つのDBの物語
[3]Path-based storage & Inline prune - NodeReal
[4]RLP エンコード規範
 リスク警告 リスク警告
リスク警告 リスク警告