


















グラデーション:Bittensorエコシステムの分散型AIトレーニングインフラストラクチャ

概要
Gradientsは、Bittensor上に構築された分散型AIトレーニングサブネット(SN56)であり、その核心は「タスクの公開、マイナーの競争、検証の選別」などのメカニズムを通じて、モデルのトレーニングを複雑な技術プロセスから市場主導のネットワーク協力プロセスに変換することにあります。アーキテクチャ的には、AutoMLと分散コンピューティングを組み合わせ、インセンティブメカニズムを中心としたトレーニング市場を形成し、AIの使用のハードルを下げるだけでなく、コンピューティングリソースの利用効率を向上させています。エコシステムとデータのパフォーマンスの観点から、Gradientsは基盤ネットワークの構築を完了しましたが、現在のところインセンティブの重みと資金の流入は相対的に限られています。GradientsはTAOエコシステム内のトレーニングインフラを補完し、「市場主導のAI最適化」という新しいパラダイムを探求し、長期的には分散型AIトレーニングの重要な入り口層として発展する可能性があります。
1.Web2 AutoMLから始める: AIトレーニングの現状と限界
1.1 AutoMLとは何か
従来の認識では、AIモデルをトレーニングすることは非常に高いハードルを持つ作業であり、エンジニアはデータを処理し、モデルを選択し、パラメータを繰り返し調整し、効果を評価しなければなりません。この全過程は複雑で時間がかかります。しかし、AutoML(自動化機械学習)の登場は、これらの煩雑なステップを「パッケージ化して自動化」することを本質的に意味します。これは「自動でモデルを作成するツール」として理解できます:ユーザーはデータを提供し、システムに達成したい目標(分類、予測、認識など)を伝えるだけで、残りのプロセス(モデルの選択、パラメータの調整、トレーニングの最適化)はすべてシステムによって自動的に完了します。これにより、AIは少数の専門エンジニアのツールから、一般の開発者や企業が使用できる能力へと徐々に変わり、AIの普及に向けた重要な一歩となりました。
1.2 従来のAutoMLの核心的な限界
現在のAutoMLの主流な実装方法は、Google Vertex AIやAWS SageMakerなどのクラウドベンダープラットフォームに集中しています。これらのプラットフォームは「AIトレーニングをサービス」として提供しています。Web2 AutoMLはAIの使用のハードルを著しく下げましたが、その基盤となるモデルには明らかな限界があります。まず、中央集権的な問題があり、コンピューティングリソース、価格設定、ルールはすべてプラットフォームによって管理されており、ユーザーは単一のサービスプロバイダーに強く依存し、交渉力が欠如しています。次に、コストが高く不透明であり、AIトレーニングに依存するGPUリソースは主にクラウドベンダーに集中しており、価格メカニズムには市場競争が欠けています。さらに重要なのは、最適化効率には限界があることです。従来のAutoMLは本質的に「一つのシステムが最適解を見つける手助けをする」ものであり、そのシステムがどれほど複雑であっても、本質的には単一の技術パスの最適化に属します。その探索空間は限られており、完全に異なる複数のアプローチを同時に試みることは困難です。したがって、現在のWeb2 AIトレーニングは「閉じたシステム」であり、モデルのトレーニング、最適化、リソースの調整はすべて単一のプラットフォームによって制御される環境で行われます。このようなモデルは効率的ですが、需要の増加に伴い、その限界が徐々に明らかになっています。
2.Gradients:ネットワークを用いてAIトレーニングを再構築する
2.1 Gradientsとは:分散型AutoMLプラットフォーム
前の章で述べたように、従来のWeb2 AutoMLの核心的な問題は「閉じたシステム」であり、モデルのトレーニングはプラットフォームに依存し、最適化のパスは限られ、リソースの流動は制限されています。Gradientsはこのモデルの再構築を試みています。Gradientsは、WanderingWeightsによって発起された分散型エンジニアコミュニティに由来し、Bittensorネットワーク上に構築され、Subnet 56で運営されるAIトレーニングサブネットです。従来のプラットフォームとは異なり、中央集権的なサービスを提供するのではなく、トレーニングプロセスを分解し、オープンネットワークによって完了させます。ユーザーはタスクの目標(モデルの種類やデータ)を定義するだけで、残りのプロセス(トレーニングの実行、パラメータの最適化、結果の選別)はネットワークによって自動的に完了します。このようなモデルでは、AIトレーニングは複雑なエンジニアリングプロセスから「要求を提出し、結果を得る」というシンプルなプロセスに抽象化され、専門的なハードルが非常に高い技術作業ではなく、より一般的な能力に近づきます。
2.2 閉じたシステムからオープンな協力へ:Gradientsは何を解決したのか
Gradientsの核心的な変化は、元々単一のプラットフォーム内部に閉じ込められていたトレーニングプロセスを、オープンな協力のネットワークプロセスに変換したことです。トレーニングタスクはもはや単一のシステムによって完了するのではなく、複数の参加者に分配され、並行して試行され、統一された評価メカニズムによって最適な結果が選別されます。この構造は、まず中央集権的なサービスプロバイダーへの依存を減少させ、トレーニングを分散型コンピューティングに基づいて構築します。同時に、分散されたGPUリソースが同じネットワークに統合され、競争の中で市場に近いリソース配置の方法が形成されます。さらに重要なのは、モデルの最適化が単一路線に制限されず、さまざまな方法の並行探索の中でより良い解に近づくことができ、全体的な最適化の上限を向上させることです。
2.3 本質的な変化:ツールから「トレーニング市場」へ
従来のAutoMLでは、プラットフォームはユーザーが最適解を見つける手助けをするツールのようなものでした。しかし、Gradientsでは、このプロセスは持続的に運営される「市場」に近づいています:ユーザーは要求を発表し、異なる参加者が同じタスクを巡って競争し、評価メカニズムを通じて結果を選別します。これにより、モデルの性能はもはや単一のシステムの能力に依存せず、複数の参加者の競争と反復から生まれます。AutoMLも、相対的に閉じた技術最適化の問題から、インセンティブによって駆動される動的プロセスに変わり、参加者が増えるにつれて最適化能力が拡張されることが可能になります。この変化により、AIトレーニングは市場のような自己進化の特性を持ち始めます。
2.4 TAOエコシステムにおける役割:AIトレーニング基盤インフラ層
Bittensorのサブネットシステムにおいて、異なるサブネットは推論、データ処理、トレーニングなどの異なる機能を担っており、Gradientsが位置するのはトレーニング層です。これは、分散されたコンピューティングリソースを実際のモデル出力に変換し、タスクの分配と評価メカニズムを通じて、これらのリソースが持続的に調整され、最適化されることを可能にします。同時に、これはコンピューティングリソースの供給とモデルの需要を結びつけ、トレーニングを単なるリソース消費プロセスから、組織化され最適化されるネットワーク協力プロセスに変えます。このシステムにおいて、Gradientsは分散型リソースを利用可能なAI能力に変換し、上層アプリケーションの発展を支える中心的な役割を果たします。
3.核心アーキテクチャ:AIトレーニングはネットワーク内でどのように完了するのか
前の章で述べたように、GradientsはAIトレーニングを「プラットフォーム内で完了する」から「ネットワーク協力で完了する」へと変えました。それでは、このネットワークは具体的にどのように機能しているのでしょうか?この章の核心は、このプロセスをより直感的な方法で分解することです。
3.1 分散トレーニング:タスクはどのように「複数人で完了する」のか
Gradientsを持続的に運営される「トレーニング協力ネットワーク」として想像できます。ユーザーがトレーニングタスクを提出すると、このタスクは特定のシステムに渡されるのではなく、ネットワーク内の複数の参加者に同時に分配されます。これらの参加者は同じデータと目標に基づいて、それぞれ異なるトレーニング方法を試み、指定された時間内に結果を提出します。その後、システムはこれらの結果を統一的に評価し、最も良い方案を選別します。最終的に、より優れた結果が報酬を得て、他の方案は淘汰されます。ユーザーの視点から見ると、このプロセスは一度のタスクを発起するだけで、同時に「複数の異なる最適化のアイデアを呼び出し」、自動的に最適解を選出することに相当します。この方法の鍵は、単一のノードがどれほど強力であるかではなく、複数人の並行した試行と自動選別を通じて、結果が最適に近づくことです。
このネットワークには、主に3つのタイプの参加者がいます:ユーザー、マイナー、検証者です。ユーザーはトレーニングの要求を提出し、マイナーはコンピューティングリソースを提供し、異なるトレーニング方法を試みます。検証者は結果を評価し、最適なモデルを選別する役割を担っています。このような分業により、トレーニングプロセスは持続的に運営され、より良い解を選別し続けることができます。全体として、これは「需要、供給、評価」によって駆動される協力ネットワークを構成しています。
3.2 市場主導のAutoML
前述のメカニズムの分解からわかるように、Gradientsは単にAutoMLをブロックチェーンに移行したのではなく、複数の参加者とインセンティブメカニズムを導入することによって、モデル最適化の基盤となる論理を変えました。従来のAutoMLは単一のシステムが限られたパスで最適解を探すことに依存していましたが、Gradientsではこのプロセスが全体のネットワークに拡張されます:異なる参加者が同じタスクを巡って持続的に異なる方法を試み、統一評価を通じて選別と反復を行います。これにより、モデルの最適化はもはや一度きりの計算プロセスではなく、繰り返し進化できる動的プロセスとなります。このメカニズムの下では、性能の優れた結果がより高い報酬を得ることができ、参加者が最適化戦略を継続的に改善することを促進し、全体的な効果を向上させます。
4.インセンティブと競争メカニズム:AIトレーニングはどのように「正の循環」を形成するのか
4.1 インセンティブメカニズム(TAO駆動):トレーニング行動から収益報酬へ
Gradientsが長期的に運営できる鍵は、その背後にあるインセンティブメカニズムにあります。これはBittensorが提供するネイティブなインセンティブシステムに依存しています。その中で、TAOはBittensorネットワークのネイティブトークンであり、ネットワーク全体の「価値の担体」となっています:一方では、コンピューティングリソースとモデルの貢献を提供する参加者に報酬を与え、もう一方では、ステーキングなどの方法を通じてサブネットの重みの分配に参加し、リソースが異なるサブネット間でどのように流動するかに影響を与えます。
Bittensorメインネットは新しいインセンティブEmission、すなわちTAO(現在の適切な量は約3600TAO/日)を継続的に生成し、一定のルールに従って異なるサブネットに分配します。各サブネットがどれだけ分配されるかは、ネットワーク全体における「パフォーマンス」に依存します。たとえば、活動の程度、貢献の質、資金のサポート状況などです。Gradientsが存在するサブネットにとって、この部分の分配されたTAOは内部で再分配され、貢献したモデルがより良いものであれば、より多くの報酬を得ることができます。
具体的には、マイナーがトレーニング結果を提出し、検証者がこれらの結果をテストしてスコアを付けます。システムはスコアに基づいて各参加者の「貢献重み」を計算し、この重みに従って報酬を分配します。パフォーマンスの良いモデル(たとえば、一般化能力が高く、効果が安定しているもの)はより高い報酬を得ることができ、検証者がより正確にスコアを付け、実際の質を反映できれば、より多くのインセンティブを得ることができます。この設計により、「より良い結果を出すこと」が「より多くの利益を得ること」に直接対応し、参加者がモデルを継続的に最適化することを促進します。
4.2 サブネット間の競争:内部競争だけでなく、外部ランキングも
サブネット内部の競争に加えて、GradientsはBittensorネットワーク全体の「横の競争」にも直面しています。TAOの分配は動的であり、異なるサブネットはより高い重みを争います。高品質な結果を継続的に生み出し、より多くの参加者を引き付けるサブネットだけが、より大きな報酬のシェアを得ることができます。したがって、Gradientsのインセンティブは内部のモデルパフォーマンスだけでなく、全体のエコシステムにおける相対的な競争力にも依存しています。全体のシステムは多層的な循環を形成します:サブネット内部にはモデル間の競争があり、サブネット間には全体のパフォーマンス競争があります。最終的に、コンピューティングリソースの投入、モデルの効果、経済的なリターンが結びつき、持続的に運営される正のフィードバックメカニズムを形成します。
4.3 Gradients 5.0:競争から「トーナメントメカニズム」へ
初期の持続的競争の基盤の上に、Gradientsはさらに構造化されたメカニズム、すなわち「トーナメント式トレーニング」を進化させました。これは周期的な競技として理解できます:各トレーニングラウンドでは時間のウィンドウが設定され、複数の参加者が同じタスクを巡って競争し、複数のラウンドで選別を行い、最終的に最適な方案を選出します。この形式は、段階的な比較と集中評価を強調します。重要な変化の一つは、マイナーが直接トレーニング結果を提出するのではなく、「トレーニング方法」(コード)を提出し、検証ノードが統一的に実行することです。これにより、一方では公平性が向上し、異なる計算環境による干渉を避けることができ、他方ではデータとトレーニングプロセスのプライバシーがより良く保護されます。さらに、優れた方案はしばしば蓄積され、再利用可能な方法となり、継続的に蓄積される「ベストプラクティス」に似ています。長期的には、このメカニズムは最適なモデルを選別するだけでなく、進化し続けるトレーニング方法のライブラリを構築することにもなります。
5.エコシステムの現状
5.1 参加者構造:需要、供給、評価から構成される協力ネットワーク
Gradientsエコシステムは、3つのコアロールから構成されています:ユーザー(需要側)、マイナー(供給側)、検証者(評価側)です。ユーザーは主にAI開発者、中小企業、Web3ビルダーであり、このグループは通常一定の技術基盤を持っていますが、コンピューティングリソースや完全なモデルトレーニング能力が不足しているため、Gradientsを通じて低コストでモデル構築を完了することを好みます。マイナーはGPUコンピューティングリソースを提供し、トレーニングタスクの競争に参加し、その核心的な動機はTAOの収益を得ることです。検証者はトレーニング結果を評価し、ランキングを付ける役割を担い、モデルの質とメカニズムの有効な運営を確保する重要な一環です。
より細分化されたユーザーのプロファイルを見ると、Gradientsの実際の使用者群は明らかに「半開発者化」の特徴を示しています:トップAIラボとは異なり、完全に技術的背景のない一般ユーザーでもなく、一定のエンジニアリング能力を持つ開発者とWeb3技術ユーザーが主な構成要素です。この点はそのコミュニティ構造にも反映されており、現在のエコシステムは英語が主導で、コアユーザーは主に北米とヨーロッパの開発者群に分布し、同時に一部の東南アジアのマイナーや世界のGPUリソース提供者をカバーしています。全体として、技術駆動の開発者コミュニティに近いです。
5.2 エコシステムの運営現状
5月12日現在、Gradientsのアルファトークン価格は約0.0255 TAOで、保有アドレスは約4,890件、マイナーは243人、検証者は12人で、Emissionの占有率は1.61%です。同時に、その流動性プールにおけるTAOの占有率は2.19%、Alphaの占有率は97.81%です。価格と保有数から見ると、Gradientsは一定のユーザーベースと注目を集めていますが、全体としてはまだ初期の拡散段階にあります。TAOエコシステム内の主要プロジェクトChutesと比較すると、その日のアルファトークン価格は0.0877 TAOで、保有アドレスは13,409件です。
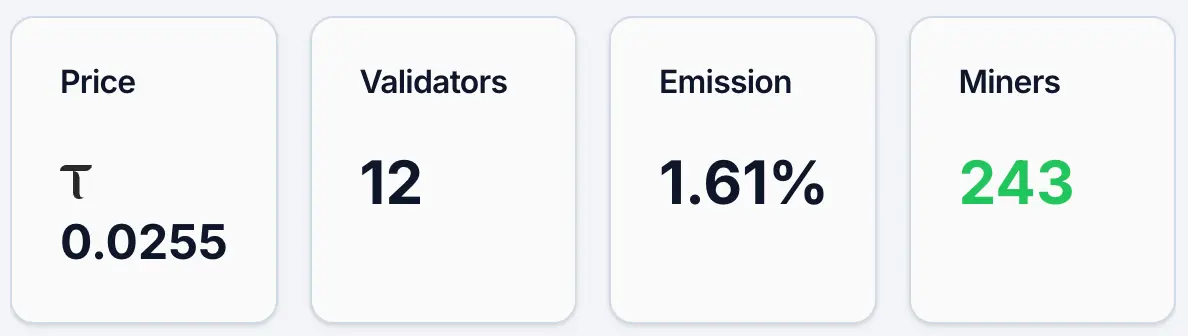
Figure 1. Gradientsデータ。出典:https://bittensormarketcap.com/subnets/56
次に、Emissionインセンティブメカニズムについてです。Bittensorシステムにおいて、Emissionはこのサブネットが全ネットワークの新しい報酬のリアルタイム分配の重みを指します。Bittensorネットワークは新しいTAOを継続的に生成し、重みに従って各サブネットに分配しますが、Gradientsの現在の1.61%は、全ネットワークの新しいインセンティブのごく一部を得ていることを意味します。この指標は本質的に、市場が資金の流れ(たとえば、ステーキング)を通じて異なるサブネットに対する「投票結果」を反映しています。したがって、1.61%のレベルは通常、現在の市場の認知度と資金の流入が相対的に限られていることを意味し、他方で将来的には重みを増加させる余地があることも示しています。資金構造(流動性プール)を見ると、TAOの占有率はわずか2.19%で、Alphaは97.81%に達しており、外部からの資金流入は依然として限られており、現在は主にサブネット内部の供給が主導しています。価格は新たな資金に対して敏感であり、より多くのTAOが流入すれば、より明確な拡大効果をもたらす可能性があります。
6.競争格局と優劣
6.1 業界の位置付け:分散型AutoMLのトレーニング基盤インフラ
Gradientsは「AIトレーニング基盤インフラ + 分散型AutoML」という細分化されたトラックに位置しています。これは、モデルのトレーニングを中央集権的なプラットフォームから解放し、ネットワーク化されたメカニズムを通じてより効率的なリソース利用とモデル最適化を実現しようとしています。Web2システムにおいて、このトラックはすでに比較的成熟しており、典型的な代表にはGoogle Vertex AIやAWS SageMakerがあります。これらのプラットフォームはクラウドコンピューティングを通じて開発者にワンストップのモデルトレーニングとデプロイサービスを提供していますが、その本質は依然として中央集権的なアーキテクチャです。それに対して、Gradientsの違いは「機能が多い」ことではなく、基盤となる論理が異なることにあります:トレーニングを「プラットフォームサービス」から「ネットワーク協力」に変え、競争メカニズムを通じて最適な結果を選別することで、市場化された運営のトレーニングシステムに近づけています。
6.2 横の比較:Web2とWeb3 AutoMLの違い
よりマクロな視点から見ると、Web2とWeb3のAutoMLにおける違いは、本質的には2つの異なるパラダイムの比較です。Web2モデルは効率と安定性を強調し、リソースとエンジニアリングの最適化を集中させ、制御可能で成熟したサービス体験を提供します。一方、Web3モデルはオープン性とインセンティブメカニズムを強調し、複数の参加者を導入することで、競争の中でモデル最適化を進化させます。具体的には、Web2 AutoMLは「強力なツール」のようで、ユーザーはタスクをプラットフォームに渡し、システム内部で最適解の探索を完了させます。一方、Gradientsを代表とするWeb3 AutoMLは「オープンマーケット」のようで、ユーザーは要求を発表し、異なる参加者が解決策を提供し、評価メカニズムを通じて結果を選別します。この違いがもたらす直接的な影響は、前者はより安定して制御可能ですが、最適化のパスが限られていることです。後者は探索空間が広く、潜在的な上限が高いですが、安定性と成熟度においてはまだ改善の余地があります。
6.3 Web3におけるGradientsの差別化
現在のWeb3 AIトラックでは、大多数のプロジェクトが依然として推論層やAIエージェントの方向に集中しており、「トレーニング基盤」に特化したプロジェクトは相対的に少ないです。一部のプロジェクトはコンピューティングネットワークやデータネットワークを組み合わせてトレーニング能力を提供しようとしていますが、全体的には多くがリソース調整やコンピューティング市場のレベルにとどまっています。Gradientsの差別化は、単にコンピューティングリソースをマッチングするだけでなく、「モデル最適化メカニズム」自体にさらに上昇し、評価と競争のシステムを導入することで、トレーニングプロセスに持続的な進化能力を持たせることにあります。これは、単に「コンピューティングリソースはどこから来るのか」を解決するだけでなく、「これらのコンピューティングリソースをより効率的に使用する方法」を解決することを意味します。位置付けとしては、Gradientsは単なる「トレーニング結果指向」のネットワークに近く、単純なコンピューティング市場やツールプラットフォームではないことが、他の多くのWeb3 AIプロジェクトとの核心的な違いです。
6.4 核心的な利点:メカニズム駆動の効率向上
総合的に見ると、Gradientsの利点は主にそのメカニズム設計にあります。まず、タスクの抽象化を通じて使用のハードルを下げ、ユーザーが複雑なトレーニングプロセスに深く関与しなくてもモデルの結果を得られるようにし、潜在的なユーザー群を拡大します。次に、リソースの面では、分散型コンピューティングの導入により、トレーニングは単一のクラウドベンダーに依存せず、理論的には競争を通じてより弾力的なコスト構造を形成できます。さらに重要なのは、最適化方法の変化です。複数の参加者が並行して探索し、選別メカニズムを組み合わせることで、Gradientsは従来の単一路線の最適化とは異なる解決策を提供し、モデルがより短時間でより優れた性能に達する機会を与えます。この「競争駆動の最適化」モデルが、Gradientsの最も核心的な利点です。
6.5 潜在的な課題
モデルの質には安定性の問題があるかもしれません。分散型トレーニングは多くの参加者に依存しており、上限を引き上げることができる一方で、結果の変動をもたらす可能性があり、中央集権的なシステムと比較して制御性において一定の不確実性があります。次に、企業レベルの信頼の問題です。企業ユーザーにとって、データの安全性とトレーニングプロセスの検証可能性は極めて重要であり、分散型環境下でデータが悪用されず、結果が監査可能であることを確保する方法は依然として重要な試練です。最後に、トークン経済への依存です。Gradientsの運営はインセンティブメカニズムに高度に依存しており、TAOの収益の魅力が低下すれば、マイナーの参加度や全体のネットワークの活性に影響を与える可能性があります。したがって、その長期的な持続可能性は、経済モデルが安定した正の循環を形成できるかどうかにある程度依存しています。
7.未来展望:分散型AutoMLは成立するのか?
現在の段階では、Gradientsはまだ初期段階にあり、その未来が本当に実現できるかどうかは、いくつかの重要なポイントに依存しています。最も核心的なのは、真のトレーニング需要を持続的に引き付けることができるかどうかであり、単にインセンティブに基づく参加ではないことです。次に、モデルの質、分散型の方法が安定して使える、あるいはさらに優れた結果を生み出せるかどうか、そして経済メカニズムが正の循環を形成できるかどうか、コンピューティングリソースの供給と収益の間に長期的なバランスを保つことができるかどうかです。
より大きな業界の背景に置くと、AIトレーニングは2つのパスに分化しています。一つはWeb2モデルで、主要なテクノロジー企業が主導し、リソースとエンジニアリング能力を集中させてモデル性能を強化し続けるもので、安定性と成熟度が利点です。もう一つは、Gradientsを代表とするWeb3パスで、オープンネットワークとインセンティブメカニズムを通じて、より多くの参加者がモデル最適化に共同で参加し、競争の中で上限を引き上げるものです。前者は「より強力なシステムを構築する」ことに焦点を当て、後者は「自己進化するネットワークを構築する」ことに近いです。
この観点から見ると、Gradientsの探求は新しい可能性を示しています:AIトレーニングはもはや単なる技術的な問題ではなく、「コンピューティングリソース + データ + 市場メカニズム」の組み合わせです。このモデルが成立すれば、分散型AIのトレーニングの入り口となり、Bittensorエコシステム内で重要な基盤インフラの役割を果たす可能性があります。もちろん、この方向性は時間の検証を必要としますが、従来のパスとは異なる進化の道筋をAutoMLに提供しています。
参考
1.Bittensor Documentation:https://docs.learnbittensor.org
2.Gradients website:https://www.gradients.io/
3.Gradients:https://bittensormarketcap.com/subnets/56
4.Gradients X:https://x.com/gradients_ai
5.Taostats:https://taostats.io/subnets/56/chart
 リスク警告
リスク警告










