

















IOSG: 이더리움 성능 해방, EVM 병목 현상을 초월하는 혁신의 길

 모든 계산이 체인에서 이루어져야 하는 이유는 무엇인가요? 신뢰할 필요가 없고 탈중앙화된 실행 시스템이 존재할까요? 이것이 DCompute 시스템이 실현할 수 있는 것입니다.
모든 계산이 체인에서 이루어져야 하는 이유는 무엇인가요? 신뢰할 필요가 없고 탈중앙화된 실행 시스템이 존재할까요? 이것이 DCompute 시스템이 실현할 수 있는 것입니다.저자: Siddharth Rao, IOSG Ventures
이더리움 성능 해방: EVM 병목 현상을 넘는 혁신의 길
이더리움 가상 머신(EVM)의 성능에 대하여
이더리움 메인넷에서의 모든 작업은 일정량의 가스를 소모합니다. 만약 우리가 기본 애플리케이션에 필요한 계산량을 모두 체인에 올린다면, 앱은 충돌하거나 사용자는 파산하게 될 것입니다.
이로 인해 L2가 탄생했습니다: OPRU는 거래를 묶어 메인넷에 제출하기 위해 정렬기를 도입했습니다. 이는 앱이 이더리움의 보안을 유지하는 데 도움을 줄 뿐만 아니라 사용자에게 더 나은 경험을 제공합니다. 사용자는 거래를 더 빠르게 제출할 수 있고, 수수료도 더 저렴해졌습니다. 비록 운영 비용이 저렴해졌지만, 여전히 원주율 EVM을 실행 계층으로 사용하고 있습니다. ZK 롤업과 유사하게, Scroll, Polygon zkEVM은 EVM 기반의 zk 회로를 사용하거나 사용할 예정이며, zk 증명은 그 증명기에서 이루어지는 각 거래 또는 대량 거래에서 생성됩니다. 이는 개발자가 "전체 체인 상"의 애플리케이션을 구축할 수 있게 하지만, 여전히 고성능 애플리케이션을 효율적이고 경제적으로 운영할 수 있을까요?
이러한 고성능 애플리케이션에는 어떤 것들이 있을까요?
사람들이 가장 먼저 떠올리는 것은 게임, 체인 상 주문서, Web3 소셜, 머신 러닝, 유전체 모델링 등입니다. 이 모든 것들은 대량의 계산을 필요로 하며, L2에서 운영하는 것도 매우 비쌀 것입니다. EVM의 또 다른 문제는 계산 속도와 효율성이 현재의 다른 시스템, 예를 들어 SVM(Sealevel Virtual Machine)보다 떨어진다는 것입니다.
비록 L3 EVM이 계산을 더 저렴하게 만들 수 있지만, EVM 자체의 구조는 고계산을 실행하는 최적의 방법이 아닐 수 있습니다. 왜냐하면 병렬 계산을 수행할 수 없기 때문입니다. 새로운 계층을 구축할 때마다 탈중앙화 정신을 유지하기 위해 새로운 인프라(새로운 노드 네트워크)를 구축해야 하며, 이는 여전히 동일한 수의 제공자가 확장하거나 새로운 노드 제공자(개인/기업) 집단이 자원을 제공해야 합니다.
따라서 더 발전된 솔루션이 구축될 때마다 기존 인프라는 업그레이드되거나 그 위에 새로운 계층이 구축되어야 합니다. 이 문제를 해결하기 위해 우리는 후양자 안전, 탈중앙화, 신뢰가 필요 없는 고성능 계산 인프라가 필요합니다. 이는 진정으로 효율적으로 양자 알고리즘을 사용하여 탈중앙화 애플리케이션을 위한 계산을 수행할 수 있습니다.
Solana, Sui, Aptos와 같은 대체 L1들은 병렬 실행을 가능하게 하지만, 시장 정서와 유동성 부족으로 인해 개발자가 부족하여 이더리움에 도전하지 않을 것입니다. 신뢰가 부족하고, 이더리움이 네트워크 효과로 구축한 성은 이정표적입니다. 지금까지 ETH/EVM의 킬러는 존재하지 않습니다. 여기서의 문제는, 왜 모든 계산이 체인 상에서 이루어져야 하는가? 신뢰가 필요 없는 탈중앙화 실행 시스템이 존재하는가? 이것이 DCompute 시스템이 실현할 수 있는 것입니다.
DCompute 인프라는 탈중앙화, 후양자 안전을 달성해야 하며, 신뢰가 필요 없는 시스템이어야 합니다. 블록체인/분산 기술이 필요하지 않거나 필요하지 않아야 하지만, 계산 결과의 검증, 올바른 상태 전환 및 최종 확인은 매우 중요합니다. EVM 체인의 운영이 바로 그러합니다. 네트워크의 보안성과 불변성을 유지하면서, 탈중앙화되고 신뢰가 필요 없는 안전한 계산은 체인 밖으로 이동할 수 있습니다.
우리가 여기서 주로 간과하는 것은 데이터 가용성 문제입니다. 이 글은 데이터 가용성에 대한 관심이 없지 않으며, Celestia와 EigenDA와 같은 솔루션이 이미 이 방향으로 발전하고 있습니다.
1: 계산만 외주화하기 (Only Compute Outsourced)
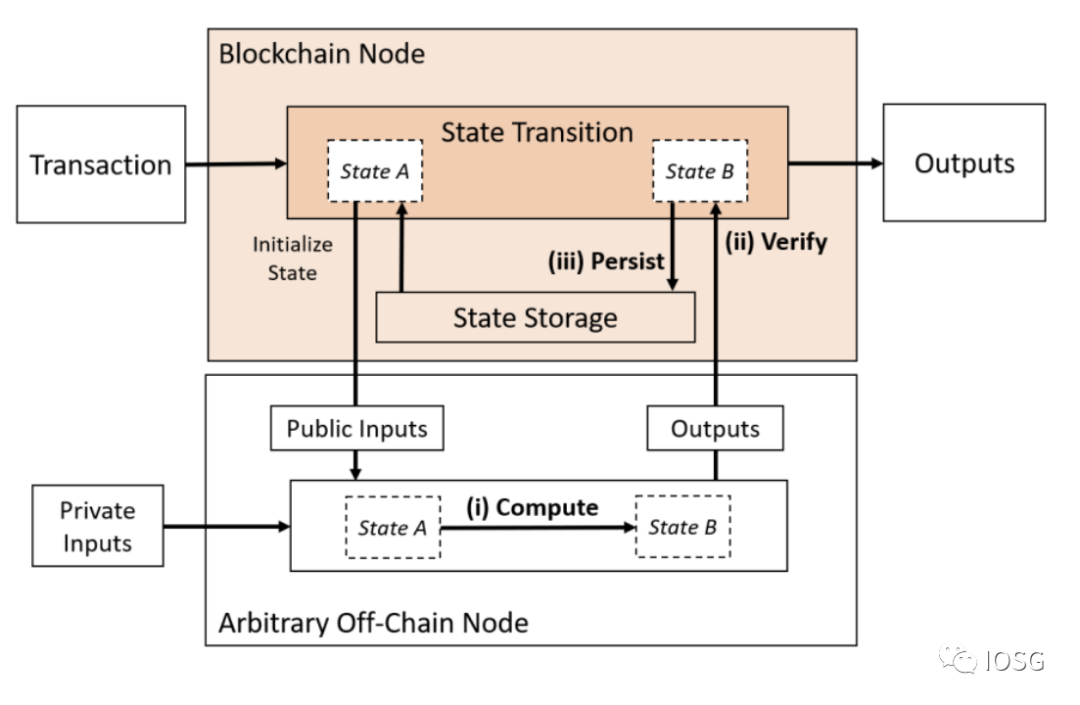
(출처: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
2. 계산과 데이터 가용성 외주화하기
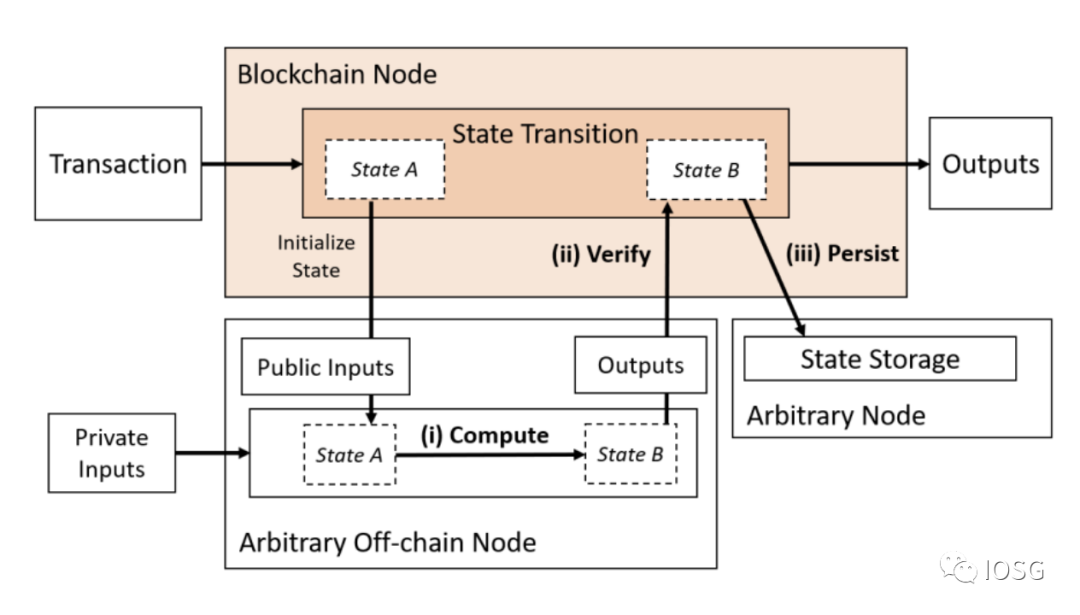 (출처: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
(출처: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
Type 1을 보면, zk-rollups는 이미 이 작업을 수행하고 있지만, EVM에 제한되거나 개발자에게 새로운 언어/명령 집합을 배우도록 요구합니다. 이상적인 솔루션은 효율적이고, 효과적이며(비용과 자원), 탈중앙화되고, 비공식적이며 검증 가능해야 합니다. ZK 증명은 AWS 서버에서 구축할 수 있지만, 이는 탈중앙화되지 않습니다. Nillion과 Nexus와 같은 솔루션은 일반 계산 문제를 탈중앙화된 방식으로 해결하려고 시도하고 있습니다. 그러나 이러한 솔루션은 ZK 증명이 없으면 검증할 수 없습니다.
Type 2는 체인 외부 계산 모델과 분리된 데이터 가용성 계층을 결합하지만, 계산은 여전히 체인에서 검증해야 합니다.
오늘날 사용할 수 있는 불완전하게 신뢰할 수 있는 또는 완전히 신뢰할 수 없는 다양한 탈중앙화 계산 모델을 살펴보겠습니다.
다른 계산 시스템 (Alternative Computation Systems)
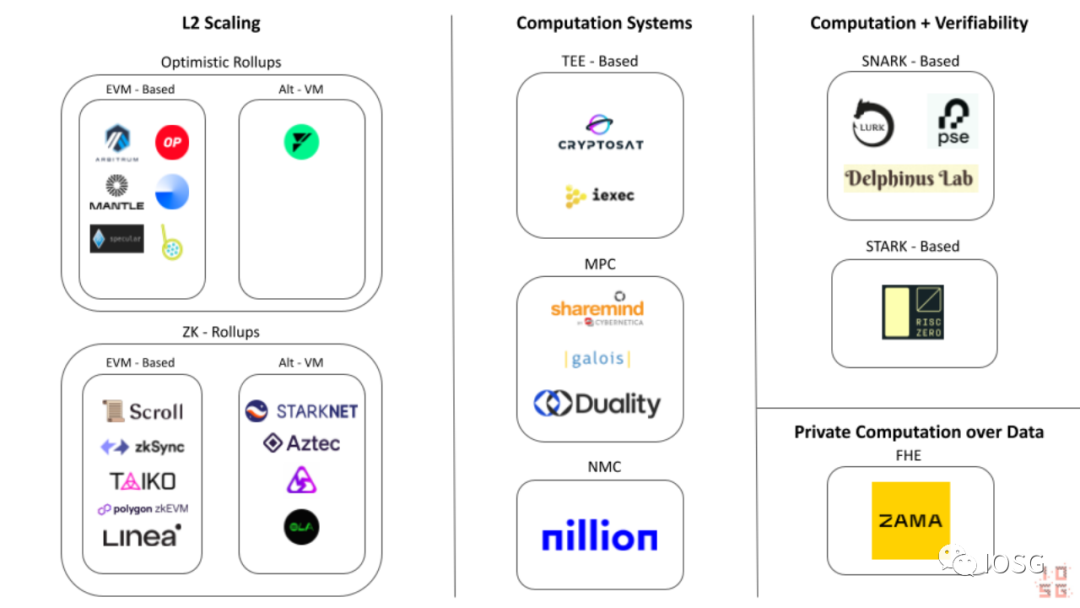
이더리움 외주 계산 생태도 (출처: IOSG Ventures)
- 안전한 격리 계산 (Secure Enclave Computations) / 신뢰할 수 있는 실행 환경 (Trusted Execution Environments)
TEE(신뢰할 수 있는 실행 환경)는 컴퓨터나 스마트폰 내부의 특별한 상자와 같습니다. 그것은 자신의 잠금 장치와 열쇠를 가지고 있으며, 특정 프로그램(신뢰할 수 있는 애플리케이션이라고 함)만 접근할 수 있습니다. 이러한 신뢰할 수 있는 애플리케이션이 TEE 내부에서 실행될 때, 다른 프로그램이나 심지어 운영 체제 자체로부터 보호받습니다.
이는 몇몇 특별한 친구만 들어갈 수 있는 비밀 은신처와 같습니다. TEE의 가장 일반적인 예는 우리가 사용하는 장치에 존재하는 안전한 격리 구역으로, 예를 들어 애플의 T1 칩과 인텔의 SGX가 있습니다. 이는 장치 내부에서 FaceID와 같은 중요한 작업을 수행하는 데 사용됩니다.
TEE는 격리된 시스템이기 때문에 인증 과정은 파괴될 수 없습니다. 인증 중에 신뢰 가정이 존재하기 때문입니다. 이를 안전한 문이 존재한다고 상상해 보십시오. 당신은 그것이 안전하다고 믿습니다. 왜냐하면 인텔이나 애플이 그것을 만들었기 때문입니다. 그러나 세상에는 이 안전한 문을 파괴할 수 있는 충분한 수의 보안 해커(해커 및 기타 컴퓨터)가 있습니다. TEE는 "후양자 안전"이 아닙니다. 이는 무한한 자원을 가진 양자 컴퓨터가 TEE의 보안을 해칠 수 있음을 의미합니다. 컴퓨터가 빠르게 강력해짐에 따라, 우리는 장기적인 계산 시스템과 암호학적 솔루션을 구축할 때 후양자 안전성을 염두에 두어야 합니다.
- 안전한 다자 계산 (SMPC)
SMPC(안전한 다자 계산)는 블록체인 기술 종사자들이 잘 아는 계산 솔루션입니다. SMPC 네트워크에서의 대략적인 작업 흐름은 다음과 같은 3부분으로 구성됩니다:
- 단계 1: 계산의 입력을 분할(share)로 변환하고 SMPC 노드 간에 분배합니다.
- 단계 2: 실제 계산을 수행하며, 일반적으로 SMPC 노드 간의 메시지 교환을 포함합니다. 이 단계가 끝날 때마다 각 노드는 계산 출력 값의 하나의 분할을 갖게 됩니다.
- 단계 3: 결과 분할을 하나 이상의 결과 노드로 전송하며, 이 노드는 LSS(비밀 공유 복구 알고리즘)를 실행하여 출력 결과를 재구성합니다.
자동차 생산 라인을 상상해 보십시오. 자동차의 구성 및 제조 부품(엔진, 차문, 후방 거울)은 원래 장비 제조업체(OEM)(작업 노드)에 외주화되고, 모든 부품을 조립하여 자동차를 제조하는 조립 라인이 있습니다(결과 노드).
비밀 공유(Secret sharing)는 개인 정보 보호를 위한 탈중앙화 계산 모델에서 매우 중요합니다. 이는 단일 참여자가 전체 "비밀"(이 경우 입력)을 얻지 못하게 하여 악의적으로 잘못된 출력을 생성하는 것을 방지합니다. SMPC는 가장 쉽고 안전한 탈중앙화 시스템 중 하나일 수 있습니다. 현재 완전히 탈중앙화된 모델은 존재하지 않지만, 논리적으로는 가능성이 있습니다.
Sharemind와 같은 MPC 제공자는 계산을 위한 MPC 인프라를 제공하지만, 제공자는 여전히 중앙 집중화되어 있습니다. 개인 정보를 어떻게 보장할 것인가? Sharemind와 같은 네트워크가 악의적인 행동을 하지 않도록 어떻게 보장할 것인가? 이것이 zk 증명과 zk 검증 가능한 계산의 필요성입니다.
- Nil Message Compute (NMC)
NMC는 Nillion 팀이 개발한 새로운 분산 계산 방법입니다. 이는 MPC의 업그레이드 버전으로, 노드가 결과 상호작용을 통해 통신할 필요가 없습니다. 이를 위해 그들은 일회성 마스킹(One-Time Masking)이라는 암호 원리를 사용하여, 일련의 무작위 수인 블라인딩 팩터(blinding factors)를 사용하여 비밀을 가립니다. 이는 일회성 패딩과 유사합니다. OTM은 효율적인 방식으로 정확성을 제공하도록 설계되었으며, 이는 NMC 노드가 계산을 수행하기 위해 어떤 메시지를 교환할 필요가 없음을 의미합니다. 이는 NMC가 SMPC의 확장성 문제를 겪지 않음을 의미합니다.
- 제로 지식 검증 가능한 계산
ZK 검증 가능한 계산(ZK Verifiable Computation)은 입력 집합과 함수에 대해 제로 지식 증명을 생성하고, 시스템이 수행한 계산이 올바르게 실행되었음을 증명합니다. ZK 검증 가능한 계산은 새로운 개념이지만, 이미 이더리움 네트워크 확장 로드맵의 매우 중요한 부분입니다.
ZK 증명은 다양한 구현 형태가 있으며(아래 그림 참조, "Off-Chaining_Models" 논문에서 요약됨):
 (출처: IOSG Ventures, Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
(출처: IOSG Ventures, Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
위에서 우리는 zk 증명의 구현 방식에 대한 기본적인 이해를 얻었으며, ZK 증명을 사용하여 계산을 검증하기 위해 필요한 조건은 무엇일까요?
- 첫째, 우리는 증명 원리를 선택해야 하며, 이상적인 증명 원리는 증명 생성 비용이 낮고, 메모리 요구 사항이 낮으며, 검증이 용이해야 합니다.
- 둘째, zk 회로를 선택해야 하며, 이는 위의 원리를 통해 계산을 생성하는 증명을 설계해야 합니다.
- 마지막으로, 특정 계산 시스템/네트워크에서 제공된 입력으로 주어진 함수에 대해 계산을 수행하고 출력을 제공해야 합니다.
개발자의 난제 - 증명 효율성의 딜레마
또한 언급해야 할 점은 회로를 구축하는 장벽이 여전히 높다는 것입니다. 개발자가 Solidity를 배우는 것이 쉽지 않은데, 이제는 개발자가 Circom과 같은 새로운 언어를 배우거나 zk-app을 구축하기 위해 특정 프로그래밍 언어(예: Cairo)를 배워야 한다는 것은 다소 먼 이야기처럼 보입니다.
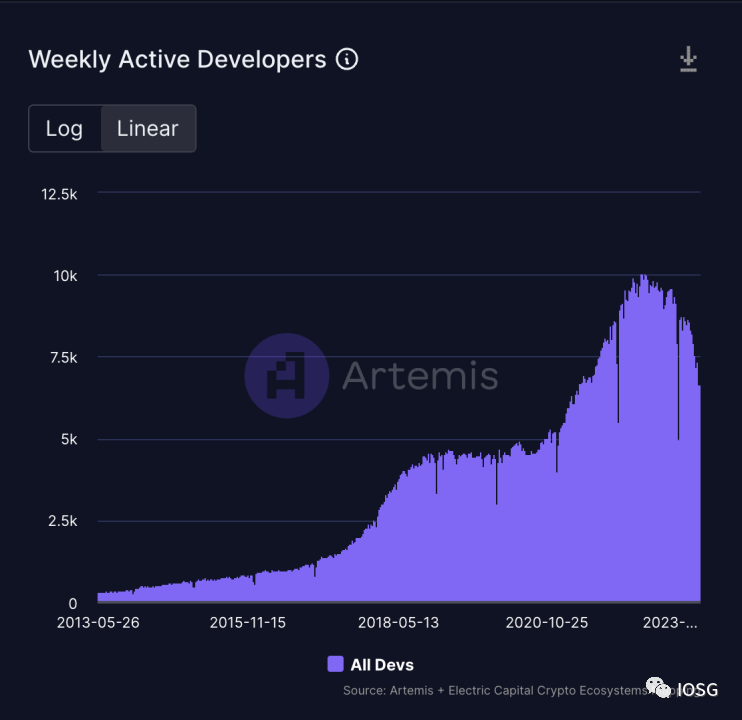
(출처:https://app.artemis.xyz/developers)
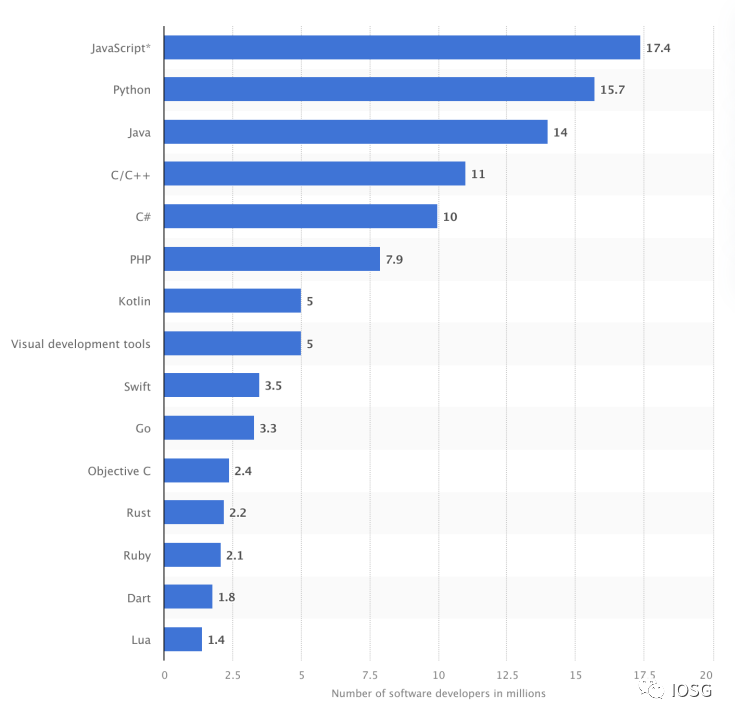
(출처:https://www.statista.com/statistics/1241923/worldwide-software-developer-programming-language-communities)
위의 통계 데이터에 따르면, Web3 환경을 개발자에게 더 적합하게 변형하는 것이 새로운 Web3 개발 환경으로 개발자를 유입하는 것보다 지속 가능성이 더 높아 보입니다.
만약 ZK가 Web3의 미래라면, Web3 애플리케이션은 기존 개발자 기술을 사용하여 구축해야 하므로, ZK 회로는 JavaScript나 Rust와 같은 언어로 작성된 알고리즘 실행을 지원하도록 설계되어야 합니다.
이러한 솔루션은 실제로 존재하며, 필자는 두 팀인 RiscZero와 Lurk Labs를 떠올립니다. 두 팀 모두 개발자가 가파른 학습 곡선을 겪지 않고도 zk-app을 구축할 수 있도록 허용하는 매우 유사한 비전을 가지고 있습니다.
Lurk Labs는 아직 초기 단계에 있지만, 이 팀은 이 프로젝트에 오랫동안 작업해 왔습니다. 그들은 일반 회로를 통해 Nova 증명(Nova Proof)을 생성하는 데 집중하고 있습니다. Nova 증명은 카네기 멜론 대학교의 Abhiram Kothapalli, 마이크로소프트 연구소의 Srinath Setty, 뉴욕 대학교의 Ioanna Tziallae가 제안한 것입니다. 다른 SNARK 시스템과 비교할 때, Nova 증명은 증분 검증 가능한 계산(IVC)에서 특별한 장점을 가지고 있습니다. 증분 검증 가능한 계산(IVC)은 컴퓨터 과학과 암호학에서 계산의 검증을 달성하기 위해 설계된 개념으로, 전체 계산을 처음부터 다시 계산할 필요 없이 이루어집니다. 계산 시간이 길고 복잡할 때, IVC에 대한 증명을 최적화해야 합니다.
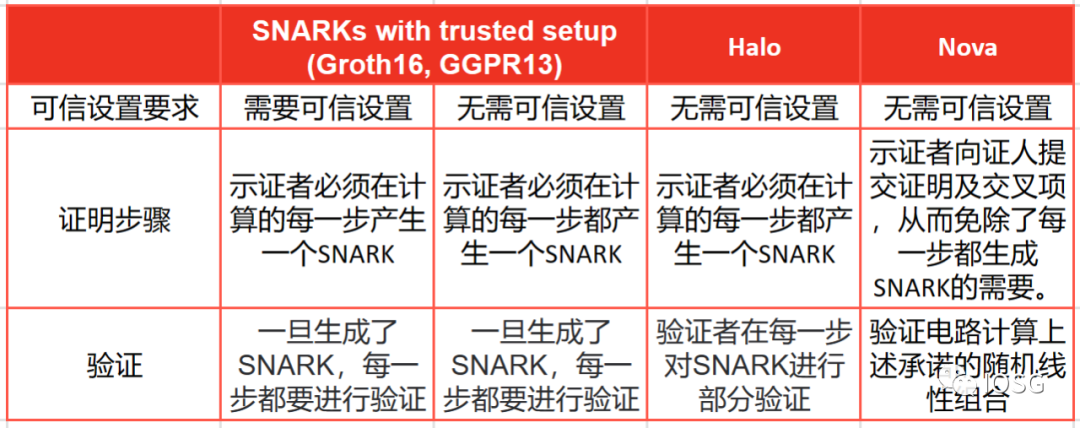
(출처:IOSG Ventures)
Nova 증명은 다른 증명 시스템처럼 "즉시 사용 가능"하지 않으며, Nova는 단지 접기 기술일 뿐입니다. 개발자는 여전히 증명을 생성하기 위한 증명 시스템이 필요합니다. 이것이 Lurk Labs가 Lurk Lang을 구축한 이유입니다. 이는 LISP 구현입니다. LISP는 저수준 언어이기 때문에 일반 회로에서 증명을 생성하기가 쉽고, JavaScript로 변환하기도 용이합니다. 이는 Lurk Labs가 1740만 명의 JavaScript 개발자 지원을 얻는 데 도움이 될 것입니다. 또한 Python과 같은 다른 일반 언어의 변환도 지원합니다.
결론적으로, Nova 증명은 훌륭한 원시 증명 시스템으로 보입니다. 비록 그들의 단점은 증명의 크기가 계산 크기에 따라 선형적으로 증가하지만, 반면에 Nova 증명은 추가 압축 공간이 있습니다.
STARK 증명의 크기는 계산량이 증가함에 따라 증가하지 않으므로, 매우 큰 계산을 검증하는 데 더 적합합니다. 개발자 경험을 더욱 개선하기 위해, 그들은 RiscZero가 생성한 증명으로 검증되는 분산 계산 네트워크인 Bonsai 네트워크를 출시했습니다. 이는 RiscZero의 Bonsai 네트워크의 작동 방식을 나타내는 간단한 도식입니다.
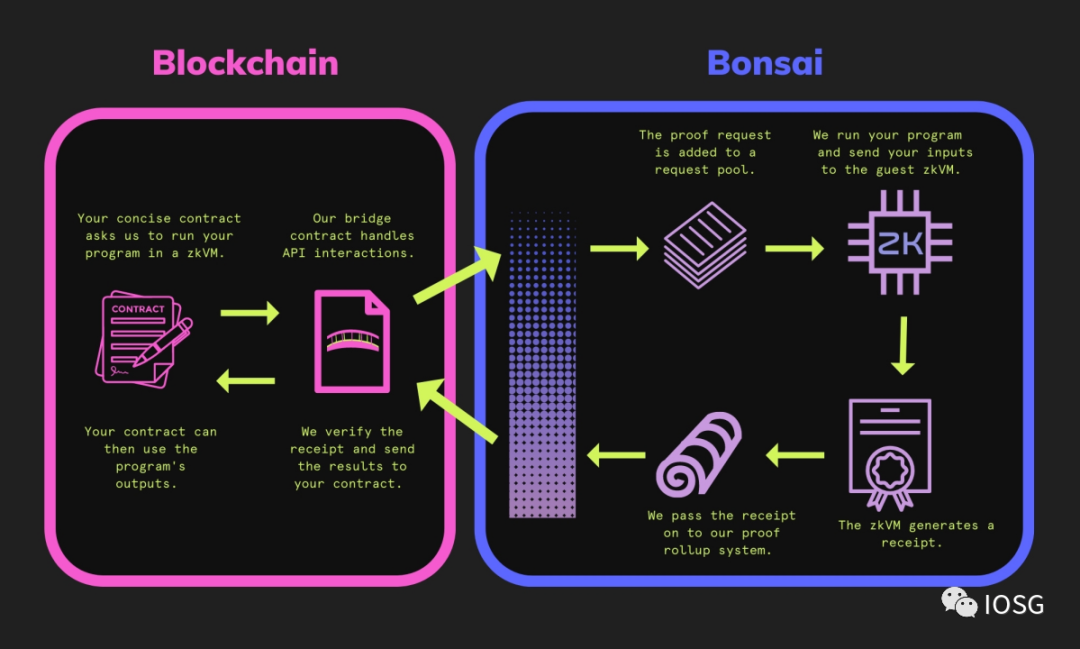
(출처:https://dev.bonsai.xyz/)
Bonsai 네트워크 설계의 아름다움은 계산이 초기화되고, 검증되며, 출력을 모두 체인 상에서 수행할 수 있다는 것입니다. 이 모든 것이 유토피아처럼 들리지만, STARK 증명은 또한 문제를 가져옵니다 - 검증 비용이 너무 높습니다.
Nova 증명은 반복 계산(그의 접기 솔루션이 경제적임)과 소형 계산에 매우 적합해 보이며, 이는 Lurk가 ML 추론 검증의 훌륭한 솔루션이 될 수 있습니다.
승자는 누구인가?


(출처:IOSG Ventures)
일부 zk-SNARK 시스템은 초기 설정 단계에서 신뢰할 수 있는 설정 프로세스가 필요하며, 초기 매개변수 집합을 생성합니다. 여기서의 신뢰 가정은 신뢰할 수 있는 설정이 정직하게 수행되며, 악의적인 행동이나 변조가 없다는 것입니다. 공격을 받으면 무효 증명이 생성될 수 있습니다.
STARK 증명은 다항식의 저차 성질을 검증하기 위해 저차 테스트의 안전성을 가정합니다. 그들은 또한 해시 함수가 무작위 예언자처럼 작동한다고 가정합니다.
두 시스템의 올바른 구현 또한 안전 가정입니다.
SMPC 네트워크는 다음 사항에 의존합니다:
- SMPC 참여자는 "정직하지만 호기심 많은" 참여자를 포함할 수 있으며, 이들은 다른 노드와 통신하여 기본 정보를 접근하려고 시도할 수 있습니다.
- SMPC 네트워크의 안전성은 참여자가 프로토콜을 올바르게 수행하고 고의로 오류나 악의적인 행동을 도입하지 않을 것이라는 가정에 의존합니다.
- 특정 SMPC 프로토콜은 암호 매개변수나 초기 값을 생성하기 위해 신뢰할 수 있는 설정 단계가 필요할 수 있습니다. 여기서의 신뢰 가정은 신뢰할 수 있는 설정이 정직하게 수행된다는 것입니다.
- SMPC 네트워크와 마찬가지로, 안전 가정은 동일하게 유지되지만 OTM(Off-The-Grid Multi-party Computation)의 존재로 인해 "정직하지만 호기심 많은" 참여자는 존재하지 않습니다.
OTM은 참여자의 개인 정보를 보호하기 위해 설계된 다자 계산 프로토콜입니다. 이는 참여자가 계산 중 자신의 입력 데이터를 공개하지 않도록 함으로써 개인 정보 보호를 실현합니다. 따라서 "정직하지만 호기심 많은" 참여자는 존재하지 않으며, 그들은 다른 노드와 통신하여 기본 정보를 접근하려고 시도할 수 없습니다.
명확한 승자가 있는가? 우리는 모릅니다. 그러나 각 방법은 고유한 장점을 가지고 있습니다. NMC는 SMPC의 명백한 업그레이드처럼 보이지만, 해당 네트워크는 아직 온라인이 아니며 실전 테스트를 거치지 않았습니다.
ZK 검증 가능한 계산을 사용하는 이점은 그것이 안전하고 개인 정보를 보호하지만, 내장된 비밀 공유 기능이 없다는 것입니다. 증명 생성과 검증 간의 비대칭성은 그것을 검증 가능한 외주 계산의 이상적인 모델로 만듭니다. 시스템이 순수한 zk 검증 계산을 사용한다면, 컴퓨터(또는 단일 노드)는 대량의 계산을 수행하기 위해 매우 강력해야 합니다. 개인 정보를 보호하면서 부하 공유와 균형을 활성화하기 위해서는 비밀 공유가 필요합니다. 이 경우 SMPC나 NMC와 같은 시스템은 Lurk나 RiscZero와 같은 zk 생성기와 결합하여 강력한 분산 검증 가능한 외주 계산 인프라를 구축할 수 있습니다.
오늘날의 MPC/SMPC 네트워크는 중앙 집중화되어 있으며, 이는 특히 중요합니다. 현재 가장 큰 MPC 제공자는 Sharemind이며, 그 위의 ZK 검증 계층은 유용하다는 것을 증명할 수 있습니다. 탈중앙화된 MPC 네트워크의 경제 모델은 아직 실행되지 않았습니다. 이론적으로 NMC 모델은 MPC 시스템의 업그레이드이지만, 우리는 아직 그 성공을 보지 못했습니다.
ZK 증명 솔루션의 경쟁에서, 승자가 독식하는 상황은 발생하지 않을 것입니다. 각 증명 방법은 특정 유형의 계산에 최적화되어 있으며, 모든 유형의 모델에 적합한 것은 없습니다. 계산 작업의 유형은 다양하며, 각 증명 시스템에서 개발자가 내리는 균형에 따라 달라집니다. 필자는 STARK 기반 시스템과 SNARK 기반 시스템 및 그들의 미래 최적화가 ZK의 미래에서 한 자리를 차지할 것이라고 생각합니다.
 위험 경고
위험 경고 위험 경고
위험 경고












