Geth 소스 코드 시리즈: 저장 설계 및 구현

 본 시리즈는 총 여섯 편의 글로 구성되어 있으며, 두 번째 편에서는 Geth의 저장 구조 설계와 관련 소스 코드를 체계적으로 설명하고, 데이터베이스 계층 구성을 소개하며 각 계층의 해당 모듈의 핵심 기능을 상세히 분석합니다.
본 시리즈는 총 여섯 편의 글로 구성되어 있으며, 두 번째 편에서는 Geth의 저장 구조 설계와 관련 소스 코드를 체계적으로 설명하고, 데이터베이스 계층 구성을 소개하며 각 계층의 해당 모듈의 핵심 기능을 상세히 분석합니다.저자: po, LXDAO
이더리움은 세계에서 가장 큰 블록체인 플랫폼으로, 주류 클라이언트 Geth(Go-Ethereum)는 대부분의 노드 운영 및 상태 관리의 책임을 맡고 있습니다. Geth의 상태 저장 시스템은 이더리움 운영 메커니즘을 이해하고, 노드 성능을 최적화하며, 미래 클라이언트 혁신을 추진하는 기초입니다.
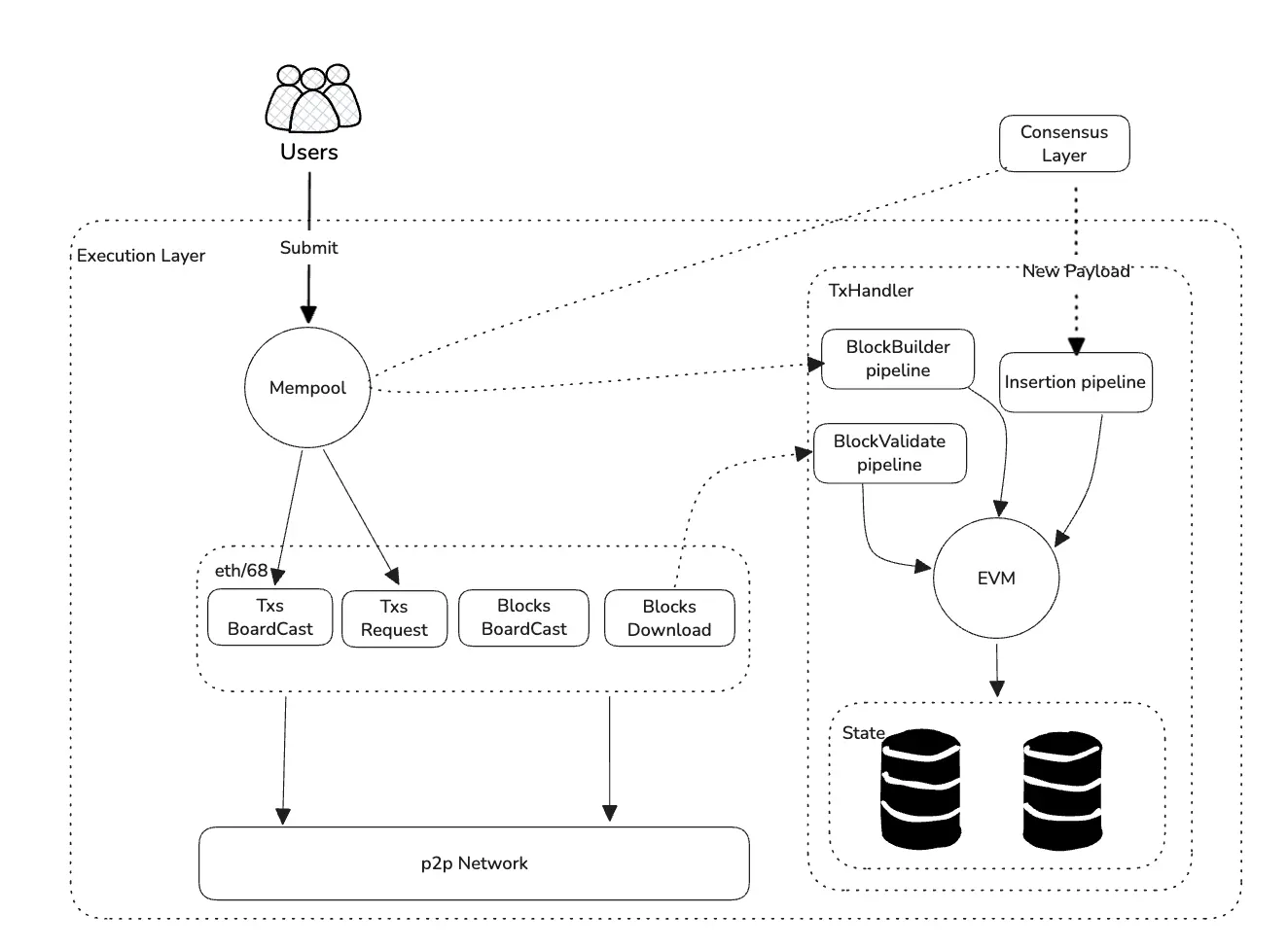
1. Geth 저수준 데이터베이스 개요
Geth v1.9.0 버전부터 Geth는 데이터베이스를 두 부분으로 나누었습니다: 빠른 접근 저장소 (KV 데이터베이스, 최근 블록 및 상태 데이터용)와 freezer 저장소 (구형 블록 및 영수증 데이터용, 즉 "ancients").
이러한 구분의 목적은 비싼 SSD에 대한 의존도를 줄이고, 접근 빈도가 낮은 데이터를 더 저렴하고 내구성이 높은 디스크로 이동하는 것입니다. 동시에 이러한 분할은 LevelDB/PebbleDB의 압박을 줄이고 정리 및 읽기 성능을 향상시켜, 주어진 캐시 크기에서 더 많은 상태 트리 노드가 메모리에 상주할 수 있도록 하여 전체 시스템 효율성을 높입니다.
빠른 접근 저장소: Geth 사용자는 저수준 데이터베이스 옵션에 익숙할 수 있습니다 ------
--db.engine매개변수를 통해 구성할 수 있습니다. 현재 기본 옵션은pebbledb이며,leveldb를 선택할 수도 있습니다. 이 두 가지는 Geth가 의존하는 제3자 키-값 데이터베이스로, 저장 경로는datadir/geth/chaindata(모든 블록 및 상태 데이터)와datadir/geth/nodes(데이터베이스 메타데이터 파일, 크기가 매우 작음)입니다.--history.state value를 통해 빠른 접근 저장소에 저장되는 최근 역사 상태 블록 수를 설정할 수 있으며, 기본값은 90,000 블록입니다.freezer 또는 ancients 저장소 (역사 데이터)는 일반적으로
datadir/geth/chaindata/ancients경로에 있습니다. 역사 데이터는 기본적으로 정적이므로 고성능 I/O가 필요하지 않으며, 더 활발한 데이터를 저장하기 위해 귀중한 SSD 공간을 절약할 수 있습니다.
이 문서의 초점은 KV 데이터베이스에 저장된 상태 데이터입니다. 따라서 본문에서 언급하는 저수준 데이터베이스는 기본적으로 이 KV 저장소를 의미하며, freezer는 아닙니다.
Geth 저장 구조: 다섯 개의 논리 데이터베이스
Geth의 저수준은 LevelDB/PebbleDB를 사용하여 모든 RLP로 인코딩된 데이터를 저장하지만, 논리적으로 다섯 가지 용도로 구분된 데이터베이스를 가지고 있습니다:
| 이름 | 설명 | |----------------|----------------| | 상태 트리 | 세계 상태, 계좌, 계약 저장 | | 계약 코드 | 계약 코드 | | 상태 스냅샷 | 세계 상태 스냅샷 | | 영수증 | 거래 영수증 | | 헤더/블록 | 블록 데이터 |
각 데이터는 키 접두사(core/rawdb/schema.go)를 통해 구분되어 논리적으로 책임 분리가 이루어집니다. geth db inspect를 통해 Geth가 저장한 모든 이더리움 데이터(블록 높이 22,347,000)를 확인할 수 있으며, 디스크 공간에서 가장 많이 차지하는 것은 블록, 영수증 및 상태 데이터입니다.
+-----------------------+-----------------------------+------------+------------+
| DATABASE | CATEGORY | SIZE | ITEMS |
+-----------------------+-----------------------------+------------+------------+
| Key-Value store | Headers | 576.00 B | 1 |
| Key-Value store | Bodies | 44.00 B | 1 |
| Key-Value store | Receipt lists | 42.00 B | 1 |
| Key-Value store | Difficulties (deprecated) | 0.00 B | 0 |
| Key-Value store | Block number->hash | 42.00 B | 1 |
| Key-Value store | Block hash->number | 873.78 MiB | 22347001 |
| Key-Value store | Transaction index | 13.48 GiB | 391277094 |
| Key-Value store | Log index filter-map rows | 12.98 GiB | 132798523 |
| Key-Value store | Log index last-block-of-map | 2.73 MiB | 59529 |
| Key-Value store | Log index block-lv | 45.05 MiB | 2362175 |
| Key-Value store | Log bloombits (deprecated) | 0.00 B | 0 |
| Key-Value store | Contract codes | 9.81 GiB | 1587159 |
| Key-Value store | Hash trie nodes | 0.00 B | 0 |
| Key-Value store | Path trie state lookups | 19.62 KiB | 490 |
| Key-Value store | Path trie account nodes | 45.88 GiB | 397626541 |
| Key-Value store | Path trie storage nodes | 176.23 GiB | 1753966511 |
| Key-Value store | Verkle trie nodes | 0.00 B | 0 |
| Key-Value store | Verkle trie state lookups | 0.00 B | 0 |
| Key-Value store | Trie preimages | 0.00 B | 0 |
| Key-Value store | Account snapshot | 13.34 GiB | 290797237 |
| Key-Value store | Storage snapshot | 93.42 GiB | 1295163402 |
| Key-Value store | Beacon sync headers | 622.00 B | 1 |
| Key-Value store | Clique snapshots | 0.00 B | 0 |
| Key-Value store | Singleton metadata | 1.36 MiB | 20 |
| Ancient store (Chain) | Hashes | 809.85 MiB | 22347001 |
| Ancient store (Chain) | Bodies | 639.98 GiB | 22347001 |
| Ancient store (Chain) | Receipts | 244.19 GiB | 22347001 |
| Ancient store (Chain) | Headers | 10.69 GiB | 22347001 |
| Ancient store (State) | History.Meta | 37.58 KiB | 487 |
| Ancient store (State) | Account.Index | 5.80 MiB | 487 |
| Ancient store (State) | Storage.Index | 7.47 MiB | 487 |
| Ancient store (State) | Account.Data | 6.46 MiB | 487 |
| Ancient store (State) | Storage.Data | 2.70 MiB | 487 |
+-----------------------+-----------------------------+------------+------------+
| TOTAL | 1.23 TIB | |
+-----------------------+-----------------------------+------------+------------+
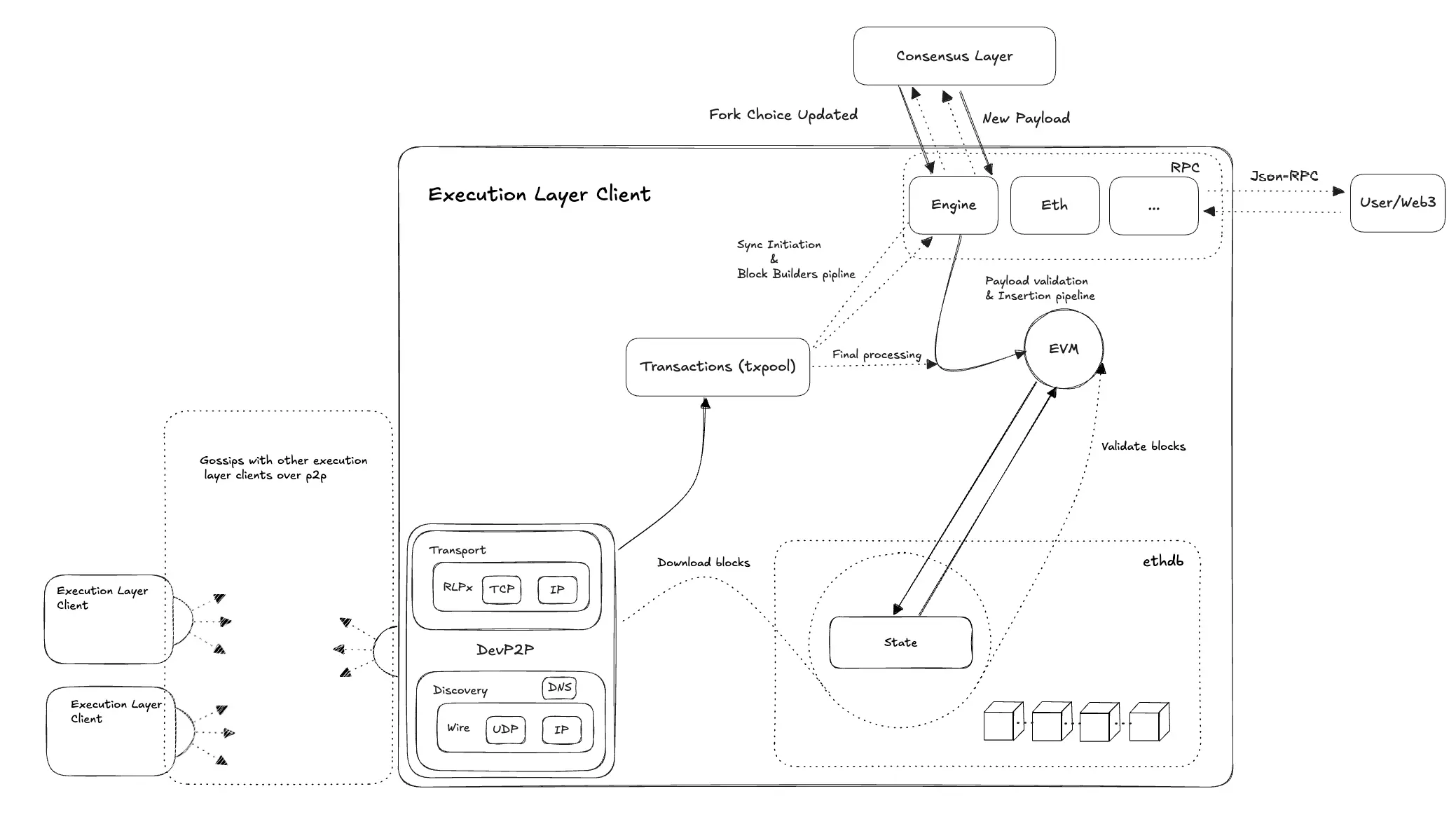
2. 소스 코드 관점에서의 저장소 계층: 6종 DB
전반적으로 Geth에는 StateDB, state.Database, trie.Trie, TrieDB, rawdb 및 ethdb의 여섯 개 데이터베이스 모듈이 포함되어 있으며, 이들은 마치 "상태 생명 나무"의 각 계층과 같습니다. 가장 상위의 StateDB는 EVM 실행 단계의 상태 인터페이스로, 계좌 및 저장소의 읽기 및 쓰기 요청을 처리하며, 이러한 요청을 단계별로 하위로 전달하여 최하위의 물리적 지속성을 담당하는 ethdb가 물리 데이터베이스를 읽고 씁니다.
다음으로, 이 여섯 개 데이터베이스 모듈의 책임 및 이들 간의 협력 관계를 차례로 소개하겠습니다.

2.1 StateDB
Geth에서 StateDB는 EVM과 저수준 상태 저장소 간의 유일한 다리로, 계약 계좌, 잔액, nonce, 저장 슬롯 등의 정보의 읽기 및 쓰기를 추상화하고 관리하며, 모든 다른 데이터베이스(TrieDB, EthDB)의 상태 관련 읽기 및 쓰기는 StateDB의 관련 인터페이스에 의해 촉발됩니다. 즉, StateDB는 모든 상태 데이터베이스의 두뇌라고 할 수 있습니다. 그것은 저수준의 Trie 또는 저수준 데이터베이스(ethdb)를 직접 조작하지 않고, EVM이 익숙한 계좌 모델로 상호작용할 수 있도록 단순화된 메모리 뷰를 제공합니다. 따라서 Geth에 의존하는 대부분의 프로젝트는 저수준의 EthDB 또는 TrieDB가 어떻게 구현되었는지에 대해 신경 쓰지 않습니다 ------ 그들이 정상적으로 작동하기만 하면 충분하며, 수정할 필요가 없습니다. Geth 기반의 분기 프로젝트는 대부분 자신의 비즈니스 논리에 맞게 StateDB 구조를 수정합니다. 예를 들어, Arbitrum은 그들의 Stylus 프로그램을 관리하기 위해 StateDB를 수정했으며, EVMOS는 상태 있는 프리컴파일 계약(stateful precompile)에 대한 호출을 추적하기 위해 StateDB를 수정했습니다.
소스 코드에서 StateDB의 주요 정의는 core/state/statedb.go에 위치하고 있습니다. 그것의 핵심 구조는 일련의 메모리 상태 객체(stateObject)를 유지하며, 각 stateObject는 하나의 계좌(계약 저장소 포함)에 해당합니다. 또한 롤백을 지원하기 위한 journal(트랜잭션 로그)과 상태 변경을 추적하기 위한 캐시 메커니즘을 포함하고 있습니다. 거래 처리 및 블록 패키징 과정에서 StateDB는 임시 상태 변경의 기록을 제공하며, 최종 확인 후에만 저수준 데이터베이스에 기록됩니다.
StateDB의 핵심 읽기 및 쓰기 인터페이스는 다음과 같으며, 기본적으로 계좌 모델 관련 API입니다:
// 읽기 관련
func (s *StateDB) GetBalance(addr common.Address) *uint256.Int
func (s *StateDB) GetStorageRoot(addr common.Address) common.Hash
// 더러운 상태 데이터 쓰기
func (s *StateDB) SetStorage(addr common.Address, storage map[common.Hash]common.Hash)
// EVM 실행 과정에서 발생한 상태 변경(더러운 데이터)을 백엔드 데이터베이스에 커밋
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error)
생명 주기
StateDB의 생명 주기는 단 하나의 블록에만 지속됩니다. 하나의 블록이 처리되고 제출된 후, 이 StateDB는 폐기되어 더 이상 작동하지 않습니다.
EVM이 특정 주소를 처음 읽을 때,
StateDB는Trie→TrieDB→EthDB데이터베이스에서 값을 로드하고, 새로운 상태 객체(stateObject.originalStorage)에 캐시합니다. 이 단계는 "깨끗한 객체" (clean object)로 간주됩니다.거래가 해당 계좌와 상호작용하고 상태를 변경하면 객체는 "더러운" (dirty) 상태로 변합니다.
stateObject는 해당 계좌의 원래 상태와 모든 수정된 데이터를 추적하며, 저장 슬롯 및 깨끗한/더러운 상태를 포함합니다.만약 전체 거래가 최종적으로 블록에 패키징되면,
StateDB.Finalise()가 호출됩니다. 이 함수는selfdestruct된 계약을 정리하고, 저널(트랜잭션 로그) 및 가스 환불 카운터를 재설정하는 역할을 합니다.모든 거래가 완료된 후,
StateDB.Commit()가 호출됩니다. 이 이전에는 상태 트리Trie가 실제로 변경되지 않습니다. 이 단계에서야StateDB는 메모리 내의 상태 변경을 저장Trie에 기록하고, 각 계좌의 최종 storage root를 계산하여 계좌의 최종 상태를 생성합니다. 그 후, 모든 "더러운" 상태 객체는Trie에 기록되어 구조를 업데이트하고 새로운stateRoot를 계산합니다.마지막으로, 이러한 업데이트된 노드는
TrieDB로 전달되며, 이는 다양한 백엔드(PathDB/HashDB)에 따라 이러한 노드를 캐시하고 최종적으로 디스크(LevelDB/PebbleDB)에 지속화합니다 ------ 단, 이러한 데이터가 체인 재구성으로 인해 삭제되지 않는 한입니다.
2.2 State.Database
state.Database는 Geth에서 StateDB와 저수준 데이터베이스(EthDB 및 TrieDB)를 연결하는 중요한 중간 계층으로, 상태 접근을 위한 간결한 인터페이스와 유용한 메서드를 제공합니다. 비록 인터페이스가 비교적 얇지만, 소스 코드에서 여러 중요한 역할을 수행하며, 특히 상태 트리 접근 및 최적화 측면에서 그렇습니다.
Geth 소스 코드에서(core/state/database.go), state.Database 인터페이스는 state.cachingDB라는 구체적인 데이터 구조에 의해 구현됩니다. 그 주요 역할은 다음과 같습니다:
- 통합된 상태 접근 인터페이스 제공
state.Database는 StateDB를 구축하는 데 필요한 의존성으로, 계좌 Trie 및 저장 Trie를 여는 논리를 캡슐화합니다. 예를 들어:
func (db *cachingDB) OpenTrie(root common.Hash) (Trie, error)
func (db *cachingDB) OpenStorageTrie(stateRoot common.Hash, address common.Address, root common.Hash, trie Trie) (Trie, error)
이러한 메서드는 저수준 TrieDB의 복잡성을 숨기며, 개발자는 특정 블록의 상태를 구축할 때 이러한 메서드를 호출하여 올바른 Trie 인스턴스를 얻으면 되며, 해시 경로, trie 인코딩 또는 저수준 데이터베이스를 직접 조작할 필요가 없습니다.
- 계약 코드의 임시 저장 및 재사용 (code cache)
계약 코드의 접근 비용이 높고, 종종 여러 블록에서 반복 사용됩니다. 이를 위해 state.Database에서는 코드 캐시 로직을 구현하여 계약 바이트코드를 디스크에서 반복적으로 로드하는 것을 방지합니다. 이 최적화는 블록 실행 효율성을 높이는 데 매우 중요합니다:
func (db *CachingDB) ContractCodeWithPrefix(address common.Address, codeHash common.Hash) []byte
이 인터페이스는 주소와 코드 해시를 기준으로 캐시를 빠르게 적중할 수 있게 하며, 적중하지 않을 경우에만 저수준 데이터베이스에서 로드합니다.
- 긴 생명 주기, 여러 블록 간 재사용
StateDB의 생명 주기가 단일 블록에 국한되는 것과 달리, state.Database의 생명 주기는 전체 체인(core.Blockchain)과 일치합니다. 이는 노드 시작 시 구성되며, 전체 실행 주기 동안 지속되며, StateDB의 "충실한 파트너"로서 각 블록 처리 시 지원을 제공합니다.
- 미래 Verkle Tree 마이그레이션 준비
현재 state.Database는 단순히 "코드 캐시 + trie 접근 캡슐화"처럼 보이지만, Geth 아키텍처에서의 위치는 매우 미래 지향적입니다. 향후 상태 구조가 Verkle Trie로 전환되면, 이는 마이그레이션 과정의 핵심 구성 요소가 되어 새旧 구조 간의 브리지 상태를 처리하게 됩니다.
2.3 Trie
Geth에서 상태 트리 Trie(Merkle Patricia Trie)는 데이터 자체를 저장하지 않지만, 상태 루트 해시를 계산하고 수정된 노드를 수집하는 핵심 책임을 맡고 있으며, StateDB와 저수준 저장소 간의 연결 역할을 합니다. 이는 이더리움 상태 시스템의 중심 구조입니다.
EVM이 거래를 실행하거나 계약을 호출할 때, 저수준 데이터베이스를 직접 조작하지 않고 StateDB를 통해 간접적으로 Trie와 상호작용합니다. Trie는 계좌 주소 및 저장 슬롯의 조회 및 업데이트 요청을 수신하고, 메모리 내에서 상태 변화 경로를 구축합니다. 이러한 경로는 최종적으로 재귀 해시 연산을 통해 아래에서 위로 새로운 루트 해시(state root)를 생성하며, 이 루트 해시는 현재 세계 상태의 유일한 식별자로 블록 헤더에 기록되어 상태의 완전성과 검증 가능성을 보장합니다.
하나의 블록이 실행되고 제출 단계(StateDB.Commit)에 들어가면, Trie는 모든 수정된 노드를 "축소"하여 필요한 하위 집합으로 만들어 TrieDB에 전달하며, 이는 후속적으로 백엔드 노드 데이터베이스(예: HashDB 또는 PathDB)에 지속화됩니다. Trie 노드는 구조화된 형태로 인코딩되어 있어 효율적인 읽기를 지원하며, 상태가 서로 다른 노드 간에 안전하게 동기화되고 검증될 수 있도록 합니다. 따라서 Trie는 단순한 상태 컨테이너가 아니라 상위 EVM과 저수준 저장 엔진 간의 연결 고리로, 이더리움 상태의 일관성, 안전성 및 모듈화 확장성을 제공합니다.
소스 코드에서 Trie는 주로 trie/trie.go에 위치하며, 다음과 같은 핵심 인터페이스를 제공합니다:
type Trie interface {
GetKey([]byte) []byte
GetAccount(address common.Address) (*types.StateAccount, error)
GetStorage(addr common.Address, key []byte) ([]byte, error)
UpdateAccount(address common.Address, account *types.StateAccount, codeLen int) error
UpdateStorage(addr common.Address, key, value []byte) error
DeleteAccount(address common.Address) error
DeleteStorage(addr common.Address, key []byte) error
UpdateContractCode(address common.Address, codeHash common.Hash, code []byte) error
Hash() common.Hash
Commit(collectLeaf bool) (common.Hash, *trienode.NodeSet)
Witness() map[string]struct{}
NodeIterator(startKey []byte) (trie.NodeIterator, error)
Prove(key []byte, proofDb ethdb.KeyValueWriter) error
IsVerkle() bool
}
노드 쿼리 trie.get의 예를 들면, 이는 노드 유형에 따라 계좌 또는 계약 저장소에 해당하는 노드를 재귀적으로 검색하며, 검색 시간 복잡도는 log(n)이며, n은 경로 깊이입니다.
func (t *Trie) get(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if !bytes.HasPrefix(key[pos:], n.Key) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.get(n.Val, key, pos+len(n.Key))
if err == nil \&\& didResolve {
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.get(n.Children[key[pos]], key, pos+1)
if err == nil \&\& didResolve {
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveAndTrack(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.get(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
2.4 TrieDB
TrieDB는 Trie와 디스크 저장소 간의 중간 계층으로, Trie 노드의 접근 및 지속화에 집중합니다. 각 Trie 노드(계좌 정보 또는 계약의 저장 슬롯)는 최종적으로 TrieDB를 통해 읽고 씁니다.
프로그램 시작 시 TrieDB 인스턴스가 생성되며, 노드가 종료될 때 파괴됩니다. 초기화 시 EthDB 인스턴스를 전달해야 하며, EthDB 인스턴스는 구체적인 데이터 지속화 작업을 담당합니다.
현재 Geth는 두 가지 TrieDB 백엔드 구현을 지원합니다:
HashDB: 전통적인 방식으로 해시를 키로 사용합니다.
PathDB: 새롭게 도입된 경로 기반 모델(Geth 1.14.0 버전 이후 기본 구성)로, 경로 정보를 키로 사용하여 업데이트 및 가지치기 성능을 최적화합니다.
소스 코드에서 TrieDB는 주로 triedb/database.go에 위치합니다.
Trie 노드의 읽기 로직
우선 노드의 읽기 프로세스를 살펴보겠습니다. 이는 상대적으로 간단합니다.
모든 TrieDB 백엔드는 database.Reader 인터페이스를 구현해야 하며, 그 정의는 다음과 같습니다:
type Reader interface {
Node(owner common.Hash, path []byte, hash common.Hash) ([]byte, error)
}
이 인터페이스는 기본적인 노드 쿼리 기능을 제공하며, 경로(path)와 노드 해시(hash)를 기반으로 trie 트리에서 해당 노드를 찾고 반환합니다. 주의할 점은 반환되는 것이 원시 바이트 배열이라는 것입니다 ------ TrieDB는 노드의 내용에 대해 신경 쓰지 않으며, 그것이 계좌 노드인지, 리프 노드인지, 분기 노드인지도 모릅니다(이는 상위 Trie가 해석합니다).
인터페이스의 owner 매개변수는 서로 다른 trie를 구분하는 데 사용됩니다:
계좌 trie인 경우,
owner는 비워 둡니다.계약의 저장 trie인 경우,
owner는 해당 계약의 주소입니다. 각 계약은 독립적인 저장 trie를 가지고 있기 때문입니다.
즉, TrieDB는 저수준 노드의 읽기 및 쓰기 버스로, 상위 Trie에 통합된 인터페이스를 제공하며, 의미와는 무관하게 경로와 해시에만 신경을 씁니다. 이는 Trie와 물리 저장 시스템 간의 결합을 해제하여 서로 다른 저장 모델이 상위 논리에 영향을 주지 않고 유연하게 교체될 수 있게 합니다.
TrieDB의 HashDB
TrieDB가 역사적으로 채택한 노드 지속화 방식은:
각 Trie 노드의 해시(Keccak256)를 키로 하고, 해당 노드의 RLP 인코딩을 값으로 하여 저수준 키-값 저장소에 기록하는 방식입니다. 이 방식은 현재 HashDB로 알려져 있습니다.
이 설계 방식은 매우 직접적이지만 몇 가지 뚜렷한 장점이 있습니다:
여러 Trie의 공존 지원: 루트 해시만 알면 전체 Trie를 탐색하여 복구할 수 있습니다. 각 계좌의 저장소, 계좌 Trie, 서로 다른 역사 상태의 루트 해시는 각각 관리할 수 있습니다.
서브트리 중복 제거 (Subtrie Deduplication): 동일한 서브트리는 동일한 구조와 노드 해시를 가지므로
HashDB에서 자연스럽게 공유되며, 중복 저장할 필요가 없습니다. 이는 이더리움의 큰 상태 트리에 특히 중요합니다. 대부분의 상태는 블록 간에 변하지 않기 때문입니다.
주의할 점은, 일반 Geth 노드는 각 블록 후에 Trie를 완전히 디스크에 기록하지 않습니다. 이러한 완전한 지속화는 "아카이브 모드"(--gcmode archive)에서만 발생하며, 대부분의 메인넷 노드는 아카이브 모드를 사용하지 않습니다.
그렇다면 일반 모드에서 상태는 어떻게 디스크에 기록될까요? 실제로 상태 업데이트는 먼저 메모리에 캐시되고, 디스크에 지연 기록됩니다. 이 메커니즘을 "지연 플러시" (delayed flush)라고 하며, 트리거 조건은 다음과 같습니다:
⏱️ 정기 플러시: 기본적으로 5분마다(약 5분 내에 처리된 블록 수에 해당) 자동으로 기록됩니다.
💾 캐시 용량이 한계에 도달: 상태 캐시가 가득 차면 메모리를 해제하기 위해 플러시해야 합니다.
⛔ 노드 종료 시: 데이터 완전성을 위해 모든 캐시가 플러시됩니다.
비록 HashDB의 구조 설계가 매우 간단하지만, 메모리 관리 측면에서 매우 복잡합니다. 특히 무효 노드의 가비지 수집 메커니즘이 그렇습니다: 특정 계약이 하나의 블록에서 생성되고, 다음 블록에서 파괴되는 경우 ------ 이때 해당 계약과 관련된 상태 노드(계약 계좌 및 독립적인 저장 Trie 포함)는 더 이상 필요하지 않게 됩니다. 이를 정리하지 않으면 메모리를 불필요하게 차지하게 됩니다. 따라서 HashDB는 참조 카운트 및 노드 사용 추적 메커니즘을 설계하여 어떤 노드가 더 이상 사용되지 않는지 판단하고 캐시에서 제거합니다.
TrieDB의 PathDB
PathDB는 TrieDB의 새로운 백엔드 구현입니다. 이는 Trie 노드가 디스크에 지속화되고 메모리에서 유지되는 방식을 변경했습니다. 앞서 언급했듯이, HashDB는 노드의 해시를 통해 인덱스 저장합니다. 그러나 이 방법은 상태에서 더 이상 사용되지 않는 부분을 제거하는 것을 매우 어렵게 만듭니다. 이러한 오랜 문제를 해결하기 위해, Geth는 PathDB를 도입했습니다.
PathDB와 HashDB는 몇 가지 뚜렷한 차이점이 있습니다:
- Trie 노드는 데이터베이스에서 경로(path)를 키로 저장됩니다. 특정 계좌 또는 저장 키 노드의 경로는 해당 계좌 주소 해시 또는 저장 키가 trie 트리에서 다른 노드와 공유하는 접두사 부분입니다. 특정 계약의 저장 Trie 내 노드의 경우, 경로 접두사에는 해당 계좌 주소 해시가 포함됩니다.
account trie node key = Prefix(1byte) || COMPACTED(nodepath) storage trie node key = Prefix(1byte) || account hash(32byte) || COMPACTed(nodepath)
HashDB는 각 블록의 전체 상태를 정기적으로 플러시합니다. 이는 사용자가 신경 쓰지 않는 구형 블록이라도 전체 상태가 남아 있게 됩니다. 반면PathDB는 항상 디스크에 하나의 Trie만 유지합니다. 각 블록은 동일한 Trie만 업데이트합니다. 경로를 키로 사용하기 때문에 노드의 수정은 이전 노드를 덮어쓰는 것만으로 충분합니다. 제거된 노드는 안전하게 삭제할 수 있습니다. 왜냐하면 다른 Trie가 이를 참조하지 않기 때문입니다.지속화된 이 Trie는 체인의 최신 헤드가 아니라, 헤드보다 최소 128 블록 이상 뒤쳐져 있습니다. 최근 128 블록의 Trie 변경은 메모리 내에 존재하여 짧은 체인 재구성(reorg)에 대응합니다.
더 큰 재구성이 발생하면,
PathDB는 freezer에 미리 저장된 각 블록의 상태 차이(state diff)를 사용하여 역으로 적용(rollback)하여 디스크 상태를 분기점으로 되돌립니다.
2.5 RawDB
Geth에서 rawdb는 저수준 데이터베이스 읽기 및 쓰기 모듈로, 상태, 블록체인 데이터, Trie 노드 등의 핵심 데이터 접근 논리를 직접 캡슐화하며, 전체 저장 시스템의 기본 인터페이스 계층입니다. 이는 EVM이나 비즈니스 논리 계층에 직접 노출되지 않으며, TrieDB, StateDB, BlockChain 등의 모듈의 지속화 작업을 위한 내부 도구로 작용합니다. rawdb와 trie는 데이터 자체를 직접 저장하지 않으며, 둘 다 저수준 데이터베이스에 대한 추상화된 캡슐화 계층으로, 접근 규칙을 정의하는 역할을 하며, 최종 데이터 기록이나 읽기를 실행하지 않습니다. rawdb는 Geth의 "하드 드라이브"로 볼 수 있으며, 모든 핵심 체인 데이터의 키-값 형식 및 접근 인터페이스를 정의하고, 서로 다른 모듈이 통일되고 신뢰할 수 있게 데이터를 읽고 쓸 수 있도록 보장합니다. 직접 개발에서는 거의 사용되지 않지만, 전체 Geth 저장 계층에서 가장 기본적이고 중요한 부분입니다.
핵심 기능
소스 코드에서 rawdb는 주로 core/rawdb/accessors_trie.go에 위치합니다. rawdb는 다양한 ReadXxx 및 WriteXxx 등의 읽기 및 쓰기 메서드를 제공하여 서로 다른 유형의 데이터에 표준화된 접근을 가능하게 합니다. 예를 들어:
블록 데이터(
core/rawdb/accessors_chain.go):ReadBlock,WriteBlock,ReadHeader등상태 데이터(
core/rawdb/accessors_trie.go):WriteLegacyTrieNode,ReadTrieNode등전체 메타데이터: 총 난이도, 최신 헤드 블록 해시, 제네시스 정보 등
이러한 메서드는 일반적으로 약정된 키 접두사(예: h는 헤더, b는 블록, a는 AccountTrieNode를 나타냄)를 사용하여 저수준 데이터베이스(LevelDB 또는 PebbleDB)에서 데이터를 조직합니다.
TrieDB와의 관계
TrieDB는 실제로 하드 드라이브를 직접 조작하지 않으며, 구체적인 읽기 및 쓰기를 rawdb에 위임합니다. 그리고 rawdb는 더 저수준의 ethdb.KeyValueStore 인터페이스를 호출하며, 이는 LevelDB, PebbleDB 또는 메모리 데이터베이스일 수 있습니다. 예를 들어, Trie 관련 데이터를(계좌, 저장 슬롯 등) 기록할 때:
HashDB기반의 Trie 노드는rawdb.WriteLegacyTrieNode등의 메서드를 사용하여(hash, rlp-encoded node)형태로 데이터베이스에 기록합니다.PathDB기반의 Trie 노드는WriteAccountTrieNode,WriteStorageTrieNode등의 메서드를 사용하여(path, rlp-encoded node)형태로 데이터베이스에 기록합니다.
2.6 EthDB
Geth에서 ethdb는 전체 저장 시스템의 핵심 추상화로, "생명 나무"의 역할을 하며 ------ 디스크에 깊이 뿌리를 내리고, EVM 및 실행 계층의 각 구성 요소에 지원을 전달합니다. 그 주요 목적은 저수준 데이터베이스 구현의 차이를 숨기는 것으로, 전체 Geth에 통일된 키-값 읽기 및 쓰기 인터페이스를 제공합니다. 이 때문에 Geth는 어느 곳에서도 구체적인 데이터베이스(LevelDB, PebbleDB, MemoryDB 등)를 직접 사용하지 않고, ethdb가 제공하는 인터페이스를 통해 데이터에 접근합니다.
인터페이스 추상화 및 책임 분리
소스 코드에서 ethdb는 주로 ethdb/database.go에 위치합니다. ethdb의 가장 핵심 인터페이스는 KeyValueStore()로, 일반적인 키-값 작업 방법을 정의합니다:
type KeyValueStore interface {
Has(key []byte) (bool, error)
Get(key []byte) ([]byte, error)
Put(key []byte, value []byte) error
Delete(key []byte) error
}
이 인터페이스는 매우 간단하며, 기본 읽기 및 쓰기 작업을 포괄합니다. 확장 인터페이스 ethdb.Database는 이 기반 위에 freezer 냉 저장소의 읽기 및 쓰기 지원(AncientStore)을 추가하여 주로 체인 데이터(예: 역사 블록, 거래 영수증)의 관리를 담당합니다: 최근 블록은 KV 저장소에 저장되고, 오래된 블록은 freezer로 이동됩니다.
또한 ethdb는 여러 구체적인 구현 버전을 제공합니다:
LevelDB: 초기 기본 구현으로, 안정적이고 성숙합니다.PebbleDB: 현재 추천하는 기본 구현으로, 더 빠르고 자원 효율이 높습니다.RemoteDB: 원격 상태 접근 시나리오에 사용되며, 경량 노드, 검증자 또는 모듈화 실행 환경에서 특히 중요합니다.MemoryDB: 완전 메모리 구현으로, 주로 개발 모드 및 단위 테스트에 사용됩니다.
이로 인해 Geth는 다양한 시나리오 간에 저장 백엔드를 유연하게 전환할 수 있습니다. 예를 들어, 개발 디버깅 시 MemoryDB를 사용하고, 메인넷에서 PebbleDB를 사용합니다.
생명 주기 및 모듈 통합
각 Geth 노드는 시작할 때 고유한 ethdb 인스턴스를 생성하며, 이 객체는 프로그램 전체에 걸쳐 존재하며 노드가 종료될 때까지 지속됩니다. 구조 설계에서 이는 core.Blockchain에 주입되어 StateDB, TrieDB 등의 모듈로 전달되며, 전역 공유 데이터 접근 진입점이 됩니다.
ethdb가 저수준 데이터베이스 세부 사항을 추상화했기 때문에 Geth의 다른 구성 요소는 각자의 비즈니스 논리에 집중할 수 있습니다. 예를 들어:
StateDB는 계좌 및 저장 슬롯에만 관심이 있습니다.TrieDB는 Trie 노드를 저장하고 검색하는 방법에만 관심이 있습니다.rawdb는 체인 데이터의 키-값 레이아웃을 조직하는 방법에만 관심이 있습니다.
이러한 상위 구성 요소는 데이터가 어떤 구체적인 데이터베이스 엔진에 저장되어 있는지 인식할 필요가 없습니다.
3. 여섯 가지 DB의 생성 순서 및 호출 체인
이 섹션에서는 Geth 노드 시작부터 이 6종 DB의 시작 프로세스 및 호출 관계를 정리합니다.
3.1 생성 순서:
전체 생성 순서는 ethdb → rawdb/TrieDB → state.Database → stateDB → trie이며, 소스 코드에서의 구체적인 호출 체인은 다음과 같습니다:
【노드 초기화 단계】
MakeChain
└── MakeChainDatabase
└── node.OpenDatabaseWithFreezer
└── node.openDatabase
└── node.openKeyValueDatabase
└── newPebbleDBDatabase / remotedb
↓
ethdb.Database
↓
rawdb.Database (ethdb 캡슐화)
└── rawdb.NewDatabaseWithFreezer(ethdb)
↓
trie.Database (TrieDB)
└── trie.NewDatabase(ethdb)
└── backend: pathdb.New(ethdb) / hashdb.New(ethdb)
↓
state.Database (cachingDB)
└── state.NewDatabase(trieDB)
↓
【블록 처리 단계】
chain.InsertChain
└── bc.insertChain
└── state.New(root, state.Database)
↓
state.StateDB
└── stateDB.OpenTrie()
└── stateDB.OpenStorageTrie()
↓
trie.Trie / SecureTrie
3.2 생명 주기 개요
| DB 모듈 | 생성 시점 | 생명 주기 | 주요 책임 |
|--------------------|------------------------|------------|------------------------------------------|
| ethdb.Database | 노드 초기화 | 프로그램 전체 | 저수준 저장 추상화, 통일된 인터페이스 (LevelDB / PebbleDB / Memory) |
| rawdb | ethdb 호출 캡슐화 | 데이터 자체를 저장하지 않음 | 블록/영수증/총 난이도 등 체인 데이터의 읽기 및 쓰기 인터페이스 제공 |
| TrieDB | core.NewBlockChain() | 프로그램 전체 | PathDB/HashDB 노드의 캐시 및 지속화 |
| state.Database | core.NewBlockChain() | 프로그램 전체 | TrieDB 캡슐화, 계약 코드 캐시, 후에 Verkle 마이그레이션 지원 |
| state.StateDB | 각 블록 실행 전 한 번 생성 | 블록 실행 기간 | 상태 읽기 및 쓰기 관리, 상태 루트 계산, 상태 변경 기록 |
| trie.Trie | 각 계좌 또는 슬롯 접근 시 생성 | 임시, 데이터 자체를 저장하지 않음 | Trie 구조 수정 및 루트 해시 계산 |
4. HashDB 및 PathDB 상태 제출 및 읽기 메커니즘 상세 비교
블록 실행이 완료된 후 StateDB는 func (s ***StateDB**) **Commit**(block uint64, deleteEmptyObjects bool, noStorageWiping bool)를 호출하고, 다음과 같은 저장 상태 업데이트를 트리거합니다:
ret, err := s.**commit**(deleteEmptyObjects, noStorageWiping)를 통해 Trie 상태 트리에 관련된 모든 업데이트를 수집합니다.
func (s *StateDB) commit(deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
…
newroot, set := s.trie.Commit(true)
root = newroot
…
}
여기서 호출되는
trie.Commit메서드는 모든 노드(짧은 노드 및 전체 노드 포함)를 해시 노드로 축소t.root = **newCommitter**(nodes, t.tracer, collectLeaf).**Commit**(t.root, t.uncommitted > 100)하여 모든 더러운 노드를 수집하여 StateDB에 반환합니다.StateDB는 수집된 모든 더러운 노드를 사용하여 TrieDB 캐시 계층을 업데이트합니다:
HashDB는 메모리 내에서dirties map[**common**.**Hash**]***cachedNode**객체를 유지하여 이러한 업데이트를 캐시하고, 해당하는 trie 노드 참조를 업데이트합니다. 캐시에는 크기 제한이 있습니다.PathDB는 메모리 내에서tree ***layerTree**객체를 유지하고, 이러한 업데이트를 캐시하기 위해 한 층의 diff를 추가합니다. 최대 128층의 diff를 캐시할 수 있습니다.
func (s *StateDB) commitAndFlush(block uint64, deleteEmptyObjects bool, noStorageWiping bool) (*stateUpdate, error) {
…
// Trie 데이터베이스가 활성화된 경우, 상태 업데이트를 새로운 레이어로 커밋
if db := s.db.TrieDB(); db != nil {
start := time.Now()
if err := db.Update(ret.root, ret.originRoot, block, ret.nodes, ret.stateSet()); err != nil {
return nil, err
}
s.TrieDBCommits += time.Since(start)
}
…
HashDB또는PathDB캐시가 한계를 초과하면,rawdb가 제공하는 관련 인터페이스를 통해 캐시를ethdb의 실제 지속 계층에 기록하는 플러시가 트리거됩니다:전체 노드
HashDB모드에서는 키가 해시이므로, 동일한 계좌가 수정되면, 저수준 데이터베이스가 키를 통해 동일한 계좌인지 감지할 수 없으므로, 해당 키 및 그에 해당하는 값을 쉽게 삭제할 수 없습니다. 그렇지 않으면 다른 계좌 상태에 영향을 미칠 수 있습니다. 따라서 새로 수정된 KV만 DB에 기록되고, 이전 상태를 삭제할 수 없습니다. 예를 들어 두 개의 서로 다른 계약 주소 A와 B가 실제로 동일한 계약 코드를 저장하고 있다면, 그들은HashDB에서 동일한 (키는 해시, 값은 계약 코드)의 저장소를 공유합니다. EVM 실행 후 계약 A가 파괴되면, 계약 B의 코드와 계약 A의 코드는 데이터베이스에서 동일한 키를 가지므로, 데이터베이스에서 해시가 키인 값을 임의로 삭제할 수 없습니다. 그렇지 않으면 B 계약이 이후에 해당 계약 코드를 읽을 수 없게 됩니다.전체 노드
PathDB모드에서는 키가 경로이므로, 동일한 계좌가 저수준 DB에 해당하는 키가 동일하게 되어, 동일한 계좌에 해당하는 상태를 덮어쓸 수 있습니다. 따라서 전체 노드 상태를 더 쉽게 잘라낼 수 있습니다. 현재 Geth의 전체 노드는 기본적으로PathDB모드를 사용합니다.아카이브(archive) 노드는 각 블록에 해당하는 상태를 저장해야 하므로, 이때
HashDB가 더 유리합니다. 왜냐하면 서로 다른 블록에서 많은 계좌의 데이터가 실제로 수정되지 않았기 때문에, 해시를 키로 사용하는 것은 자동으로 가지치기 특성을 갖게 되기 때문입니다. 이때PathDB는 각 블록에서 모든 계좌의 상태를 저장해야 하므로 상태가 매우 커지게 됩니다. 따라서 Geth의 아카이브 노드는HashDB모드만 지원합니다.
예시: 전체 노드에서 HashDB와 PathDB의 실제 기록 비교
왼쪽의 Trie는 MPT의 초기 상태이며, 빨간색은 수정될 노드를 나타냅니다. 오른쪽은 MPT의 새로운 상태로, 녹색은 이전의 4개 빨간색 노드가 수정된 것을 나타냅니다.

HashDB 모드에서는 C/D/E 노드가 변경된 후 해시가 반드시 변경되므로, C/D/E 노드에 해당하는 세 개의 계좌가 이전에 이미 디스크에 기록되었더라도, 이 세 개의 계좌에 해당하는 새로운 노드 C'/D'/E'는 여전히 기록되어야 하며, 일단 지속화된 후에는 이러한 이전 노드를 삭제하기가 매우 어렵습니다. 디스크 업데이트 이전(왼쪽 그림)과 이후(오른쪽 그림)의 상태는 다음과 같습니다. 여기서 collapsed Node는 노드가 저장하는 값을 간단히 이해할 수 있습니다.

PathDB 모드에서는 C/D/E 노드에 해당하는 값이 변경되었지만, 저수준 저장소의 키(경로)가 변하지 않기 때문에, 지속화 시 이 세 개의 노드에 해당하는 값을 C'/D'/E'로 직접 교체할 수 있습니다. 디스크 데이터는 과도한 중복이 발생하지 않습니다(비록 동일한 계약이 서로 다른 경로에서 저장될 수 있지만, 큰 영향은 없습니다). 디스크 업데이트 이전(왼쪽 그림)과 이후(오른쪽 그림)의 상태는 다음과 같습니다.

예시: HashDB와 PathDB의 계좌 읽기 비교
core/rawdb/accessors_trie.go에 다음과 같은 디버그 코드를 추가하여 stateDB가 0xB3329fcd12C175A236a02eC352044CE44d (계좌 해시:0x**aea7c67d**a6a9bdb230dd07d0e96626e5e57c9cba04dc8039c923baefe55eacd1)를 읽을 때 관련된 Trie 노드 데이터베이스 읽기를 테스트합니다:
func ReadAccountTrieNode(db ethdb.KeyValueReader, path []byte) []byte {
fmt.Println("PathDB read:", hexutil.Encode(accountTrieNodeKey(path)))
data, _ := db.Get(accountTrieNodeKey(path))
return data
}
func ReadLegacyTrieNode(db ethdb.KeyValueReader, hash common.Hash) []byte {
fmt.Println("HashDB read:", hash)
data, err := db.Get(hash.Bytes())
if err != nil {
return nil
}
return data
}
PathDB에서 읽은 Trie 노드는 다음과 같으며, 계좌 주소 해시의 앞 8비트에 해당하는 경로의 노드를 읽은 것을 알 수 있습니다:
0x41은 접두사이며, 추가된 0은 nibbles(반 바이트)의 정렬 필요성입니다.
PathDB read: 0x410a
PathDB read: 0x410a0e
PathDB read: 0x410a0e0a
PathDB read: 0x410a0e0a07
PathDB read: 0x410a0e0a070c
PathDB read: 0x410a0e0a070c06
PathDB read: 0x410a0e0a070c0607
PathDB read: 0x410a0e0a070c06070d
HashDB에서 읽은 Trie 노드는 다음과 같으며, 해시가 키에 해당하는 노드를 읽은 것을 알 수 있습니다:
HashDB read: 0xb01e32b0c38555bb27f1a924b8408824f97dd8d70f096b218d397906a9095385
HashDB read: 0x99d38ce254e6c35a49504345a30e94b4ea08338279385bae33feaaa11c3a0a00
HashDB read: 0xfcc42d902aa9107b83ee7839a8bc61b370cc5eac9ee60db1af7165daf6c3f76b
HashDB read: 0x3232bc99a88337d2aea2e8c237eb5b4ebb9366ff5bdd94b965ac6f918bd6303f
HashDB read: 0x04ae6f0462f6c0c7e5827dc46fcd69329483d829c39f624744f7b55c09c2cc96
HashDB read: 0x22a16c466cc420e8ed97fd484cecc8f73160ee74a56cfc87ff941d1b56ff46f8
HashDB read: 0xae26238e219065458f314e456265cd9c935e829ba82aebe6d38bacdbb14582f3
HashDB read: 0xe9ce7770c224e563b0c407618b7b7d8614da3d5da89f3960a3bec97e78fc0ae0
HashDB read: 0x2c7d134997a5c3e0bf47ff347479ee9318826f1c58689b3d9caeac77287c3af8
전반적으로 PathDB와 HashDB는 상태 데이터를 저장하기 위해 Trie 데이터 구조를 유지하고 있으며, PathDB는 Trie 노드의 path를 키로 사용하고, HashDB는 Trie 노드 값에 해당하는 해시를 키로 사용합니다. 두 경우 모두 저장 값은 동일하며 Trie 노드의 값입니다.
5. DB 관련 읽기 및 쓰기 작업 흐름 추적
1. 거래 실행 단계
모든 계좌 및 저장 값은
StateDB.GetState등의 메서드를 통해Trie→TrieDB(pathdb/hashdb)→RawDB→Level/PebbleDB로 읽혀 StateDB 메모리에 로드됩니다.이후 EVM은 상태 변경을 실행하며(예:
Statedb.SetBalance()호출), 이 또한 StateDB의 메모리에 보존됩니다.여기에는 잔액 변경, nonce 업데이트, 저장소 수정이 포함됩니다.
2. 단일 블록 실행 완료 후 캐시 업데이트
StateDB.Commit()호출 → 더러운 노드를 수집하여 수정된 Trie 노드 그룹으로 변환하고 새로운 StateRoot를 계산합니다.내부적으로
Trie.Commit()호출 →TrieDB.Update()를 호출하여 변경 사항을 TrieDB 캐시 계층에 저장합니다.PathDB는 최대 128개의 블록의 diff 캐시 계층 제한이 있습니다.
HashDB의 캐시 계층에도 크기 제한이 있습니다.
위의 제한을 초과하면
TrieDB.Commit이 실제로 저수준 데이터베이스에 기록됩니다.
3. 단일 블록 실행 완료 후 헤더/영수증 제출:
*
- 상태 외에도 블록 헤더, 본문, 거래 영수증 등의 데이터는
RawDB.Write*(ethdb)등의 인터페이스를 통해ethdb계층에 기록됩니다.
4. 여러 블록 실행 후 캐시 초과 시 실제로 TrieDB.Commit → batch → DB에 기록:
*
- 노드가 아카이브 노드이거나, 플러시 간격을 초과하거나, TrieDB의 캐시 제한을 초과하거나, 노드가 종료되기 전에 커밋이 트리거되어 최종적으로 기록됩니다. 다음은
PathDB모드에서 기록의 핵심 코드입니다:
func (db *Database) commit(hash common.Hash, batch ethdb.Batch, uncacher *cleaner) error {
…
rawdb.WriteLegacyTrieNode(batch, hash, node.node) // 여러 수정된 trie 노드를 배치에 추가 (미기록)
if batch.ValueSize() >= ethdb.IdealBatchSize { // IdealBatchSize에 도달하면 기록 트리거
batch.Write() // 기록
batch.Replay(uncacher) // uncacher에게 메모리 정리를 알림
batch.Reset() // 배치 초기화
}
…
6. 요약
Geth의 이 6개 데이터베이스 모듈은 각기 다른 계층의 책임을 지며, 아래에서 위로 데이터 접근 체인을 형성합니다. 다층 추상화 및 다단계 캐싱을 통해 상위 모듈은 저수준의 구체적인 구현에 대해 신경 쓸 필요가 없으며, 이를 통해 저수준 저장 엔진의 플러그 가능성과 높은 I/O 성능을 실현합니다.
가장 저수준의 ethdb는 물리 저장을 추상화하고, 구체적인 데이터베이스 유형을 숨기며, LevelDB, Pebble, RemoteDB 등 다양한 백엔드를 지원합니다. 그 위의 계층은 rawdb로, 블록, 블록 헤더, 거래 등의 핵심 체인 데이터 구조의 인코딩, 디코딩 및 캡슐화를 담당하여 체인 데이터의 읽기 및 쓰기 작업을 간소화합니다. TrieDB는 상태 트리 노드의 캐시 및 지속화를 관리하며, hashdb 및 pathdb 두 가지 백엔드를 통해 서로 다른 상태 가지치기 전략 및 저장 방식을 구현합니다.
그보다 위의 계층인 trie.Trie는 상태 변화의 실행 컨테이너 및 루트 해시 계산의 핵심으로, 실제 상태 구축 및 탐색 작업을 수행합니다. state.Database는 계좌 및 계약 저장 Trie에 대한 통합 접근을 캡슐화하고, 계약 코드 캐시를 제공합니다. 가장 상위의 state.StateDB는 블록 실행 과정에서 EVM과 연결되는 인터페이스로, 계좌 및 저장소의 읽기 캐시 및 쓰기 지원을 제공하여 EVM이 저수준 Trie의 복잡한 구조를 인식할 필요가 없도록 합니다.
이러한 모듈은 책임 분리 및 인터페이스 격리를 통해 협력하여 유연하고 효율적인 상태 관리 시스템을 구축하여 Geth가 복잡한 체인 상태 및 거래 실행에서 우수한 성능과 유지 관리를 유지할 수 있도록 합니다.
참고문헌
[2]5개의 DB 이야기
[3]경로 기반 저장소 및 인라인 가지치기 - NodeReal
[4]RLP 인코딩 규격
 위험 경고 위험 경고
위험 경고 위험 경고